 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fish Feeding Intensity Assessment in Aquaculture
Paper and Code
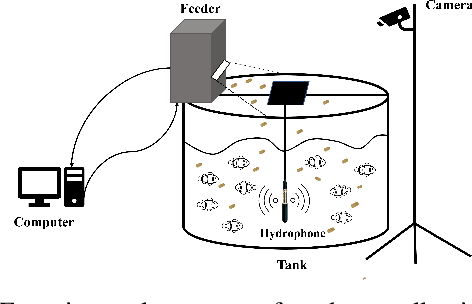
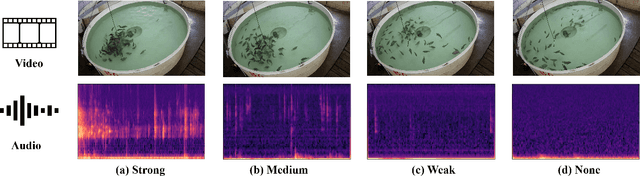
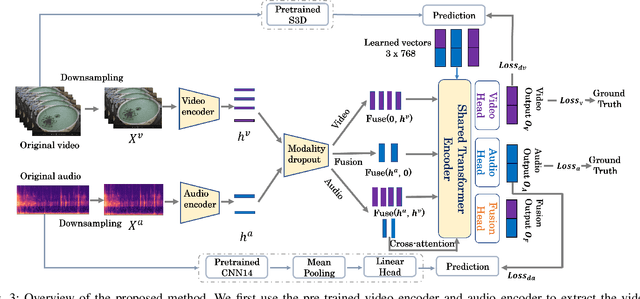

Fish feeding intensity assessment (FFIA) aims to evaluate the intensity change of fish appetite during the feeding process, which is vital in industrial aquaculture applications. The main challenges surrounding FFIA are two-fold. 1) robustness: existing work has mainly leveraged single-modality (e.g., vision, audio) methods, which have a high sensitivity to input noise. 2) efficiency: FFIA models are generally expected to be employed on devices. This presents a challenge in terms of computational efficiency. In this work, we first introduce an audio-visual dataset, called AV-FFIA. AV-FFIA consists of 27,000 labeled audio and video clips that capture different levels of fish feeding intensity. To our knowledge, AV-FFIA is the first large-scale multimodal dataset for FFIA research. Then, we introduce a multi-modal approach for FFIA by leveraging single-modality pre-trained models and modality-fusion methods, with benchmark studies on AV-FFIA. Our experimental results indicate that the multi-modal approach substantially outperforms the single-modality based approach, especially in noisy environments. While multimodal approaches provide a performance gain for FFIA, it inherently increase the computational cost. To overcome this issue, we further present a novel unified model, termed as U-FFIA. U-FFIA is a single model capable of processing audio, visual, or audio-visual modalities, by leveraging modality dropout during training and knowledge distillation from single-modality pre-trained models. We demonstrate that U-FFIA can achieve performance better than or on par with the state-of-the-art modality-specific FFIA models, with significantly lower computational overhead. Our proposed U-FFIA approach enables a more robust and efficient method for FFIA, with the potential to contribute to improved management practices and sustainability in aquaculture.