 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Class-Incremental Learning for Fish Feeding intensity Assessment in Aquaculture
Apr 21, 2025



Fish Feeding Intensity Assessment (FFIA) is crucial in industrial aquaculture management. Recent multi-modal approaches have shown promise in improving FFIA robustness and efficiency. However, these methods face significant challenges when adapting to new fish species or environments due to catastrophic forgetting and the lack of suitable datasets. To address these limitations, we first introduce AV-CIL-FFIA, a new dataset comprising 81,932 labelled audio-visual clips capturing feeding intensities across six different fish species in real aquaculture environments. Then, we pioneer audio-visual class incremental learning (CIL) for FFIA and demonstrate through benchmarking on AV-CIL-FFIA that it significantly outperforms single-modality methods. Existing CIL methods rely heavily on historical data. Exemplar-based approaches store raw samples, creating storage challenges, while exemplar-free methods avoid data storage but struggle to distinguish subtle feeding intensity variations across different fish species. To overcome these limitations, we introduce HAIL-FFIA, a novel audio-visual class-incremental learning framework that bridges this gap with a prototype-based approach that achieves exemplar-free efficiency while preserving essential knowledge through compact feature representations. Specifically, HAIL-FFIA employs hierarchical representation learning with a dual-path knowledge preservation mechanism that separates general intensity knowledge from fish-specific characteristics. Additionally, it features a dynamic modality balancing system that adaptively adjusts the importance of audio versus visual information based on feeding behaviour stages. Experimental results show that HAIL-FFIA is superior to SOTA methods on AV-CIL-FFIA, achieving higher accuracy with lower storage needs while effectively mitigating catastrophic forgetting in incremental fish species learning.
Research advances on fish feeding behavior recognition and intensity quantification methods in aquaculture
Feb 21, 2025



As a key part of aquaculture management, fish feeding behavior recognition and intensity quantification has been a hot area of great concern to researchers, and it plays a crucial role in monitoring fish health, guiding baiting work and improving aquaculture efficiency. In order to better carry out the related work in the future, this paper firstly reviews the research advances of fish feeding behavior recognition and intensity quantification methods based on computer vision, acoustics and sensors in a single modality. Then the application of the current emerging multimodal fusion in fish feeding behavior recognition and intensity quantification methods is expounded. Finally, the advantages and disadvantages of various techniques are compared and analyzed, and the future research directions are envisioned.
PDCFNet: Enhancing Underwater Images through Pixel Difference Convolution
Sep 28, 2024Majority of deep learning methods utilize vanilla convolution for enhancing underwater images. While vanilla convolution excels in capturing local features and learning the spatial hierarchical structure of images, it tends to smooth input images, which can somewhat limit feature expression and modeling. A prominent characteristic of underwater degraded images is blur, and the goal of enhancement is to make the textures and details (high-frequency features) in the images more visible. Therefore, we believe that leveraging high-frequency features can improve enhancement performance. To address this, we introduce Pixel Difference Convolution (PDC), which focuses on gradient information with significant changes in the image, thereby improving the modeling of enhanced images. We propose an underwater image enhancement network, PDCFNet, based on PDC and cross-level feature fusion. Specifically, we design a detail enhancement module based on PDC that employs parallel PDCs to capture high-frequency features, leading to better detail and texture enhancement. The designed cross-level feature fusion module performs operations such as concatenation and multiplication on features from different levels, ensuring sufficient interaction and enhancement between diverse features. Our proposed PDCFNet achieves a PSNR of 27.37 and an SSIM of 92.02 on the UIEB dataset, attaining the best performance to date. Our code is available at https://github.com/zhangsong1213/PDCFNet.
Mamba-UIE: Enhancing Underwater Images with Physical Model Constraint
Jul 27, 2024



