 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture
Apr 21, 2025



Fish Feeding Intensity Assessment (FFIA) is crucial in industrial aquaculture management. Recent multi-modal approaches have shown promise in improving FFIA robustness and efficiency. However, these methods face significant challenges when adapting to new fish species or environments due to catastrophic forgetting and the lack of suitable datasets. To address these limitations, we first introduce AV-CIL-FFIA, a new dataset comprising 81,932 labelled audio-visual clips capturing feeding intensities across six different fish species in real aquaculture environments. Then, we pioneer audio-visual class incremental learning (CIL) for FFIA and demonstrate through benchmarking on AV-CIL-FFIA that it significantly outperforms single-modality methods. Existing CIL methods rely heavily on historical data. Exemplar-based approaches store raw samples, creating storage challenges, while exemplar-free methods avoid data storage but struggle to distinguish subtle feeding intensity variations across different fish species. To overcome these limitations, we introduce HAIL-FFIA, a novel audio-visual class-incremental learning framework that bridges this gap with a prototype-based approach that achieves exemplar-free efficiency while preserving essential knowledge through compact feature representations. Specifically, HAIL-FFIA employs hierarchical representation learning with a dual-path knowledge preservation mechanism that separates general intensity knowledge from fish-specific characteristics. Additionally, it features a dynamic modality balancing system that adaptively adjusts the importance of audio versus visual information based on feeding behaviour stages. Experimental results show that HAIL-FFIA is superior to SOTA methods on AV-CIL-FFIA, achieving higher accuracy with lower storage needs while effectively mitigating catastrophic forgetting in incremental fish species learning.
Fish Tracking, Counting, and Behaviour Analysis in Digital Aquaculture: A Comprehensive Review
Jun 20, 2024Digital aquaculture leverages advanced technologies and data-driven methods, providing substantial benefits over traditional aquaculture practices. Fish tracking, counting, and behaviour analysis are crucial components of digital aquaculture, which are essential for optimizing production efficiency, enhancing fish welfare, and improving resource management. Previous reviews have focused on single modalities, limiting their ability to address the diverse challenges encountered in these tasks comprehensively. This review provides a comprehensive analysis of the current state of aquaculture digital technologies, including vision-based, acoustic-based, and biosensor-based methods. We examine the advantages, limitations, and applications of these methods, highlighting recent advancements and identifying critical research gaps. The scarcity of comprehensive fish datasets and the lack of unified evaluation standards, which make it difficult to compare the performance of different technologies, are identified as major obstacles hindering progress in this field. To overcome current limitations and improve the accuracy, robustness, and efficiency of fish monitoring systems, we explore the potential of emerging technologies such as multimodal data fusion and deep learning. Additionally, we contribute to the field by providing a summary of existing datasets available for fish tracking, counting, and behaviour analysis. Future research directions are outlined, emphasizing the need for comprehensive datasets and evaluation standards to facilitate meaningful comparisons between technologies and promote their practical implementation in real-world aquaculture settings.
Audio-Visual Speaker Tracking: Progress, Challenges, and Future Directions
Oct 23, 2023



