 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinctive Feature Codec: Adaptive Segmentation for Efficient Speech Representation
May 24, 2025
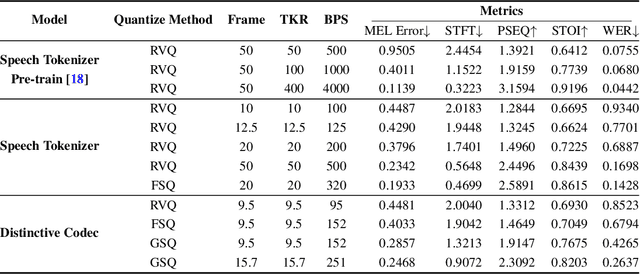
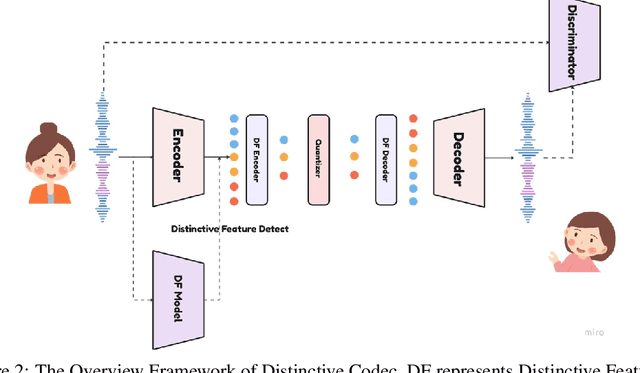
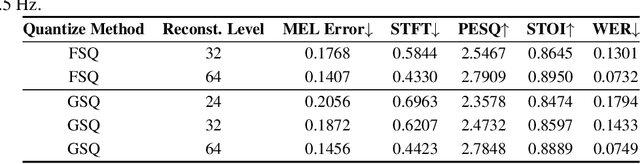
The tokenization of speech with neural speech codec models is a crucial aspect of AI systems designed for speech understanding and generation. While text-based systems naturally benefit from token boundaries between discrete symbols, tokenizing continuous speech signals is more complex due to the unpredictable timing of important acoustic variations. Most current neural speech codecs typically address this by using uniform processing at fixed time intervals, which overlooks the varying information density inherent in speech. In this paper, we introduce a distinctive feature-based approach that dynamically allocates tokens based on the perceptual significance of speech content. By learning to identify and prioritize distinctive regions in speech signals, our approach achieves a significantly more efficient speech representation compared with conventional frame-based methods. This work marks the first successful extension of traditional signal processing-based distinctive features into deep learning frameworks. Through rigorous experimentation, we demonstrate the effectiveness of our approach and provide theoretical insights into how aligning segment boundaries with natural acoustic transitions improves codebook utilization. Additionally, we enhance tokenization stability by developing a Group-wise Scalar Quantization approach for variable-length segments. Our distinctive feature-based approach offers a promising alternative to conventional frame-based processing and advances interpretable representation learning in the modern deep learning speech processing framework.
Why Pre-trained Models Fail: Feature Entanglement in Multi-modal Depression Detection
Mar 09, 2025Depression remains a pressing global mental health issue, driving considerable research into AI-driven detection approaches. While pre-trained models, particularly speech self-supervised models (SSL Models), have been applied to depression detection, they show unexpectedly poor performance without extensive data augmentation. Large Language Models (LLMs), despite their success across various domains, have not been explored in multi-modal depression detection. In this paper, we first establish an LLM-based system to investigate its potential in this task, uncovering fundamental limitations in handling multi-modal information. Through systematic analysis, we discover that the poor performance of pre-trained models stems from the conflation of high-level information, where high-level features derived from both content and speech are mixed within pre-trained models model representations, making it challenging to establish effective decision boundaries. To address this, we propose an information separation framework that disentangles these features, significantly improving the performance of both SSL models and LLMs in depression detection. Our experiments validate this finding and demonstrate that the integration of separated features yields substantial improvements over existing approaches, providing new insights for developing more effective multi-modal depression detection systems.
