 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-stage augmented multimodal interaction network for fish feeding intensity quantification
Jun 17, 2025In recirculating aquaculture systems, accurate and effective assessment of fish feeding intensity is crucial for reducing feed costs and calculating optimal feeding times. However, current studies have limitations in modality selection, feature extraction and fusion, and co-inference for decision making, which restrict further improvement in the accuracy, applicability and reliability of multimodal fusion models. To address this problem, this study proposes a Multi-stage Augmented Multimodal Interaction Network (MAINet) for quantifying fish feeding intensity. Firstly, a general feature extraction framework is proposed to efficiently extract feature information from input image, audio and water wave datas. Second, an Auxiliary-modality Reinforcement Primary-modality Mechanism (ARPM) is designed for inter-modal interaction and generate enhanced features, which consists of a Channel Attention Fusion Network (CAFN) and a Dual-mode Attention Fusion Network (DAFN). Finally, an Evidence Reasoning (ER) rule is introduced to fuse the output results of each modality and make decisions, thereby completing the quantification of fish feeding intensity. The experimental results show that the constructed MAINet reaches 96.76%, 96.78%, 96.79% and 96.79% in accuracy, precision, recall and F1-Score respectively, and its performance is significantly higher than the comparison models. Compared with models that adopt single-modality, dual-modality fusion and different decision-making fusion methods, it also has obvious advantages. Meanwhile, the ablation experiments further verified the key role of the proposed improvement strategy in improving the robustness and feature utilization efficiency of model, which can effectively improve the accuracy of the quantitative results of fish feeding intensity.
V2V3D: View-to-View Denoised 3D Reconstruction for Light-Field Microscopy
Apr 10, 2025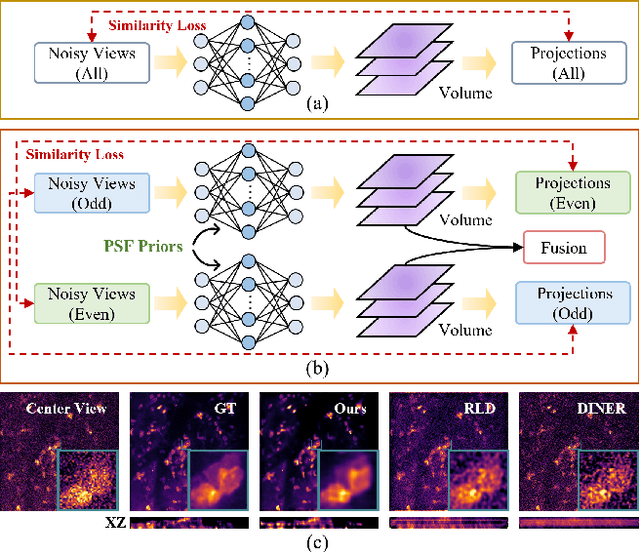
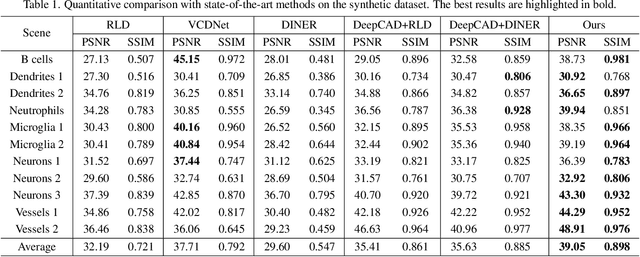
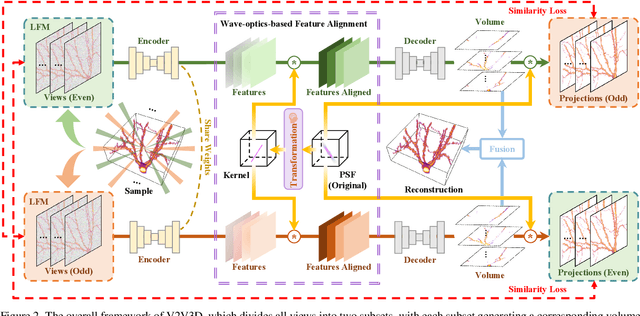
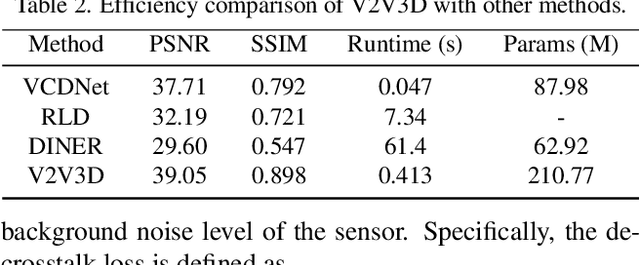
Light field microscopy (LFM) has gained significant attention due to its ability to capture snapshot-based, large-scale 3D fluorescence images. However, existing LFM reconstruction algorithms are highly sensitive to sensor noise or require hard-to-get ground-truth annotated data for training. To address these challenges, this paper introduces V2V3D, an unsupervised view2view-based framework that establishes a new paradigm for joint optimization of image denoising and 3D reconstruction in a unified architecture. We assume that the LF images are derived from a consistent 3D signal, with the noise in each view being independent. This enables V2V3D to incorporate the principle of noise2noise for effective denoising. To enhance the recovery of high-frequency details, we propose a novel wave-optics-based feature alignment technique, which transforms the point spread function, used for forward propagation in wave optics, into convolution kernels specifically designed for feature alignment. Moreover, we introduce an LFM dataset containing LF images and their corresponding 3D intensity volumes. Extensive experiments demonstrate that our approach achieves high computational efficiency and outperforms the other state-of-the-art methods. These advancements position V2V3D as a promising solution for 3D imaging under challenging conditions.
Research advances on fish feeding behavior recognition and intensity quantification methods in aquaculture
Feb 21, 2025



