 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSapiens: A Foundation Model for Social Behavior Processing via Heterogeneity-Aware Relative Policy Optimization
Feb 11, 2026To develop socially intelligent AI, existing approaches typically model human behavioral dimensions (e.g., affective, cognitive, or social attributes) in isolation. Although useful, task-specific modeling often increases training costs and limits generalization across behavioral settings. Recent reasoning RL methods facilitate training a single unified model across multiple behavioral tasks, but do not explicitly address learning across different heterogeneous behavioral data. To address this gap, we introduce Heterogeneity-Aware Relative Policy Optimization (HARPO), an RL method that balances leaning across heterogeneous tasks and samples. This is achieved by modulating advantages to ensure that no single task or sample carries disproportionate influence during policy optimization. Using HARPO, we develop and release Omnisapiens-7B 2.0, a foundation model for social behavior processing. Relative to existing behavioral foundation models, Omnisapiens-7B 2.0 achieves the strongest performance across behavioral tasks, with gains of up to +16.85% and +9.37% on multitask and held-out settings respectively, while producing more explicit and robust reasoning traces. We also validate HARPO against recent RL methods, where it achieves the most consistently strong performance across behavioral tasks.
<SOG_k>: One LLM Token for Explicit Graph Structural Understanding
Feb 02, 2026Large language models show great potential in unstructured data understanding, but still face significant challenges with graphs due to their structural hallucination. Existing approaches mainly either verbalize graphs into natural language, which leads to excessive token consumption and scattered attention, or transform graphs into trainable continuous embeddings (i.e., soft prompt), but exhibit severe misalignment with original text tokens. To solve this problem, we propose to incorporate one special token <SOG_k> to fully represent the Structure Of Graph within a unified token space, facilitating explicit topology input and structural information sharing. Specifically, we propose a topology-aware structural tokenizer that maps each graph topology into a highly selective single token. Afterwards, we construct a set of hybrid structure Question-Answering corpora to align new structural tokens with existing text tokens. With this approach, <SOG_k> empowers LLMs to understand, generate, and reason in a concise and accurate manner. Extensive experiments on five graph-level benchmarks demonstrate the superiority of our method, achieving a performance improvement of 9.9% to 41.4% compared to the baselines while exhibiting interpretability and consistency. Furthermore, our method provides a flexible extension to node-level tasks, enabling both global and local structural understanding. The codebase is publicly available at https://github.com/Jingyao-Wu/SOG.
Decoding Ambiguous Emotions with Test-Time Scaling in Audio-Language Models
Feb 01, 2026Emotion recognition from human speech is a critical enabler for socially aware conversational AI. However, while most prior work frames emotion recognition as a categorical classification problem, real-world affective states are often ambiguous, overlapping, and context-dependent, posing significant challenges for both annotation and automatic modeling. Recent large-scale audio language models (ALMs) offer new opportunities for nuanced affective reasoning without explicit emotion supervision, but their capacity to handle ambiguous emotions remains underexplored. At the same time, advances in inference-time techniques such as test-time scaling (TTS) have shown promise for improving generalization and adaptability in hard NLP tasks, but their relevance to affective computing is still largely unknown. In this work, we introduce the first benchmark for ambiguous emotion recognition in speech with ALMs under test-time scaling. Our evaluation systematically compares eight state-of-the-art ALMs and five TTS strategies across three prominent speech emotion datasets. We further provide an in-depth analysis of the interaction between model capacity, TTS, and affective ambiguity, offering new insights into the computational and representational challenges of ambiguous emotion understanding. Our benchmark establishes a foundation for developing more robust, context-aware, and emotionally intelligent speech-based AI systems, and highlights key future directions for bridging the gap between model assumptions and the complexity of real-world human emotion.
