 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebacpipe: a Python package to make bioacoustic deep learning models accessible
Apr 13, 20261. Natural sounds have been recorded for millions of hours over the previous decades using passive acoustic monitoring. Improvements in deep learning models have vastly accelerated the analysis of large portions of this data. While new models advance the state-of-the-art, accessing them using tools to harness their full potential is not always straightforward. Here we present bacpipe, a collection of bioacoustic deep learning models and evaluation pipelines accessible through a graphical and programming interface, designed for both ecologists and computer scientists. Bacpipe is a modular software package intended as a point of convergence for bioacoustic models. 2. Bacpipe streamlines the usage of state-of-the-art models on custom audio datasets, generating acoustic feature vectors (embeddings) and classifier predictions. A modular design allows evaluation and benchmarking of models through interactive visualizations, clustering and probing. 3. We believe that access to new deep learning models is important. By designing bacpipe to target a wide audience, researchers will be enabled to answer new ecological and evolutionary questions in bioacoustics. 4. In conclusion, we believe accessibility to developments in deep learning to a wider audience benefits the ecological questions we are trying to answer.
Torus embeddings
Mar 03, 2026Many data representations are vectors of continuous values. In particular, deep learning embeddings are data-driven representations, typically either unconstrained in Euclidean space, or constrained to a hypersphere. These may also be translated into integer representations (quantised) for efficient large-scale use. However, the fundamental (and most efficient) numeric representation in the overwhelming majority of existing computers is integers with overflow -- and vectors of these integers do not correspond to either of these spaces, but instead to the topology of a (hyper)torus. This mismatch can lead to wasted representation capacity. Here we show that common deep learning frameworks can be adapted, quite simply, to create representations with inherent toroidal topology. We investigate two alternative strategies, demonstrating that a normalisation-based strategy leads to training with desirable stability and performance properties, comparable to a standard hyperspherical L2 normalisation. We also demonstrate that a torus embedding maintains desirable quantisation properties. The torus embedding does not outperform hypersphere embeddings in general, but is comparable, and opens the possibility to train deep embeddings which have an extremely simple pathway to efficient `TinyML' embedded implementation.
Clustering and novel class recognition: evaluating bioacoustic deep learning feature extractors
Apr 09, 2025



In computational bioacoustics, deep learning models are composed of feature extractors and classifiers. The feature extractors generate vector representations of the input sound segments, called embeddings, which can be input to a classifier. While benchmarking of classification scores provides insights into specific performance statistics, it is limited to species that are included in the models' training data. Furthermore, it makes it impossible to compare models trained on very different taxonomic groups. This paper aims to address this gap by analyzing the embeddings generated by the feature extractors of 15 bioacoustic models spanning a wide range of setups (model architectures, training data, training paradigms). We evaluated and compared different ways in which models structure embedding spaces through clustering and kNN classification, which allows us to focus our comparison on feature extractors independent of their classifiers. We believe that this approach lets us evaluate the adaptability and generalization potential of models going beyond the classes they were trained on.
InsectSet459: an open dataset of insect sounds for bioacoustic machine learning
Mar 19, 2025Automatic recognition of insect sound could help us understand changing biodiversity trends around the world -- but insect sounds are challenging to recognize even for deep learning. We present a new dataset comprised of 26399 audio files, from 459 species of Orthoptera and Cicadidae. It is the first large-scale dataset of insect sound that is easily applicable for developing novel deep-learning methods. Its recordings were made with a variety of audio recorders using varying sample rates to capture the extremely broad range of frequencies that insects produce. We benchmark performance with two state-of-the-art deep learning classifiers, demonstrating good performance but also significant room for improvement in acoustic insect classification. This dataset can serve as a realistic test case for implementing insect monitoring workflows, and as a challenging basis for the development of audio representation methods that can handle highly variable frequencies and/or sample rates.
