 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsectSet459: an open dataset of insect sounds for bioacoustic machine learning
Mar 19, 2025Automatic recognition of insect sound could help us understand changing biodiversity trends around the world -- but insect sounds are challenging to recognize even for deep learning. We present a new dataset comprised of 26399 audio files, from 459 species of Orthoptera and Cicadidae. It is the first large-scale dataset of insect sound that is easily applicable for developing novel deep-learning methods. Its recordings were made with a variety of audio recorders using varying sample rates to capture the extremely broad range of frequencies that insects produce. We benchmark performance with two state-of-the-art deep learning classifiers, demonstrating good performance but also significant room for improvement in acoustic insect classification. This dataset can serve as a realistic test case for implementing insect monitoring workflows, and as a challenging basis for the development of audio representation methods that can handle highly variable frequencies and/or sample rates.
animal2vec and MeerKAT: A self-supervised transformer for rare-event raw audio input and a large-scale reference dataset for bioacoustics
Jun 03, 2024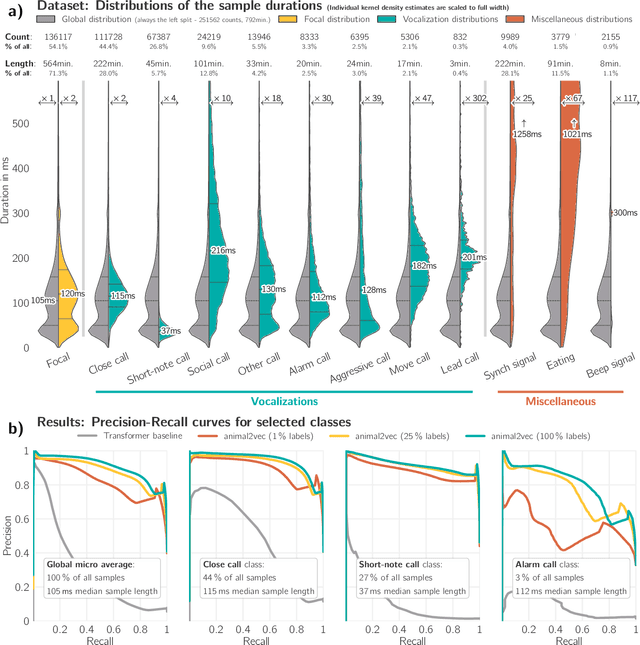

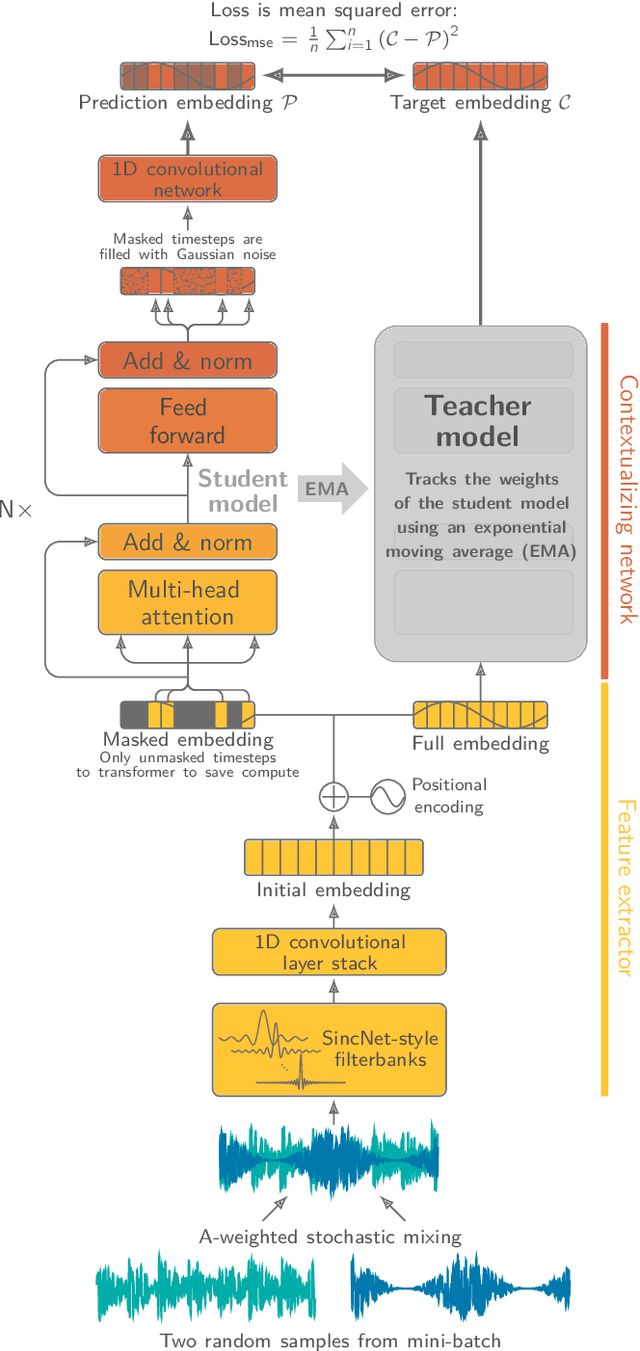
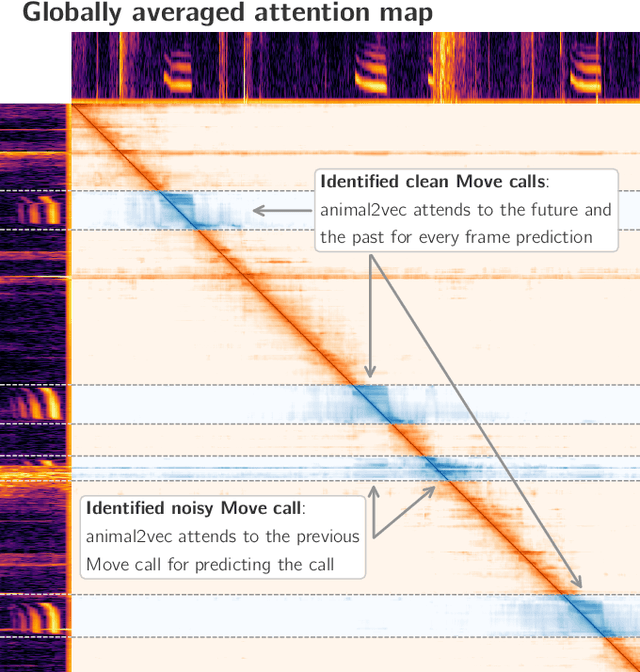
Bioacoustic research provides invaluable insights into the behavior, ecology, and conservation of animals. Most bioacoustic datasets consist of long recordings where events of interest, such as vocalizations, are exceedingly rare. Analyzing these datasets poses a monumental challenge to researchers, where deep learning techniques have emerged as a standard method. Their adaptation remains challenging, focusing on models conceived for computer vision, where the audio waveforms are engineered into spectrographic representations for training and inference. We improve the current state of deep learning in bioacoustics in two ways: First, we present the animal2vec framework: a fully interpretable transformer model and self-supervised training scheme tailored for sparse and unbalanced bioacoustic data. Second, we openly publish MeerKAT: Meerkat Kalahari Audio Transcripts, a large-scale dataset containing