AmbER$^2$: Dual Ambiguity-Aware Emotion Recognition Applied to Speech and Text
Jan 25, 2026Emotion recognition is inherently ambiguous, with uncertainty arising both from rater disagreement and from discrepancies across modalities such as speech and text. There is growing interest in modeling rater ambiguity using label distributions. However, modality ambiguity remains underexplored, and multimodal approaches often rely on simple feature fusion without explicitly addressing conflicts between modalities. In this work, we propose AmbER$^2$, a dual ambiguity-aware framework that simultaneously models rater-level and modality-level ambiguity through a teacher-student architecture with a distribution-wise training objective. Evaluations on IEMOCAP and MSP-Podcast show that AmbER$^2$ consistently improves distributional fidelity over conventional cross-entropy baselines and achieves performance competitive with, or superior to, recent state-of-the-art systems. For example, on IEMOCAP, AmbER$^2$ achieves relative improvements of 20.3% on Bhattacharyya coefficient (0.83 vs. 0.69), 13.6% on R$^2$ (0.67 vs. 0.59), 3.8% on accuracy (0.683 vs. 0.658), and 4.5% on F1 (0.675 vs. 0.646). Further analysis across ambiguity levels shows that explicitly modeling ambiguity is particularly beneficial for highly uncertain samples. These findings highlight the importance of jointly addressing rater and modality ambiguity when building robust emotion recognition systems.
Human Behavior Atlas: Benchmarking Unified Psychological and Social Behavior Understanding
Oct 06, 2025Using intelligent systems to perceive psychological and social behaviors, that is, the underlying affective, cognitive, and pathological states that are manifested through observable behaviors and social interactions, remains a challenge due to their complex, multifaceted, and personalized nature. Existing work tackling these dimensions through specialized datasets and single-task systems often miss opportunities for scalability, cross-task transfer, and broader generalization. To address this gap, we curate Human Behavior Atlas, a unified benchmark of diverse behavioral tasks designed to support the development of unified models for understanding psychological and social behaviors. Human Behavior Atlas comprises over 100,000 samples spanning text, audio, and visual modalities, covering tasks on affective states, cognitive states, pathologies, and social processes. Our unification efforts can reduce redundancy and cost, enable training to scale efficiently across tasks, and enhance generalization of behavioral features across domains. On Human Behavior Atlas, we train three models: OmniSapiens-7B SFT, OmniSapiens-7B BAM, and OmniSapiens-7B RL. We show that training on Human Behavior Atlas enables models to consistently outperform existing multimodal LLMs across diverse behavioral tasks. Pretraining on Human Behavior Atlas also improves transfer to novel behavioral datasets; with the targeted use of behavioral descriptors yielding meaningful performance gains.
Emotions as Ambiguity-aware Ordinal Representations
Aug 27, 2025Emotions are inherently ambiguous and dynamic phenomena, yet existing continuous emotion recognition approaches either ignore their ambiguity or treat ambiguity as an independent and static variable over time. Motivated by this gap in the literature, in this paper we introduce ambiguity-aware ordinal emotion representations, a novel framework that captures both the ambiguity present in emotion annotation and the inherent temporal dynamics of emotional traces. Specifically, we propose approaches that model emotion ambiguity through its rate of change. We evaluate our framework on two affective corpora -- RECOLA and GameVibe -- testing our proposed approaches on both bounded (arousal, valence) and unbounded (engagement) continuous traces. Our results demonstrate that ordinal representations outperform conventional ambiguity-aware models on unbounded labels, achieving the highest Concordance Correlation Coefficient (CCC) and Signed Differential Agreement (SDA) scores, highlighting their effectiveness in modeling the traces' dynamics. For bounded traces, ordinal representations excel in SDA, revealing their superior ability to capture relative changes of annotated emotion traces.
Dual-Constrained Dynamical Neural ODEs for Ambiguity-aware Continuous Emotion Prediction
Jul 31, 2024There has been a significant focus on modelling emotion ambiguity in recent years, with advancements made in representing emotions as distributions to capture ambiguity. However, there has been comparatively less effort devoted to the consideration of temporal dependencies in emotion distributions which encodes ambiguity in perceived emotions that evolve smoothly over time. Recognizing the benefits of using constrained dynamical neural ordinary differential equations (CD-NODE) to model time series as dynamic processes, we propose an ambiguity-aware dual-constrained Neural ODE approach to model the dynamics of emotion distributions on arousal and valence. In our approach, we utilize ODEs parameterised by neural networks to estimate the distribution parameters, and we integrate additional constraints to restrict the range of the system outputs to ensure the validity of predicted distributions. We evaluated our proposed system on the publicly available RECOLA dataset and observed very promising performance across a range of evaluation metrics.
