 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiEAR: A Human Auditory-Inspired Adaptive Binaural Front-end for Multi-Speaker Localisation and Distance Estimation
Jun 05, 2026We present BiEAR, a human auditory-inspired adaptive binaural front-end for multi-speaker localisation and distance estimation. Inspired by medial olivocochlear (MOC) feedback in human hearing, BiEAR uses a neural controller to adaptively adjust the frequency selectivity of a binaural auditory filterbank during inference. This yields time-frequency adaptive representations for ears, enabling the model to respond to changing acoustic conditions. We evaluate BiEAR on multi-speaker localisation and distance estimation in anechoic and real-room environments. Results show that the adaptive front-end improves localisation accuracy and robustness to unseen speakers and rooms compared with commonly used fixed binaural front-ends. Visualisation and analysis of learned filter adaptations show that BiEAR emphasises informative frequency bands over time. These findings suggest that adaptive, biologically inspired binaural front-ends can improve machine hearing robustness in complex acoustic scenes.
Exploring Length Generalization For Transformer-based Speech Enhancement
Jun 07, 2025
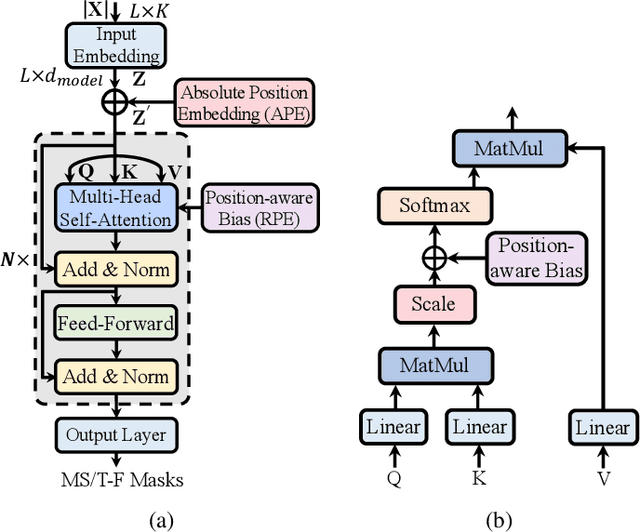
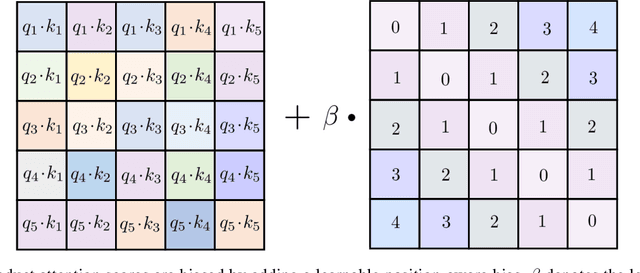
Transformer network architecture has proven effective in speech enhancement. However, as its core module, self-attention suffers from quadratic complexity, making it infeasible for training on long speech utterances. In practical scenarios, speech enhancement models are often required to perform on noisy speech at run-time that is substantially longer than the training utterances. It remains a challenge how a Transformer-based speech enhancement model can generalize to long speech utterances. In this paper, extensive empirical studies are conducted to explore the model's length generalization ability. In particular, we conduct speech enhancement experiments on four training objectives and evaluate with five metrics. Our studies establish that positional encoding is an effective instrument to dampen the effect of utterance length on speech enhancement. We first explore several existing positional encoding methods, and the results show that relative positional encoding methods exhibit a better length generalization property than absolute positional encoding methods. Additionally, we also explore a simpler and more effective positional encoding scheme, i.e. LearnLin, that uses only one trainable parameter for each attention head to scale the real relative position between time frames, which learns the different preferences on short- or long-term dependencies of these heads. The results demonstrate that our proposal exhibits excellent length generalization ability with comparable or superior performance than other state-of-the-art positional encoding strategies.
Should Audio Front-ends be Adaptive? Comparing Learnable and Adaptive Front-ends
Feb 05, 2025Hand-crafted features, such as Mel-filterbanks, have traditionally been the choice for many audio processing applications. Recently, there has been a growing interest in learnable front-ends that extract representations directly from the raw audio waveform. \textcolor{black}{However, both hand-crafted filterbanks and current learnable front-ends lead to fixed computation graphs at inference time, failing to dynamically adapt to varying acoustic environments, a key feature of human auditory systems.} To this end, we explore the question of whether audio front-ends should be adaptive by comparing the Ada-FE front-end (a recently developed adaptive front-end that employs a neural adaptive feedback controller to dynamically adjust the Q-factors of its spectral decomposition filters) to established learnable front-ends. Specifically, we systematically investigate learnable front-ends and Ada-FE across two commonly used back-end backbones and a wide range of audio benchmarks including speech, sound event, and music. The comprehensive results show that our Ada-FE outperforms advanced learnable front-ends, and more importantly, it exhibits impressive stability or robustness on test samples over various training epochs.
Blind Estimation of Sub-band Acoustic Parameters from Ambisonics Recordings using Spectro-Spatial Covariance Features
Nov 05, 2024Estimating frequency-varying acoustic parameters is essential for enhancing immersive perception in realistic spatial audio creation. In this paper, we propose a unified framework that blindly estimates reverberation time (T60), direct-to-reverberant ratio (DRR), and clarity (C50) across 10 frequency bands using first-order Ambisonics (FOA) speech recordings as inputs. The proposed framework utilizes a novel feature named Spectro-Spatial Covariance Vector (SSCV), efficiently representing temporal, spectral as well as spatial information of the FOA signal. Our models significantly outperform existing single-channel methods with only spectral information, reducing estimation errors by more than half for all three acoustic parameters. Additionally, we introduce FOA-Conv3D, a novel back-end network for effectively utilising the SSCV feature with a 3D convolutional encoder. FOA-Conv3D outperforms the convolutional neural network (CNN) and recurrent convolutional neural network (CRNN) backends, achieving lower estimation errors and accounting for a higher proportion of variance (PoV) for all 3 acoustic parameters.
Dual-Constrained Dynamical Neural ODEs for Ambiguity-aware Continuous Emotion Prediction
Jul 31, 2024There has been a significant focus on modelling emotion ambiguity in recent years, with advancements made in representing emotions as distributions to capture ambiguity. However, there has been comparatively less effort devoted to the consideration of temporal dependencies in emotion distributions which encodes ambiguity in perceived emotions that evolve smoothly over time. Recognizing the benefits of using constrained dynamical neural ordinary differential equations (CD-NODE) to model time series as dynamic processes, we propose an ambiguity-aware dual-constrained Neural ODE approach to model the dynamics of emotion distributions on arousal and valence. In our approach, we utilize ODEs parameterised by neural networks to estimate the distribution parameters, and we integrate additional constraints to restrict the range of the system outputs to ensure the validity of predicted distributions. We evaluated our proposed system on the publicly available RECOLA dataset and observed very promising performance across a range of evaluation metrics.
Binaural Selective Attention Model for Target Speaker Extraction
Jun 18, 2024