audio collected via biologgers deployed on free-ranging meerkats with a length of over 1068h, of which 184h have twelve time-resolved vocalization-type classes, each with ms-resolution, making it the largest publicly-available labeled dataset on terrestrial mammals. Further, we benchmark animal2vec against the NIPS4Bplus birdsong dataset. We report new state-of-the-art results on both datasets and evaluate the few-shot capabilities of animal2vec of labeled training data. Finally, we perform ablation studies to highlight the differences between our architecture and a vanilla transformer baseline for human-produced sounds. animal2vec allows researchers to classify massive amounts of sparse bioacoustic data even with little ground truth information available. In addition, the MeerKAT dataset is the first large-scale, millisecond-resolution corpus for benchmarking bioacoustic models in the pretrain/finetune paradigm. We believe this sets the stage for a new reference point for bioacoustics.
Adaptive Representations of Sound for Automatic Insect Recognition
Apr 25, 2023Insect population numbers and biodiversity have been rapidly declining with time, and monitoring these trends has become increasingly important for conservation measures to be effectively implemented. But monitoring methods are often invasive, time and resource intense, and prone to various biases. Many insect species produce characteristic sounds that can easily be detected and recorded without large cost or effort. Using deep learning methods, insect sounds from field recordings could be automatically detected and classified to monitor biodiversity and species distribution ranges. We implement this using recently published datasets of insect sounds (Orthoptera and Cicadidae) and machine learning methods and evaluate their potential for acoustic insect monitoring. We compare the performance of the conventional spectrogram-based audio representation against LEAF, a new adaptive and waveform-based frontend. LEAF achieved better classification performance than the mel-spectrogram frontend by adapting its feature extraction parameters during training. This result is encouraging for future implementations of deep learning technology for automatic insect sound recognition, especially as larger datasets become available.