As a key part of aquaculture management, fish feeding behavior recognition and intensity quantification has been a hot area of great concern to researchers, and it plays a crucial role in monitoring fish health, guiding baiting work and improving aquaculture efficiency. In order to better carry out the related work in the future, this paper firstly reviews the research advances of fish feeding behavior recognition and intensity quantification methods based on computer vision, acoustics and sensors in a single modality. Then the application of the current emerging multimodal fusion in fish feeding behavior recognition and intensity quantification methods is expounded. Finally, the advantages and disadvantages of various techniques are compared and analyzed, and the future research directions are envisioned.
PNR: Physics-informed Neural Representation for high-resolution LFM reconstruction
Sep 26, 2024Light field microscopy (LFM) has been widely utilized in various fields for its capability to efficiently capture high-resolution 3D scenes. Despite the rapid advancements in neural representations, there are few methods specifically tailored for microscopic scenes. Existing approaches often do not adequately address issues such as the loss of high-frequency information due to defocus and sample aberration, resulting in suboptimal performance. In addition, existing methods, including RLD, INR, and supervised U-Net, face challenges such as sensitivity to initial estimates, reliance on extensive labeled data, and low computational efficiency, all of which significantly diminish the practicality in complex biological scenarios. This paper introduces PNR (Physics-informed Neural Representation), a method for high-resolution LFM reconstruction that significantly enhances performance. Our method incorporates an unsupervised and explicit feature representation approach, resulting in a 6.1 dB improvement in PSNR than RLD. Additionally, our method employs a frequency-based training loss, enabling better recovery of high-frequency details, which leads to a reduction in LPIPS by at least half compared to SOTA methods (1.762 V.S. 3.646 of DINER). Moreover, PNR integrates a physics-informed aberration correction strategy that optimizes Zernike polynomial parameters during optimization, thereby reducing the information loss caused by aberrations and improving spatial resolution. These advancements make PNR a promising solution for long-term high-resolution biological imaging applications. Our code and dataset will be made publicly available.
FMRFT: Fusion Mamba and DETR for Query Time Sequence Intersection Fish Tracking
Sep 02, 2024Growth, abnormal behavior, and diseases of fish can be early detected by monitoring fish tracking through the method of image processing, which is of great significance for factory aquaculture. However, underwater reflections and some reasons with fish, such as the high similarity , rapid swimming caused by stimuli and multi-object occlusion bring challenges to multi-target tracking of fish. To address these challenges, this paper establishes a complex multi-scene sturgeon tracking dataset and proposes a real-time end-to-end fish tracking model, FMRFT. In this model, the Mamba In Mamba (MIM) architecture with low memory consumption is introduced into the tracking algorithm to realize multi-frame video timing memory and fast feature extraction, which improves the efficiency of correlation analysis for contiguous frames in multi-fish video. Additionally, the superior feature interaction and a priori frame processing capabilities of RT-DETR are leveraged to provide an effective tracking algorithm. By incorporating the QTSI query interaction processing module, the model effectively handles occluded objects and redundant tracking frames, resulting in more accurate and stable fish tracking. Trained and tested on the dataset, the model achieves an IDF1 score of 90.3% and a MOTA accuracy of 94.3%. Experimental results demonstrate that the proposed FMRFT model effectively addresses the challenges of high similarity and mutual occlusion in fish populations, enabling accurate tracking in factory farming environments.
