 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Norm Soft Thresholding for Sparse Time-frequency Representation
Jan 14, 2025Time-frequency (TF) representation of non-stationary signals typically requires the effective concentration of energy distribution along the instantaneous frequency (IF) ridge, which exhibits intrinsic sparsity. Inspired by the sparse optimization over continuum via atomic norm, a novel atomic norm soft thresholding for sparse TF representation (AST-STF) method is proposed, which ensures accurate TF localization under the strong duality. Numerical experiments demonstrate that the performance of the proposed method surpasses that of conventional methods.
Deep Learning Algorithms for Rotating Machinery Intelligent Diagnosis: An Open Source Benchmark Study
Mar 06, 2020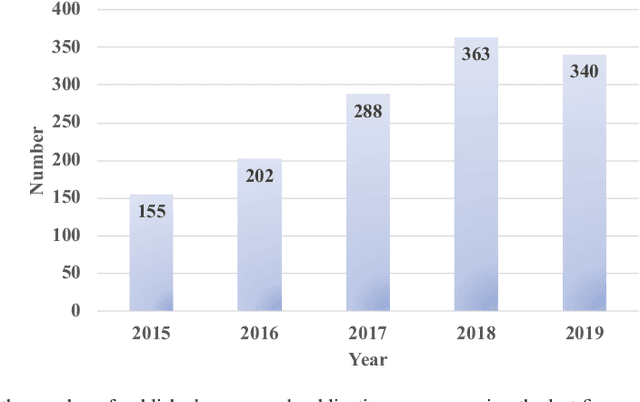


With the development of artificial intelligence and deep learning (DL) techniques, rotating machinery intelligent diagnosis has gone through tremendous progress with verified success and the classification accuracies of many DL-based intelligent diagnosis algorithms are tending to 100\%. However, different datasets, configurations, and hyper-parameters are often recommended to be used in performance verification for different types of models, and few open source codes are made public for evaluation and comparisons. Therefore, unfair comparisons and ineffective improvement may exist in rotating machinery intelligent diagnosis, which limits the advancement of this field. To address these issues, we perform an extensive evaluation of four kinds of models with various datasets to provide a benchmark study within the same framework. In this paper, we first gather most of the publicly available datasets and give the complete benchmark study of DL-based intelligent algorithms under two data split strategies, five input formats, three normalization methods, and four augmentation methods. Second, we integrate the whole evaluation codes into a code library and release this code library to the public for better development of this field. Third, we use the specific-designed cases to point out the existing issues, including class imbalance, generalization ability, interpretability, few-shot learning, and model selection. By these works, we release a unified code framework for comparing and testing models fairly and quickly, emphasize the importance of open source codes, provide the baseline accuracy (a lower bound) to avoid useless improvement, and discuss potential future directions in this field. The code library is available at \url{https://github.com/ZhaoZhibin/DL-based-Intelligent-Diagnosis-Benchmark}.