OPAL: Occlusion Pattern Aware Loss for Unsupervised Light Field Disparity Estimation
Mar 31, 2022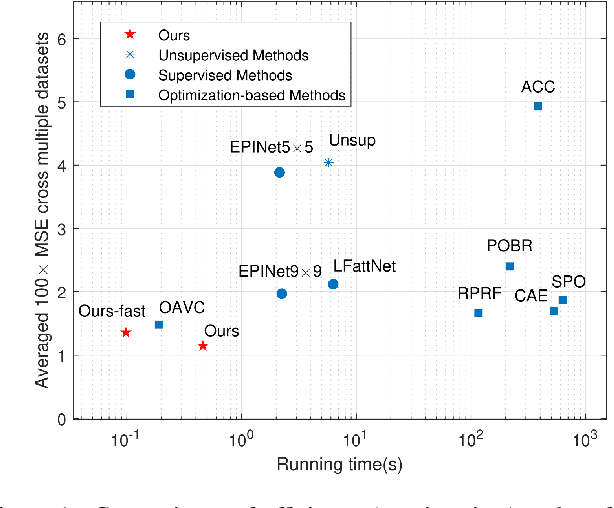
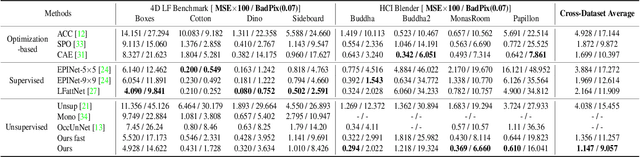
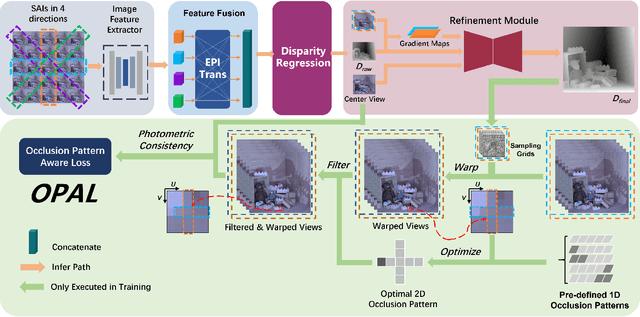
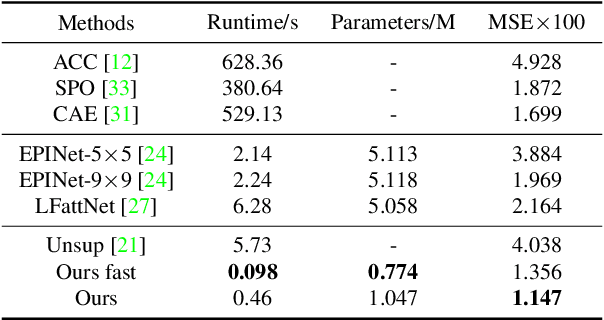
Light field disparity estimation is an essential task in computer vision with various applications. Although supervised learning-based methods have achieved both higher accuracy and efficiency than traditional optimization-based methods, the dependency on ground-truth disparity for training limits the overall generalization performance not to say for real-world scenarios where the ground-truth disparity is hard to capture. In this paper, we argue that unsupervised methods can achieve comparable accuracy, but, more importantly, much higher generalization capacity and efficiency than supervised methods. Specifically, we present the Occlusion Pattern Aware Loss, named OPAL, which successfully extracts and encodes the general occlusion patterns inherent in the light field for loss calculation. OPAL enables: i) accurate and robust estimation by effectively handling occlusions without using any ground-truth information for training and ii) much efficient performance by significantly reducing the network parameters required for accurate inference. Besides, a transformer-based network and a refinement module are proposed for achieving even more accurate results. Extensive experiments demonstrate our method not only significantly improves the accuracy compared with the SOTA unsupervised methods, but also possesses strong generalization capacity, even for real-world data, compared with supervised methods. Our code will be made publicly available.