Enhanced Load Forecasting with GAT-LSTM: Leveraging Grid and Temporal Features
Feb 12, 2025



Accurate power load forecasting is essential for the efficient operation and planning of electrical grids, particularly given the increased variability and complexity introduced by renewable energy sources. This paper introduces GAT-LSTM, a hybrid model that combines Graph Attention Networks (GAT) and Long Short-Term Memory (LSTM) networks. A key innovation of the model is the incorporation of edge attributes, such as line capacities and efficiencies, into the attention mechanism, enabling it to dynamically capture spatial relationships grounded in grid-specific physical and operational constraints. Additionally, by employing an early fusion of spatial graph embeddings and temporal sequence features, the model effectively learns and predicts complex interactions between spatial dependencies and temporal patterns, providing a realistic representation of the dynamics of power grids. Experimental evaluations on the Brazilian Electricity System dataset demonstrate that the GAT-LSTM model significantly outperforms state-of-the-art models, achieving reductions of 21. 8% in MAE, 15. 9% in RMSE and 20. 2% in MAPE. These results underscore the robustness and adaptability of the GAT-LSTM model, establishing it as a powerful tool for applications in grid management and energy planning.
LHGNN: Local-Higher Order Graph Neural Networks For Audio Classification and Tagging
Jan 07, 2025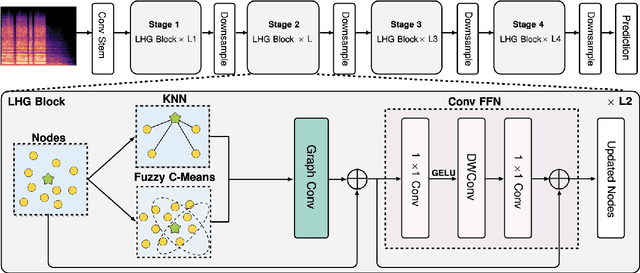



Transformers have set new benchmarks in audio processing tasks, leveraging self-attention mechanisms to capture complex patterns and dependencies within audio data. However, their focus on pairwise interactions limits their ability to process the higher-order relations essential for identifying distinct audio objects. To address this limitation, this work introduces the Local- Higher Order Graph Neural Network (LHGNN), a graph based model that enhances feature understanding by integrating local neighbourhood information with higher-order data from Fuzzy C-Means clusters, thereby capturing a broader spectrum of audio relationships. Evaluation of the model on three publicly available audio datasets shows that it outperforms Transformer-based models across all benchmarks while operating with substantially fewer parameters. Moreover, LHGNN demonstrates a distinct advantage in scenarios lacking ImageNet pretraining, establishing its effectiveness and efficiency in environments where extensive pretraining data is unavailable.
Generalization in birdsong classification: impact of transfer learning methods and dataset characteristics
Sep 21, 2024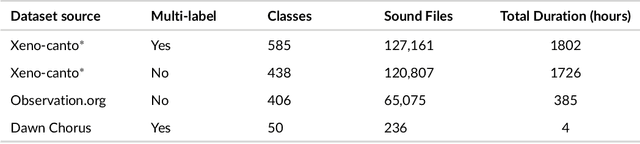
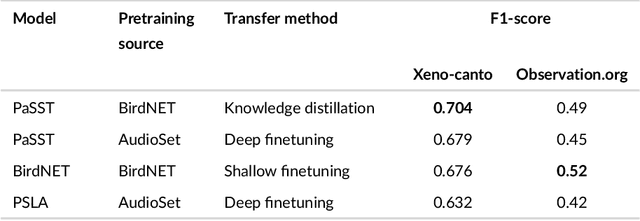

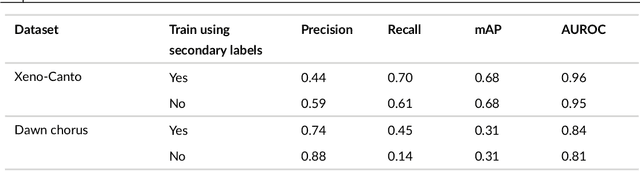
Animal sounds can be recognised automatically by machine learning, and this has an important role to play in biodiversity monitoring. Yet despite increasingly impressive capabilities, bioacoustic species classifiers still exhibit imbalanced performance across species and habitats, especially in complex soundscapes. In this study, we explore the effectiveness of transfer learning in large-scale bird sound classification across various conditions, including single- and multi-label scenarios, and across different model architectures such as CNNs and Transformers. Our experiments demonstrate that both fine-tuning and knowledge distillation yield strong performance, with cross-distillation proving particularly effective in improving in-domain performance on Xeno-canto data. However, when generalizing to soundscapes, shallow fine-tuning exhibits superior performance compared to knowledge distillation, highlighting its robustness and constrained nature. Our study further investigates how to use multi-species labels, in cases where these are present but incomplete. We advocate for more comprehensive labeling practices within the animal sound community, including annotating background species and providing temporal details, to enhance the training of robust bird sound classifiers. These findings provide insights into the optimal reuse of pretrained models for advancing automatic bioacoustic recognition.
