 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Landmark: Acoustic Landmark Dataset and Open-Source Toolkit for Landmark Extraction
Sep 12, 2024



In the speech signal, acoustic landmarks identify times when the acoustic manifestations of the linguistically motivated distinctive features are most salient. Acoustic landmarks have been widely applied in various domains, including speech recognition, speech depression detection, clinical analysis of speech abnormalities, and the detection of disordered speech. However, there is currently no dataset available that provides precise timing information for landmarks, which has been proven to be crucial for downstream applications involving landmarks. In this paper, we selected the most useful acoustic landmarks based on previous research and annotated the TIMIT dataset with them, based on a combination of phoneme boundary information and manual inspection. Moreover, previous landmark extraction tools were not open source or benchmarked, so to address this, we developed an open source Python-based landmark extraction tool and established a series of landmark detection baselines. The first of their kinds, the dataset with landmark precise timing information, landmark extraction tool and baselines are designed to support a wide variety of future research.
Mamba in Speech: Towards an Alternative to Self-Attention
May 22, 2024



Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
Minds versus Machines: Rethinking Entailment Verification with Language Models
Feb 06, 2024Humans make numerous inferences in text comprehension to understand discourse. This paper aims to understand the commonalities and disparities in the inference judgments between humans and state-of-the-art Large Language Models (LLMs). Leveraging a comprehensively curated entailment verification benchmark, we evaluate both human and LLM performance across various reasoning categories. Our benchmark includes datasets from three categories (NLI, contextual QA, and rationales) that include multi-sentence premises and different knowledge types, thereby evaluating the inference capabilities in complex reasoning instances. Notably, our findings reveal LLMs' superiority in multi-hop reasoning across extended contexts, while humans excel in tasks necessitating simple deductive reasoning. Leveraging these insights, we introduce a fine-tuned Flan-T5 model that outperforms GPT-3.5 and rivals with GPT-4, offering a robust open-source solution for entailment verification. As a practical application, we showcase the efficacy of our finetuned model in enhancing self-consistency in model-generated explanations, resulting in a 6% performance boost on average across three multiple-choice question-answering datasets.
An Empirical Revisiting of Linguistic Knowledge Fusion in Language Understanding Tasks
Oct 24, 2022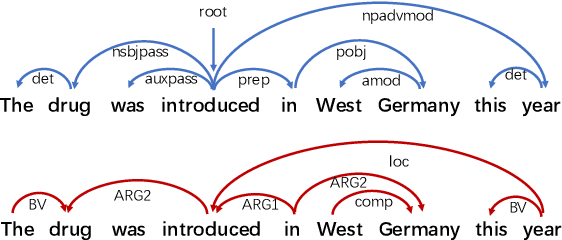
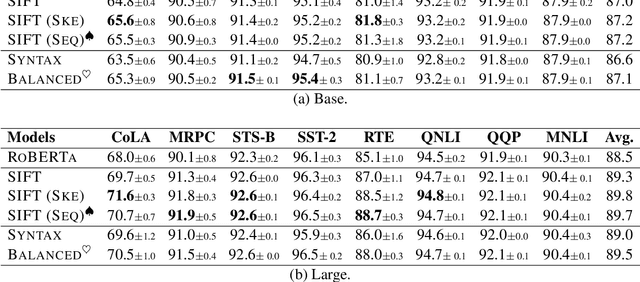
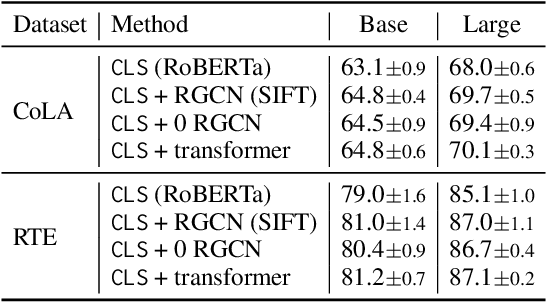

Though linguistic knowledge emerges during large-scale language model pretraining, recent work attempt to explicitly incorporate human-defined linguistic priors into task-specific fine-tuning. Infusing language models with syntactic or semantic knowledge from parsers has shown improvements on many language understanding tasks. To further investigate the effectiveness of structural linguistic priors, we conduct empirical study of replacing parsed graphs or trees with trivial ones (rarely carrying linguistic knowledge e.g., balanced tree) for tasks in the GLUE benchmark. Encoding with trivial graphs achieves competitive or even better performance in fully-supervised and few-shot settings. It reveals that the gains might not be significantly attributed to explicit linguistic priors but rather to more feature interactions brought by fusion layers. Hence we call for attention to using trivial graphs as necessary baselines to design advanced knowledge fusion methods in the future.