Unsupervised Deep Transfer Learning for Intelligent Fault Diagnosis: An Open Source and Comparative Study
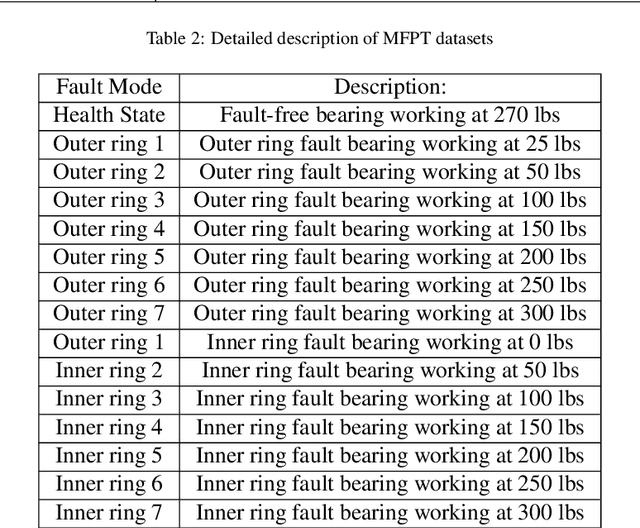
Dec 28, 2019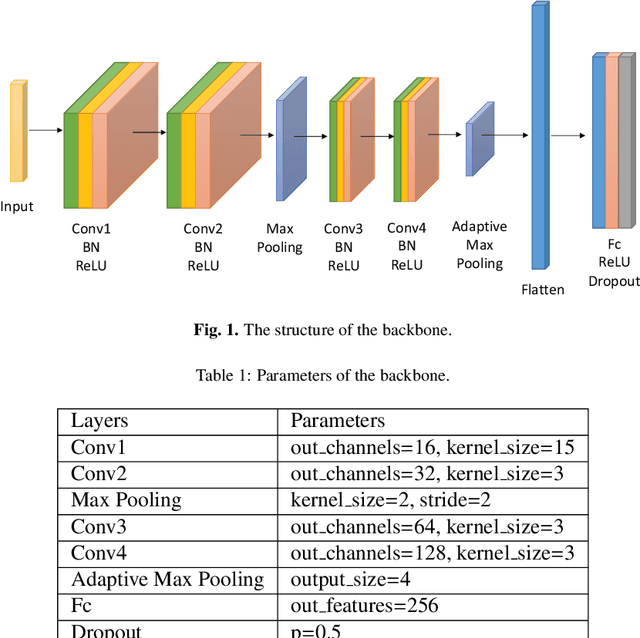
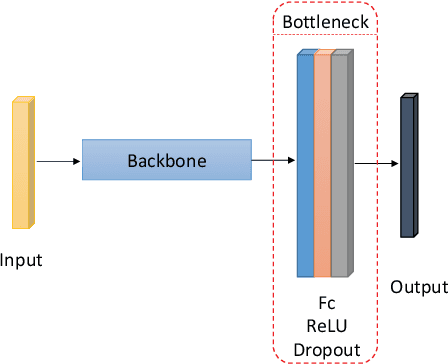
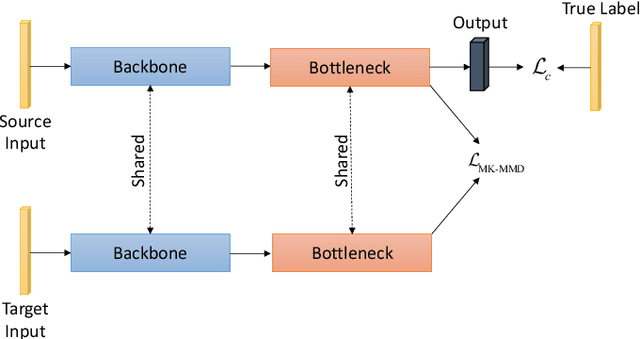
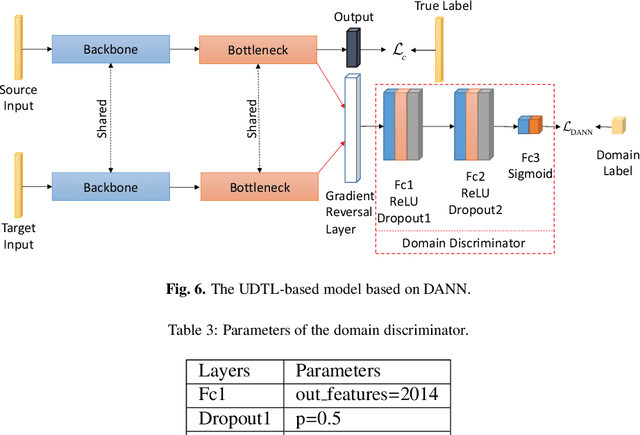
Recent progress on intelligent fault diagnosis has greatly depended on the deep learning and plenty of labeled data. However, the machine often operates with various working conditions or the target task has different distributions with the collected data used for training (we called the domain shift problem). This leads to the deep transfer learning based (DTL-based) intelligent fault diagnosis which attempts to remit this domain shift problem. Besides, the newly collected testing data are usually unlabeled, which results in the subclass DTL-based methods called unsupervised deep transfer learning based (UDTL-based) intelligent fault diagnosis. Although it has achieved huge development in the field of fault diagnosis, a standard and open source code framework and a comparative study for UDTL-based intelligent fault diagnosis are not yet established. In this paper, commonly used UDTL-based algorithms in intelligent fault diagnosis are integrated into a unified testing framework and the framework is tested on five datasets. Extensive experiments are performed to provide a systematically comparative analysis and the benchmark accuracy for more comparable and meaningful further studies. To emphasize the importance and reproducibility of UDTL-based intelligent fault diagnosis, the testing framework with source codes will be released to the research community to facilitate future research. Finally, comparative analysis of results also reveals some open and essential issues in DTL for intelligent fault diagnosis which are rarely studied including transferability of features, influence of backbones, negative transfer, and physical priors. In summary, the released framework and comparative study can serve as an extended interface and the benchmark results to carry out new studies on UDTL-based intelligent fault diagnosis. The code framework is available at https://github.com/ZhaoZhibin/UDTL.