OPAL: Occlusion Pattern Aware Loss for Unsupervised Light Field Disparity Estimation
Mar 31, 2022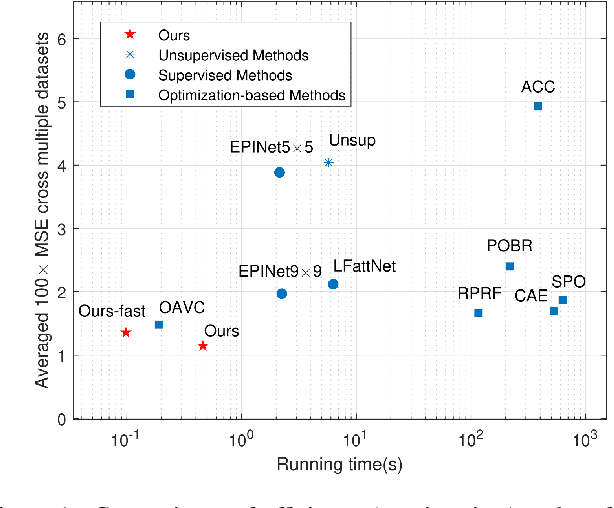
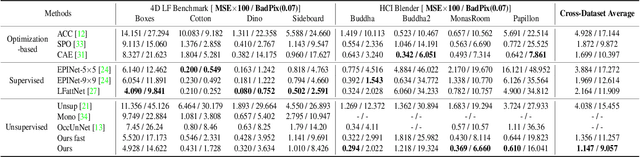
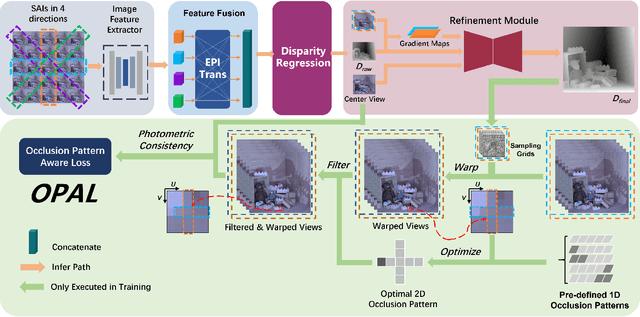
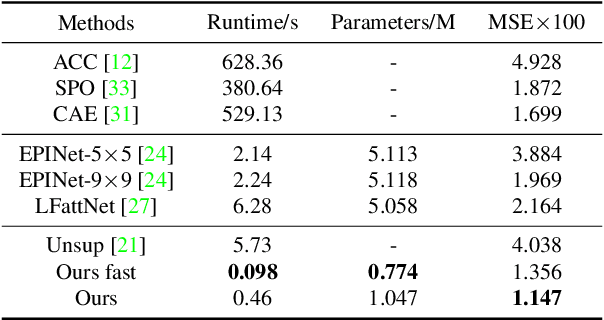
Light field disparity estimation is an essential task in computer vision with various applications. Although supervised learning-based methods have achieved both higher accuracy and efficiency than traditional optimization-based methods, the dependency on ground-truth disparity for training limits the overall generalization performance not to say for real-world scenarios where the ground-truth disparity is hard to capture. In this paper, we argue that unsupervised methods can achieve comparable accuracy, but, more importantly, much higher generalization capacity and efficiency than supervised methods. Specifically, we present the Occlusion Pattern Aware Loss, named OPAL, which successfully extracts and encodes the general occlusion patterns inherent in the light field for loss calculation. OPAL enables: i) accurate and robust estimation by effectively handling occlusions without using any ground-truth information for training and ii) much efficient performance by significantly reducing the network parameters required for accurate inference. Besides, a transformer-based network and a refinement module are proposed for achieving even more accurate results. Extensive experiments demonstrate our method not only significantly improves the accuracy compared with the SOTA unsupervised methods, but also possesses strong generalization capacity, even for real-world data, compared with supervised methods. Our code will be made publicly available.