A Novel Markovian Framework for Integrating Absolute and Relative Ordinal Emotion Information
Aug 10, 2021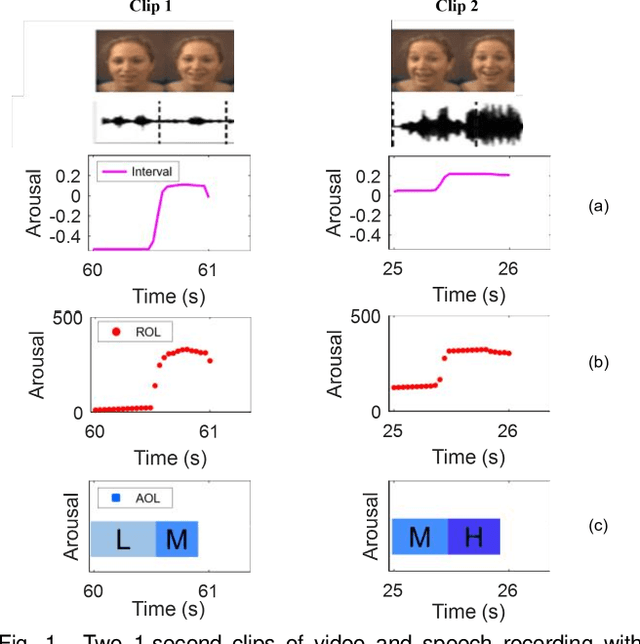
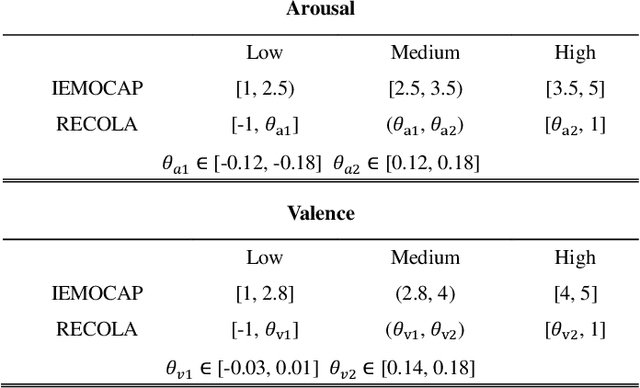
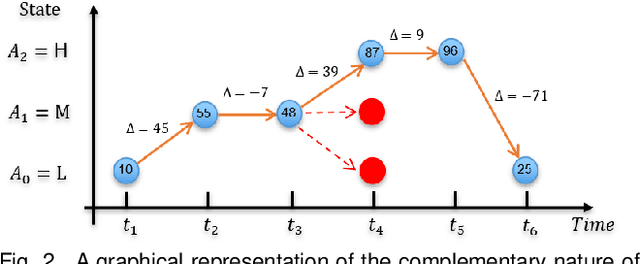
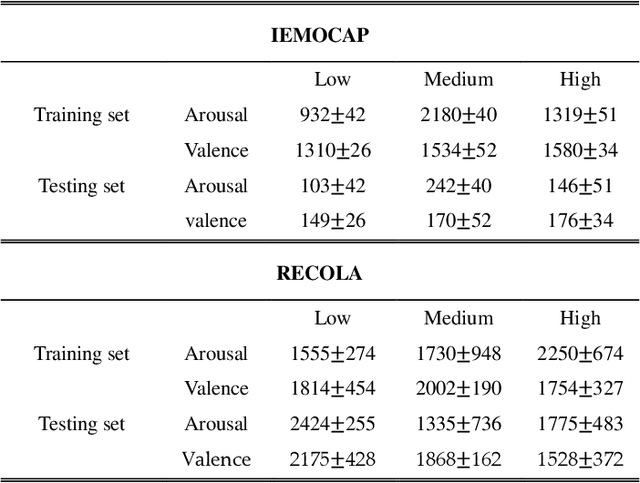
There is growing interest in affective computing for the representation and prediction of emotions along ordinal scales. However, the term ordinal emotion label has been used to refer to both absolute notions such as low or high arousal, as well as relation notions such as arousal is higher at one instance compared to another. In this paper, we introduce the terminology absolute and relative ordinal labels to make this distinction clear and investigate both with a view to integrate them and exploit their complementary nature. We propose a Markovian framework referred to as Dynamic Ordinal Markov Model (DOMM) that makes use of both absolute and relative ordinal information, to improve speech based ordinal emotion prediction. Finally, the proposed framework is validated on two speech corpora commonly used in affective computing, the RECOLA and the IEMOCAP databases, across a range of system configurations. The results consistently indicate that integrating relative ordinal information improves absolute ordinal emotion prediction.