Acoustic identification of individual animals with hierarchical contrastive learning
Sep 13, 2024



Acoustic identification of individual animals (AIID) is closely related to audio-based species classification but requires a finer level of detail to distinguish between individual animals within the same species. In this work, we frame AIID as a hierarchical multi-label classification task and propose the use of hierarchy-aware loss functions to learn robust representations of individual identities that maintain the hierarchical relationships among species and taxa. Our results demonstrate that hierarchical embeddings not only enhance identification accuracy at the individual level but also at higher taxonomic levels, effectively preserving the hierarchical structure in the learned representations. By comparing our approach with non-hierarchical models, we highlight the advantage of enforcing this structure in the embedding space. Additionally, we extend the evaluation to the classification of novel individual classes, demonstrating the potential of our method in open-set classification scenarios.
animal2vec and MeerKAT: A self-supervised transformer for rare-event raw audio input and a large-scale reference dataset for bioacoustics
Jun 03, 2024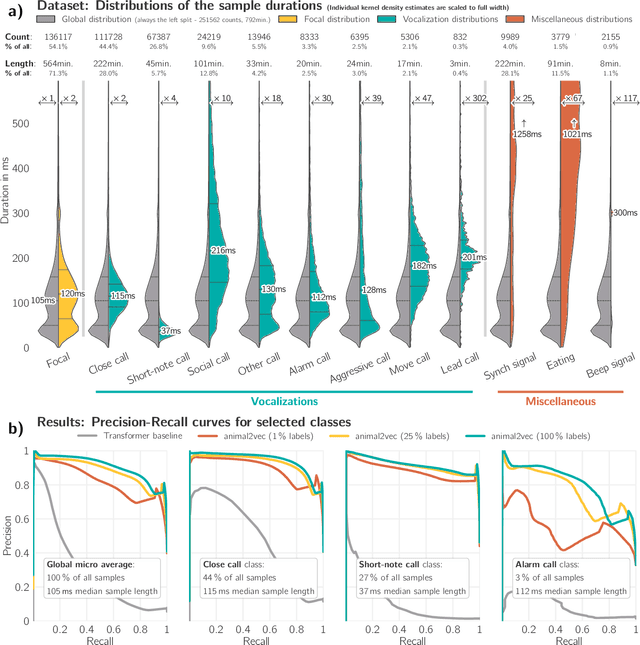

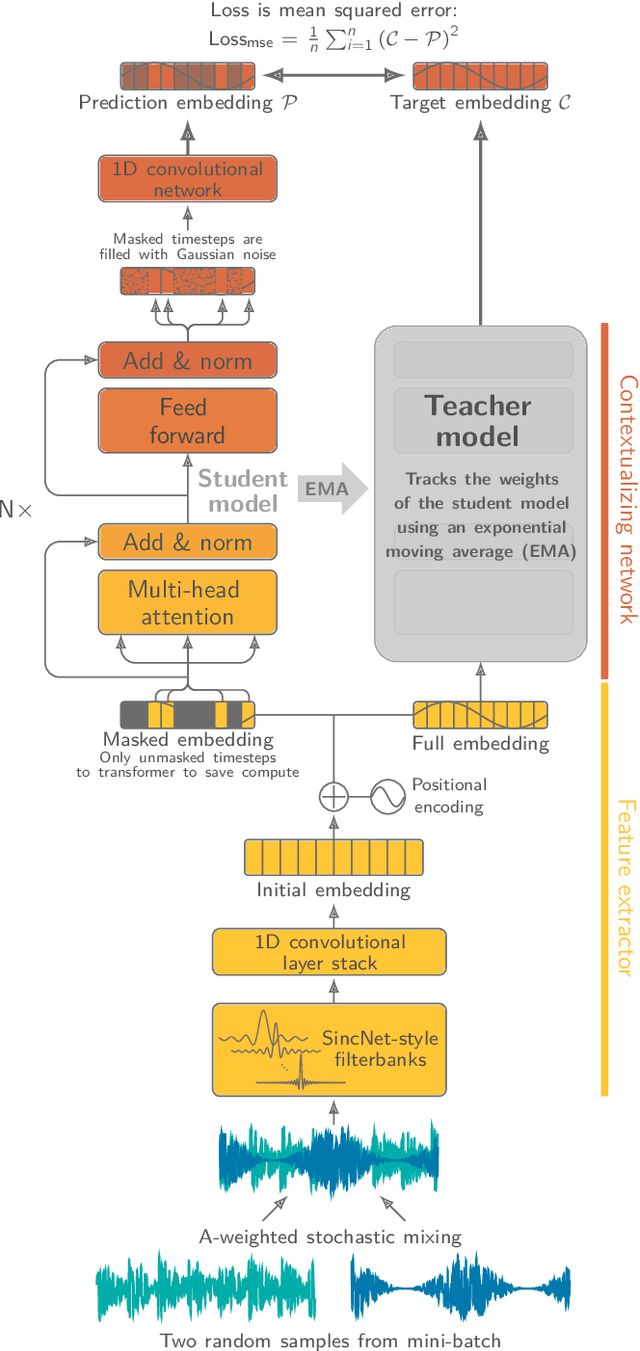
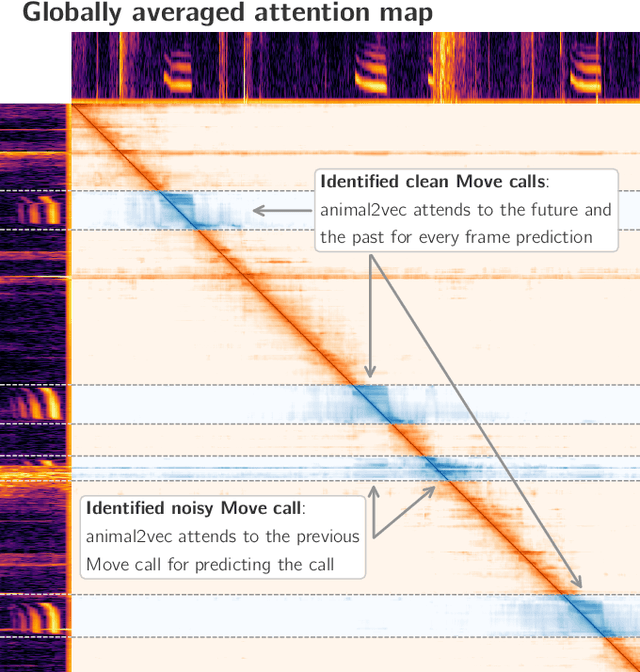