Audio-visual speaker tracking has drawn increasing attention over the past few years due to its academic values and wide application. Audio and visual modalities can provide complementary information for localization and tracking. With audio and visual information, the Bayesian-based filter can solve the problem of data association, audio-visual fusion and track management. In this paper, we conduct a comprehensive overview of audio-visual speaker tracking. To our knowledge, this is the first extensive survey over the past five years. We introduce the family of Bayesian filters and summarize the methods for obtaining audio-visual measurements. In addition, the existing trackers and their performance on AV16.3 dataset are summarized. In the past few years, deep learning techniques have thrived, which also boosts the development of audio visual speaker tracking. The influence of deep learning techniques in terms of measurement extraction and state estimation is also discussed. At last, we discuss the connections between audio-visual speaker tracking and other areas such as speech separation and distributed speaker tracking.
Multimodal Fish Feeding Intensity Assessment in Aquaculture
Sep 10, 2023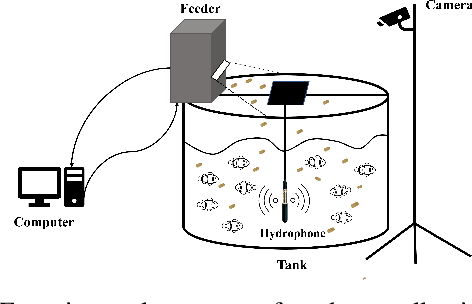
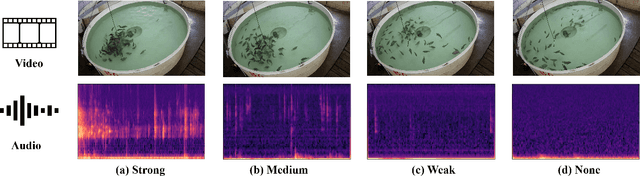
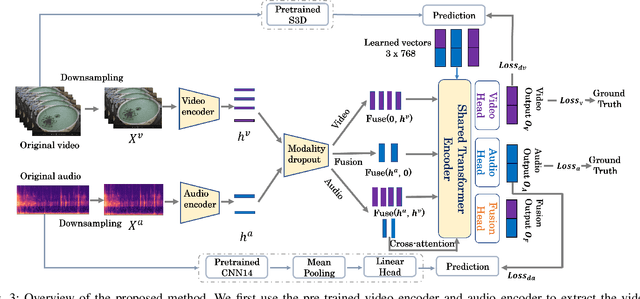

Fish feeding intensity assessment (FFIA) aims to evaluate the intensity change of fish appetite during the feeding process, which is vital in industrial aquaculture applications. The main challenges surrounding FFIA are two-fold. 1) robustness: existing work has mainly leveraged single-modality (e.g., vision, audio) methods, which have a high sensitivity to input noise. 2) efficiency: FFIA models are generally expected to be employed on devices. This presents a challenge in terms of computational efficiency. In this work, we first introduce an audio-visual dataset, called AV-FFIA. AV-FFIA consists of 27,000 labeled audio and video clips that capture different levels of fish feeding intensity. To our knowledge, AV-FFIA is the first large-scale multimodal dataset for FFIA research. Then, we introduce a multi-modal approach for FFIA by leveraging single-modality pre-trained models and modality-fusion methods, with benchmark studies on AV-FFIA. Our experimental results indicate that the multi-modal approach substantially outperforms the single-modality based approach, especially in noisy environments. While multimodal approaches provide a performance gain for FFIA, it inherently increase the computational cost. To overcome this issue, we further present a novel unified model, termed as U-FFIA. U-FFIA is a single model capable of processing audio, visual, or audio-visual modalities, by leveraging modality dropout during training and knowledge distillation from single-modality pre-trained models. We demonstrate that U-FFIA can achieve performance better than or on par with the state-of-the-art modality-specific FFIA models, with significantly lower computational overhead. Our proposed U-FFIA approach enables a more robust and efficient method for FFIA, with the potential to contribute to improved management practices and sustainability in aquaculture.
WavJourney: Compositional Audio Creation with Large Language Models
Jul 26, 2023Large Language Models (LLMs) have shown great promise in integrating diverse expert models to tackle intricate language and vision tasks. Despite their significance in advancing the field of Artificial Intelligence Generated Content (AIGC), their potential in intelligent audio content creation remains unexplored. In this work, we tackle the problem of creating audio content with storylines encompassing speech, music, and sound effects, guided by text instructions. We present WavJourney, a system that leverages LLMs to connect various audio models for audio content generation. Given a text description of an auditory scene, WavJourney first prompts LLMs to generate a structured script dedicated to audio storytelling. The audio script incorporates diverse audio elements, organized based on their spatio-temporal relationships. As a conceptual representation of audio, the audio script provides an interactive and interpretable rationale for human engagement. Afterward, the audio script is fed into a script compiler, converting it into a computer program. Each line of the program calls a task-specific audio generation model or computational operation function (e.g., concatenate, mix). The computer program is then executed to obtain an explainable solution for audio generation. We demonstrate the practicality of WavJourney across diverse real-world scenarios, including science fiction, education, and radio play. The explainable and interactive design of WavJourney fosters human-machine co-creation in multi-round dialogues, enhancing creative control and adaptability in audio production. WavJourney audiolizes the human imagination, opening up new avenues for creativity in multimedia content creation.