Deep Learning Algorithms for Rotating Machinery Intelligent Diagnosis: An Open Source Benchmark Study
Mar 06, 2020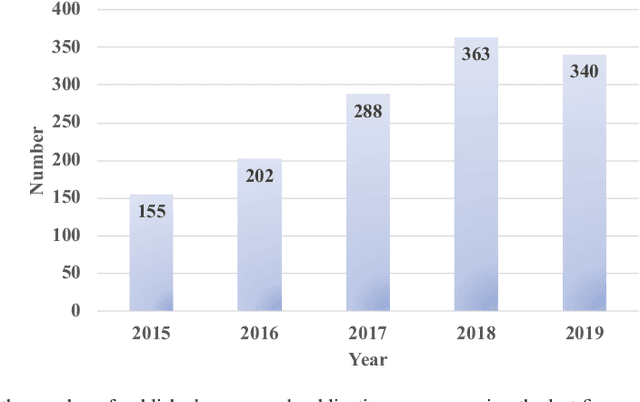


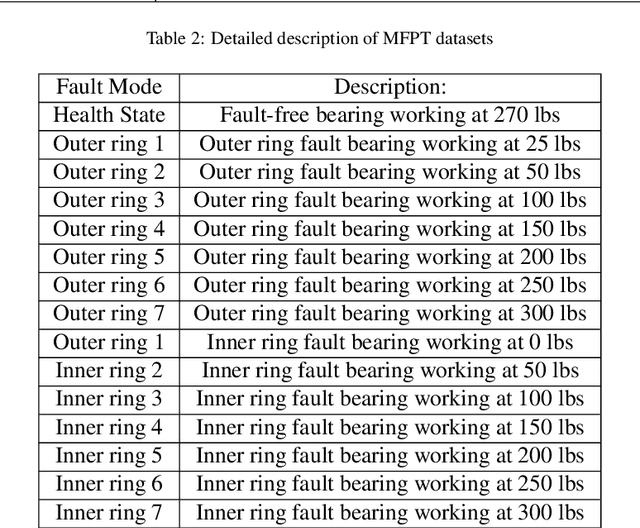
With the development of artificial intelligence and deep learning (DL) techniques, rotating machinery intelligent diagnosis has gone through tremendous progress with verified success and the classification accuracies of many DL-based intelligent diagnosis algorithms are tending to 100\%. However, different datasets, configurations, and hyper-parameters are often recommended to be used in performance verification for different types of models, and few open source codes are made public for evaluation and comparisons. Therefore, unfair comparisons and ineffective improvement may exist in rotating machinery intelligent diagnosis, which limits the advancement of this field. To address these issues, we perform an extensive evaluation of four kinds of models with various datasets to provide a benchmark study within the same framework. In this paper, we first gather most of the publicly available datasets and give the complete benchmark study of DL-based intelligent algorithms under two data split strategies, five input formats, three normalization methods, and four augmentation methods. Second, we integrate the whole evaluation codes into a code library and release this code library to the public for better development of this field. Third, we use the specific-designed cases to point out the existing issues, including class imbalance, generalization ability, interpretability, few-shot learning, and model selection. By these works, we release a unified code framework for comparing and testing models fairly and quickly, emphasize the importance of open source codes, provide the baseline accuracy (a lower bound) to avoid useless improvement, and discuss potential future directions in this field. The code library is available at \url{https://github.com/ZhaoZhibin/DL-based-Intelligent-Diagnosis-Benchmark}.