 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
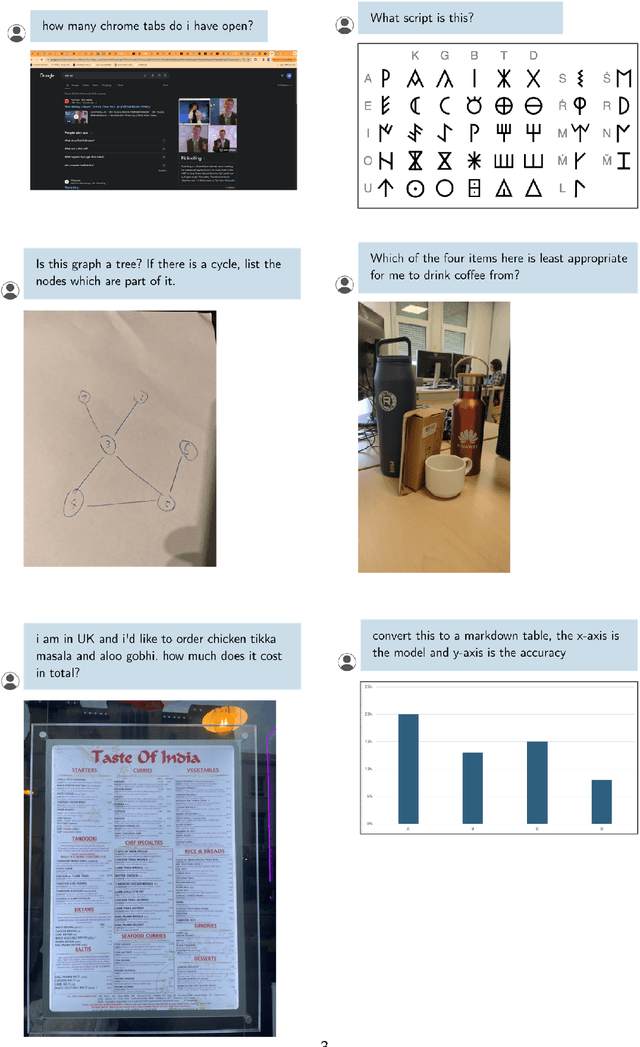
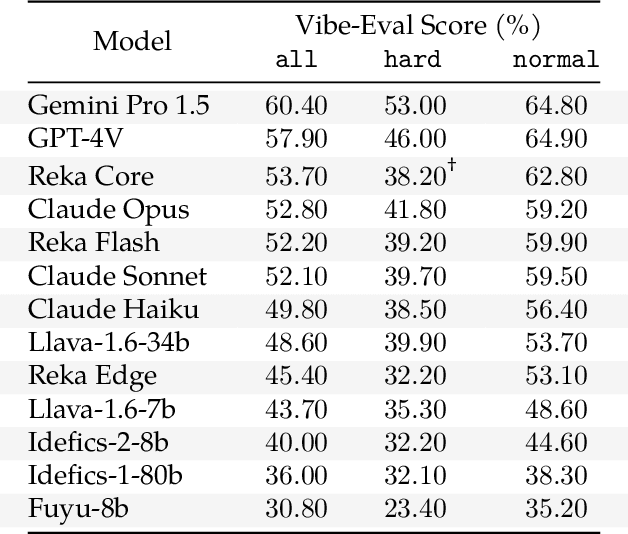
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024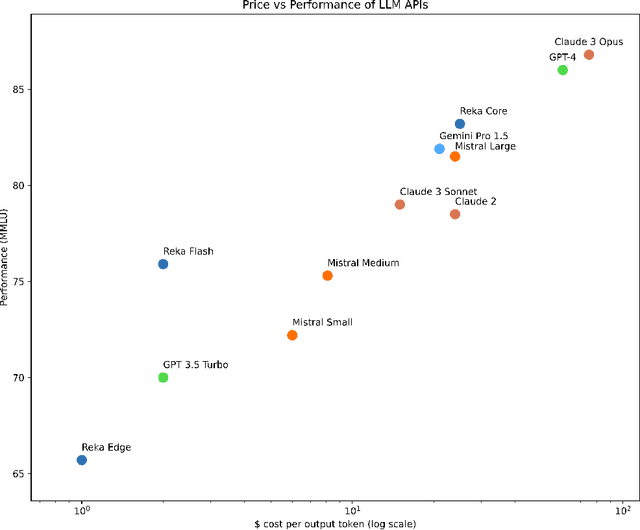


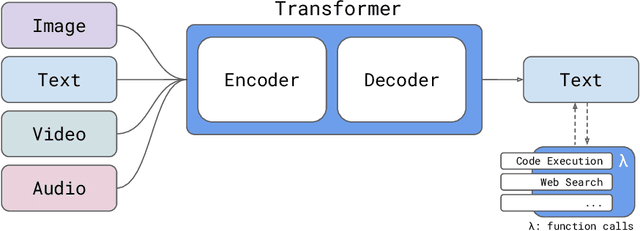
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
WavJourney: Compositional Audio Creation with Large Language Models
Jul 26, 2023Large Language Models (LLMs) have shown great promise in integrating diverse expert models to tackle intricate language and vision tasks. Despite their significance in advancing the field of Artificial Intelligence Generated Content (AIGC), their potential in intelligent audio content creation remains unexplored. In this work, we tackle the problem of creating audio content with storylines encompassing speech, music, and sound effects, guided by text instructions. We present WavJourney, a system that leverages LLMs to connect various audio models for audio content generation. Given a text description of an auditory scene, WavJourney first prompts LLMs to generate a structured script dedicated to audio storytelling. The audio script incorporates diverse audio elements, organized based on their spatio-temporal relationships. As a conceptual representation of audio, the audio script provides an interactive and interpretable rationale for human engagement. Afterward, the audio script is fed into a script compiler, converting it into a computer program. Each line of the program calls a task-specific audio generation model or computational operation function (e.g., concatenate, mix). The computer program is then executed to obtain an explainable solution for audio generation. We demonstrate the practicality of WavJourney across diverse real-world scenarios, including science fiction, education, and radio play. The explainable and interactive design of WavJourney fosters human-machine co-creation in multi-round dialogues, enhancing creative control and adaptability in audio production. WavJourney audiolizes the human imagination, opening up new avenues for creativity in multimedia content creation.