Auto-Landmark: Acoustic Landmark Dataset and Open-Source Toolkit for Landmark Extraction
Sep 12, 2024



In the speech signal, acoustic landmarks identify times when the acoustic manifestations of the linguistically motivated distinctive features are most salient. Acoustic landmarks have been widely applied in various domains, including speech recognition, speech depression detection, clinical analysis of speech abnormalities, and the detection of disordered speech. However, there is currently no dataset available that provides precise timing information for landmarks, which has been proven to be crucial for downstream applications involving landmarks. In this paper, we selected the most useful acoustic landmarks based on previous research and annotated the TIMIT dataset with them, based on a combination of phoneme boundary information and manual inspection. Moreover, previous landmark extraction tools were not open source or benchmarked, so to address this, we developed an open source Python-based landmark extraction tool and established a series of landmark detection baselines. The first of their kinds, the dataset with landmark precise timing information, landmark extraction tool and baselines are designed to support a wide variety of future research.
Rethinking Mamba in Speech Processing by Self-Supervised Models
Sep 11, 2024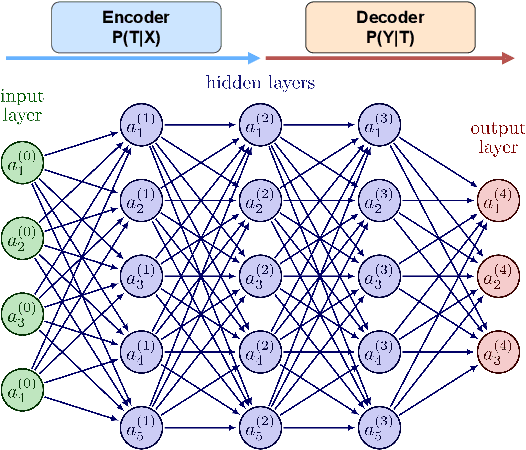
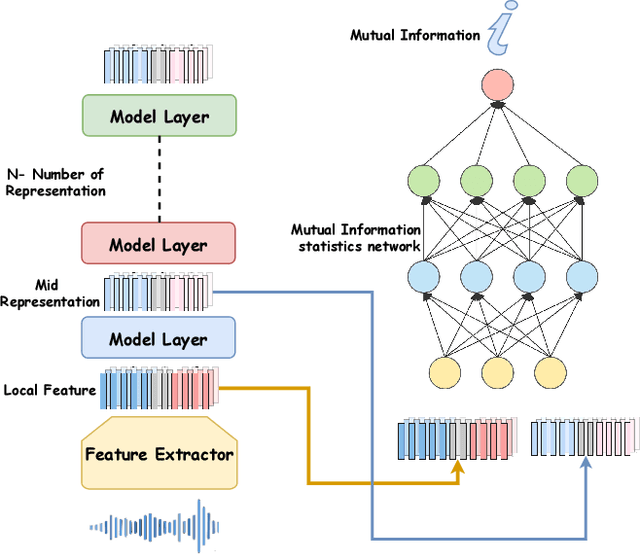
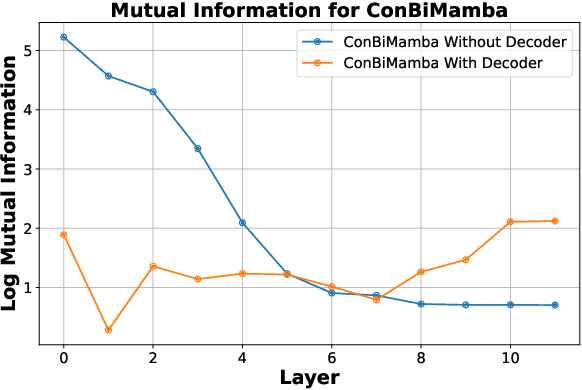
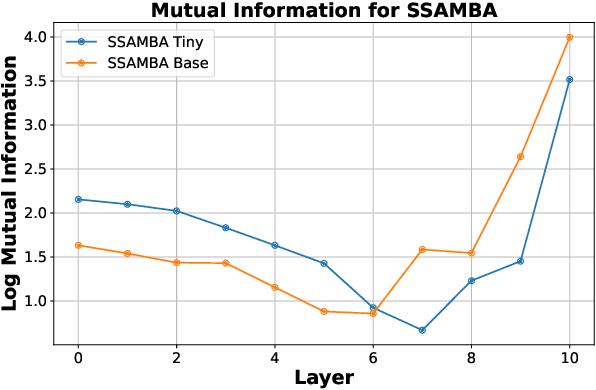
The Mamba-based model has demonstrated outstanding performance across tasks in computer vision, natural language processing, and speech processing. However, in the realm of speech processing, the Mamba-based model's performance varies across different tasks. For instance, in tasks such as speech enhancement and spectrum reconstruction, the Mamba model performs well when used independently. However, for tasks like speech recognition, additional modules are required to surpass the performance of attention-based models. We propose the hypothesis that the Mamba-based model excels in "reconstruction" tasks within speech processing. However, for "classification tasks" such as Speech Recognition, additional modules are necessary to accomplish the "reconstruction" step. To validate our hypothesis, we analyze the previous Mamba-based Speech Models from an information theory perspective. Furthermore, we leveraged the properties of HuBERT in our study. We trained a Mamba-based HuBERT model, and the mutual information patterns, along with the model's performance metrics, confirmed our assumptions.
Mamba in Speech: Towards an Alternative to Self-Attention
May 22, 2024



Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
When LLMs Meets Acoustic Landmarks: An Efficient Approach to Integrate Speech into Large Language Models for Depression Detection
Feb 17, 2024