The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
An Exploration of Length Generalization in Transformer-Based Speech Enhancement
Jun 17, 2024



The use of Transformer architectures has facilitated remarkable progress in speech enhancement. Training Transformers using substantially long speech utterances is often infeasible as self-attention suffers from quadratic complexity. It is a critical and unexplored challenge for a Transformer-based speech enhancement model to learn from short speech utterances and generalize to longer ones. In this paper, we conduct comprehensive experiments to explore the length generalization problem in speech enhancement with Transformer. Our findings first establish that position embedding provides an effective instrument to alleviate the impact of utterance length on Transformer-based speech enhancement. Specifically, we explore four different position embedding schemes to enable length generalization. The results confirm the superiority of relative position embeddings (RPEs) over absolute PE (APEs) in length generalization.
Mamba in Speech: Towards an Alternative to Self-Attention
May 22, 2024



Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
What is Learnt by the LEArnable Front-end ? Adapting Per-Channel Energy Normalisation to Noisy Conditions
Apr 10, 2024There is increasing interest in the use of the LEArnable Front-end (LEAF) in a variety of speech processing systems. However, there is a dearth of analyses of what is actually learnt and the relative importance of training the different components of the front-end. In this paper, we investigate this question on keyword spotting, speech-based emotion recognition and language identification tasks and find that the filters for spectral decomposition and the low pass filter used to estimate spectral energy variations exhibit no learning and the per-channel energy normalisation (PCEN) is the key component that is learnt. Following this, we explore the potential of adapting only the PCEN layer with a small amount of noisy data to enable it to learn appropriate dynamic range compression that better suits the noise conditions. This in turn enables a system trained on clean speech to work more accurately on noisy test data as demonstrated by the experimental results reported in this paper.
* Interspeech 2023 Proceeding
An Empirical Study on the Impact of Positional Encoding in Transformer-based Monaural Speech Enhancement
Jan 18, 2024



Transformer architecture has enabled recent progress in speech enhancement. Since Transformers are position-agostic, positional encoding is the de facto standard component used to enable Transformers to distinguish the order of elements in a sequence. However, it remains unclear how positional encoding exactly impacts speech enhancement based on Transformer architectures. In this paper, we perform a comprehensive empirical study evaluating five positional encoding methods, i.e., Sinusoidal and learned absolute position embedding (APE), T5-RPE, KERPLE, as well as the Transformer without positional encoding (No-Pos), across both causal and noncausal configurations. We conduct extensive speech enhancement experiments, involving spectral mapping and masking methods. Our findings establish that positional encoding is not quite helpful for the models in a causal configuration, which indicates that causal attention may implicitly incorporate position information. In a noncausal configuration, the models significantly benefit from the use of positional encoding. In addition, we find that among the four position embeddings, relative position embeddings outperform APEs.