Bioacoustic research provides invaluable insights into the behavior, ecology, and conservation of animals. Most bioacoustic datasets consist of long recordings where events of interest, such as vocalizations, are exceedingly rare. Analyzing these datasets poses a monumental challenge to researchers, where deep learning techniques have emerged as a standard method. Their adaptation remains challenging, focusing on models conceived for computer vision, where the audio waveforms are engineered into spectrographic representations for training and inference. We improve the current state of deep learning in bioacoustics in two ways: First, we present the animal2vec framework: a fully interpretable transformer model and self-supervised training scheme tailored for sparse and unbalanced bioacoustic data. Second, we openly publish MeerKAT: Meerkat Kalahari Audio Transcripts, a large-scale dataset containing audio collected via biologgers deployed on free-ranging meerkats with a length of over 1068h, of which 184h have twelve time-resolved vocalization-type classes, each with ms-resolution, making it the largest publicly-available labeled dataset on terrestrial mammals. Further, we benchmark animal2vec against the NIPS4Bplus birdsong dataset. We report new state-of-the-art results on both datasets and evaluate the few-shot capabilities of animal2vec of labeled training data. Finally, we perform ablation studies to highlight the differences between our architecture and a vanilla transformer baseline for human-produced sounds. animal2vec allows researchers to classify massive amounts of sparse bioacoustic data even with little ground truth information available. In addition, the MeerKAT dataset is the first large-scale, millisecond-resolution corpus for benchmarking bioacoustic models in the pretrain/finetune paradigm. We believe this sets the stage for a new reference point for bioacoustics.