Depression is a critical concern in global mental health, prompting extensive research into AI-based detection methods. Among various AI technologies, Large Language Models (LLMs) stand out for their versatility in mental healthcare applications. However, their primary limitation arises from their exclusive dependence on textual input, which constrains their overall capabilities. Furthermore, the utilization of LLMs in identifying and analyzing depressive states is still relatively untapped. In this paper, we present an innovative approach to integrating acoustic speech information into the LLMs framework for multimodal depression detection. We investigate an efficient method for depression detection by integrating speech signals into LLMs utilizing Acoustic Landmarks. By incorporating acoustic landmarks, which are specific to the pronunciation of spoken words, our method adds critical dimensions to text transcripts. This integration also provides insights into the unique speech patterns of individuals, revealing the potential mental states of individuals. Evaluations of the proposed approach on the DAIC-WOZ dataset reveal state-of-the-art results when compared with existing Audio-Text baselines. In addition, this approach is not only valuable for the detection of depression but also represents a new perspective in enhancing the ability of LLMs to comprehend and process speech signals.
Phonological Level wav2vec2-based Mispronunciation Detection and Diagnosis Method
Nov 13, 2023


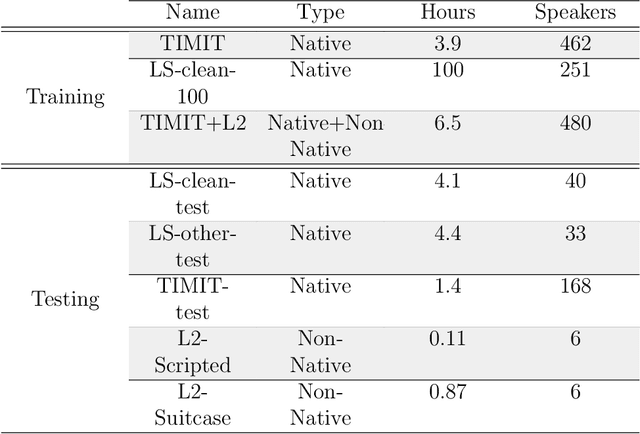
The automatic identification and analysis of pronunciation errors, known as Mispronunciation Detection and Diagnosis (MDD) plays a crucial role in Computer Aided Pronunciation Learning (CAPL) tools such as Second-Language (L2) learning or speech therapy applications. Existing MDD methods relying on analysing phonemes can only detect categorical errors of phonemes that have an adequate amount of training data to be modelled. With the unpredictable nature of the pronunciation errors of non-native or disordered speakers and the scarcity of training datasets, it is unfeasible to model all types of mispronunciations. Moreover, phoneme-level MDD approaches have a limited ability to provide detailed diagnostic information about the error made. In this paper, we propose a low-level MDD approach based on the detection of speech attribute features. Speech attribute features break down phoneme production into elementary components that are directly related to the articulatory system leading to more formative feedback to the learner. We further propose a multi-label variant of the Connectionist Temporal Classification (CTC) approach to jointly model the non-mutually exclusive speech attributes using a single model. The pre-trained wav2vec2 model was employed as a core model for the speech attribute detector. The proposed method was applied to L2 speech corpora collected from English learners from different native languages. The proposed speech attribute MDD method was further compared to the traditional phoneme-level MDD and achieved a significantly lower False Acceptance Rate (FAR), False Rejection Rate (FRR), and Diagnostic Error Rate (DER) over all speech attributes compared to the phoneme-level equivalent.