In underwater image enhancement (UIE), convolutional neural networks (CNN) have inherent limitations in modeling long-range dependencies and are less effective in recovering global features. While Transformers excel at modeling long-range dependencies, their quadratic computational complexity with increasing image resolution presents significant efficiency challenges. Additionally, most supervised learning methods lack effective physical model constraint, which can lead to insufficient realism and overfitting in generated images. To address these issues, we propose a physical model constraint-based underwater image enhancement framework, Mamba-UIE. Specifically, we decompose the input image into four components: underwater scene radiance, direct transmission map, backscatter transmission map, and global background light. These components are reassembled according to the revised underwater image formation model, and the reconstruction consistency constraint is applied between the reconstructed image and the original image, thereby achieving effective physical constraint on the underwater image enhancement process. To tackle the quadratic computational complexity of Transformers when handling long sequences, we introduce the Mamba-UIE network based on linear complexity state space models (SSM). By incorporating the Mamba in Convolution block, long-range dependencies are modeled at both the channel and spatial levels, while the CNN backbone is retained to recover local features and details. Extensive experiments on three public datasets demonstrate that our proposed Mamba-UIE outperforms existing state-of-the-art methods, achieving a PSNR of 27.13 and an SSIM of 0.93 on the UIEB dataset. Our method is available at https://github.com/zhangsong1213/Mamba-UIE.
Fish Tracking, Counting, and Behaviour Analysis in Digital Aquaculture: A Comprehensive Review
Jun 20, 2024Digital aquaculture leverages advanced technologies and data-driven methods, providing substantial benefits over traditional aquaculture practices. Fish tracking, counting, and behaviour analysis are crucial components of digital aquaculture, which are essential for optimizing production efficiency, enhancing fish welfare, and improving resource management. Previous reviews have focused on single modalities, limiting their ability to address the diverse challenges encountered in these tasks comprehensively. This review provides a comprehensive analysis of the current state of aquaculture digital technologies, including vision-based, acoustic-based, and biosensor-based methods. We examine the advantages, limitations, and applications of these methods, highlighting recent advancements and identifying critical research gaps. The scarcity of comprehensive fish datasets and the lack of unified evaluation standards, which make it difficult to compare the performance of different technologies, are identified as major obstacles hindering progress in this field. To overcome current limitations and improve the accuracy, robustness, and efficiency of fish monitoring systems, we explore the potential of emerging technologies such as multimodal data fusion and deep learning. Additionally, we contribute to the field by providing a summary of existing datasets available for fish tracking, counting, and behaviour analysis. Future research directions are outlined, emphasizing the need for comprehensive datasets and evaluation standards to facilitate meaningful comparisons between technologies and promote their practical implementation in real-world aquaculture settings.
Multimodal Fish Feeding Intensity Assessment in Aquaculture
Sep 10, 2023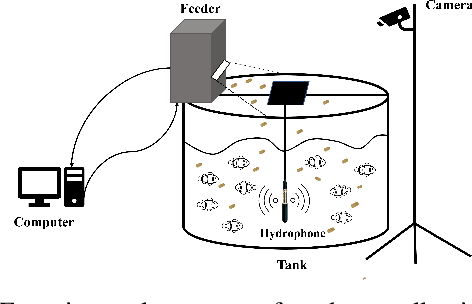
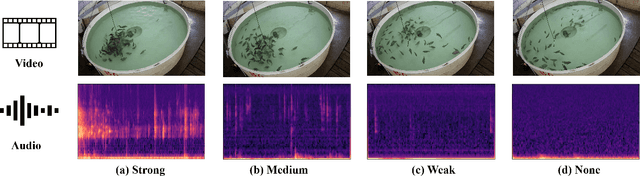
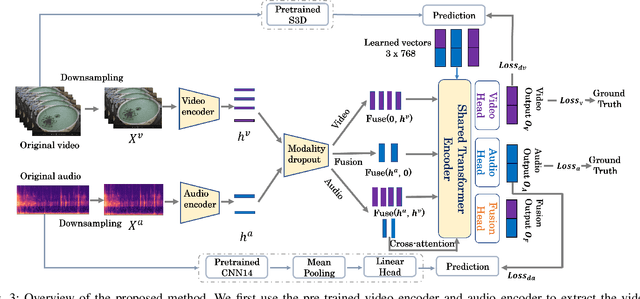

Fish feeding intensity assessment (FFIA) aims to evaluate the intensity change of fish appetite during the feeding process, which is vital in industrial aquaculture applications. The main challenges surrounding FFIA are two-fold. 1) robustness: existing work has mainly leveraged single-modality (e.g., vision, audio) methods, which have a high sensitivity to input noise. 2) efficiency: FFIA models are generally expected to be employed on devices. This presents a challenge in terms of computational efficiency. In this work, we first introduce an audio-visual dataset, called AV-FFIA. AV-FFIA consists of 27,000 labeled audio and video clips that capture different levels of fish feeding intensity. To our knowledge, AV-FFIA is the first large-scale multimodal dataset for FFIA research. Then, we introduce a multi-modal approach for FFIA by leveraging single-modality pre-trained models and modality-fusion methods, with benchmark studies on AV-FFIA. Our experimental results indicate that the multi-modal approach substantially outperforms the single-modality based approach, especially in noisy environments. While multimodal approaches provide a performance gain for FFIA, it inherently increase the computational cost. To overcome this issue, we further present a novel unified model, termed as U-FFIA. U-FFIA is a single model capable of processing audio, visual, or audio-visual modalities, by leveraging modality dropout during training and knowledge distillation from single-modality pre-trained models. We demonstrate that U-FFIA can achieve performance better than or on par with the state-of-the-art modality-specific FFIA models, with significantly lower computational overhead. Our proposed U-FFIA approach enables a more robust and efficient method for FFIA, with the potential to contribute to improved management practices and sustainability in aquaculture.