Performance of computer vision algorithms for fine-grained classification using crowdsourced insect images
Apr 04, 2024
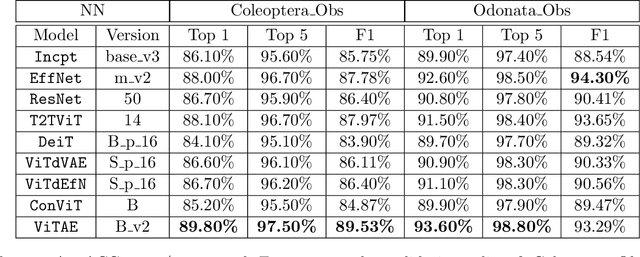

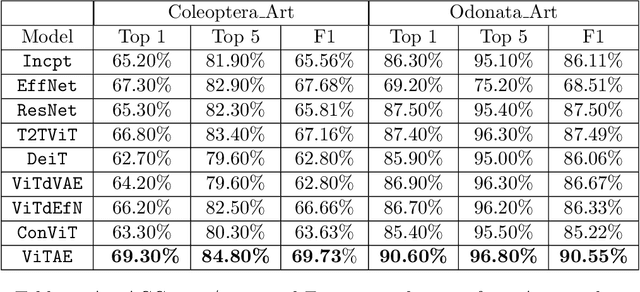
With fine-grained classification, we identify unique characteristics to distinguish among classes of the same super-class. We are focusing on species recognition in Insecta, as they are critical for biodiversity monitoring and at the base of many ecosystems. With citizen science campaigns, billions of images are collected in the wild. Once these are labelled, experts can use them to create distribution maps. However, the labelling process is time-consuming, which is where computer vision comes in. The field of computer vision offers a wide range of algorithms, each with its strengths and weaknesses; how do we identify the algorithm that is in line with our application? To answer this question, we provide a full and detailed evaluation of nine algorithms among deep convolutional networks (CNN), vision transformers (ViT), and locality-based vision transformers (LBVT) on 4 different aspects: classification performance, embedding quality, computational cost, and gradient activity. We offer insights that we haven't yet had in this domain proving to which extent these algorithms solve the fine-grained tasks in Insecta. We found that the ViT performs the best on inference speed and computational cost while the LBVT outperforms the others on performance and embedding quality; the CNN provide a trade-off among the metrics.