Spatial HuBERT: Self-supervised Spatial Speech Representation Learning for a Single Talker from Multi-channel Audio
Oct 17, 2023Self-supervised learning has been used to leverage unlabelled data, improving accuracy and generalisation of speech systems through the training of representation models. While many recent works have sought to produce effective representations across a variety of acoustic domains, languages, modalities and even simultaneous speakers, these studies have all been limited to single-channel audio recordings. This paper presents Spatial HuBERT, a self-supervised speech representation model that learns both acoustic and spatial information pertaining to a single speaker in a potentially noisy environment by using multi-channel audio inputs. Spatial HuBERT learns representations that outperform state-of-the-art single-channel speech representations on a variety of spatial downstream tasks, particularly in reverberant and noisy environments. We also demonstrate the utility of the representations learned by Spatial HuBERT on a speech localisation downstream task. Along with this paper, we publicly release a new dataset of 100 000 simulated first-order ambisonics room impulse responses.
Variational Connectionist Temporal Classification for Order-Preserving Sequence Modeling
Sep 21, 2023Connectionist temporal classification (CTC) is commonly adopted for sequence modeling tasks like speech recognition, where it is necessary to preserve order between the input and target sequences. However, CTC is only applied to deterministic sequence models, where the latent space is discontinuous and sparse, which in turn makes them less capable of handling data variability when compared to variational models. In this paper, we integrate CTC with a variational model and derive loss functions that can be used to train more generalizable sequence models that preserve order. Specifically, we derive two versions of the novel variational CTC based on two reasonable assumptions, the first being that the variational latent variables at each time step are conditionally independent; and the second being that these latent variables are Markovian. We show that both loss functions allow direct optimization of the variational lower bound for the model log-likelihood, and present computationally tractable forms for implementing them.
Improving Children's Speech Recognition by Fine-tuning Self-supervised Adult Speech Representations
Nov 14, 2022Children's speech recognition is a vital, yet largely overlooked domain when building inclusive speech technologies. The major challenge impeding progress in this domain is the lack of adequate child speech corpora; however, recent advances in self-supervised learning have created a new opportunity for overcoming this problem of data scarcity. In this paper, we leverage self-supervised adult speech representations and use three well-known child speech corpora to build models for children's speech recognition. We assess the performance of fine-tuning on both native and non-native children's speech, examine the effect of cross-domain child corpora, and investigate the minimum amount of child speech required to fine-tune a model which outperforms a state-of-the-art adult model. We also analyze speech recognition performance across children's ages. Our results demonstrate that fine-tuning with cross-domain child corpora leads to relative improvements of up to 46.08% and 45.53% for native and non-native child speech respectively, and absolute improvements of 14.70% and 31.10%. We also show that with as little as 5 hours of transcribed children's speech, it is possible to fine-tune a children's speech recognition system that outperforms a state-of-the-art adult model fine-tuned on 960 hours of adult speech.