 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinds versus Machines: Rethinking Entailment Verification with Language Models
Feb 06, 2024Humans make numerous inferences in text comprehension to understand discourse. This paper aims to understand the commonalities and disparities in the inference judgments between humans and state-of-the-art Large Language Models (LLMs). Leveraging a comprehensively curated entailment verification benchmark, we evaluate both human and LLM performance across various reasoning categories. Our benchmark includes datasets from three categories (NLI, contextual QA, and rationales) that include multi-sentence premises and different knowledge types, thereby evaluating the inference capabilities in complex reasoning instances. Notably, our findings reveal LLMs' superiority in multi-hop reasoning across extended contexts, while humans excel in tasks necessitating simple deductive reasoning. Leveraging these insights, we introduce a fine-tuned Flan-T5 model that outperforms GPT-3.5 and rivals with GPT-4, offering a robust open-source solution for entailment verification. As a practical application, we showcase the efficacy of our finetuned model in enhancing self-consistency in model-generated explanations, resulting in a 6% performance boost on average across three multiple-choice question-answering datasets.
SCORE: A framework for Self-Contradictory Reasoning Evaluation
Nov 16, 2023



Large language models (LLMs) have demonstrated impressive reasoning ability in various language-based tasks. Despite many proposed reasoning methods aimed at enhancing performance in downstream tasks, two fundamental questions persist: Does reasoning genuinely support predictions, and how reliable is the quality of reasoning? In this paper, we propose a framework \textsc{SCORE} to analyze how well LLMs can reason. Specifically, we focus on self-contradictory reasoning, where reasoning does not support the prediction. We find that LLMs often contradict themselves when performing reasoning tasks that involve contextual information and commonsense. The model may miss evidence or use shortcuts, thereby exhibiting self-contradictory behaviors. We also employ the Point-of-View (POV) method, which probes models to generate reasoning from multiple perspectives, as a diagnostic tool for further analysis. We find that though LLMs may appear to perform well in one-perspective settings, they fail to stabilize such behavior in multi-perspectives settings. Even for correct predictions, the reasoning may be messy and incomplete, and LLMs can easily be led astray from good reasoning. \textsc{SCORE}'s results underscore the lack of robustness required for trustworthy reasoning and the urgency for further research to establish best practices for a comprehensive evaluation of reasoning beyond accuracy-based metrics.
Faith and Fate: Limits of Transformers on Compositionality
Jun 01, 2023



Transformer large language models (LLMs) have sparked admiration for their exceptional performance on tasks that demand intricate multi-step reasoning. Yet, these models simultaneously show failures on surprisingly trivial problems. This begs the question: Are these errors incidental, or do they signal more substantial limitations? In an attempt to demystify Transformers, we investigate the limits of these models across three representative compositional tasks -- multi-digit multiplication, logic grid puzzles, and a classic dynamic programming problem. These tasks require breaking problems down into sub-steps and synthesizing these steps into a precise answer. We formulate compositional tasks as computation graphs to systematically quantify the level of complexity, and break down reasoning steps into intermediate sub-procedures. Our empirical findings suggest that Transformers solve compositional tasks by reducing multi-step compositional reasoning into linearized subgraph matching, without necessarily developing systematic problem-solving skills. To round off our empirical study, we provide theoretical arguments on abstract multi-step reasoning problems that highlight how Transformers' performance will rapidly decay with increased task complexity.
PlaSma: Making Small Language Models Better Procedural Knowledge Models for (Counterfactual) Planning
May 31, 2023



Procedural planning, which entails decomposing a high-level goal into a sequence of temporally ordered steps, is an important yet intricate task for machines. It involves integrating common-sense knowledge to reason about complex contextualized situations that are often counterfactual, e.g. "scheduling a doctor's appointment without a phone". While current approaches show encouraging results using large language models (LLMs), they are hindered by drawbacks such as costly API calls and reproducibility issues. In this paper, we advocate planning using smaller language models. We present PlaSma, a novel two-pronged approach to endow small language models with procedural knowledge and (counterfactual) planning capabilities. More concretely, we develop symbolic procedural knowledge distillation to enhance the implicit knowledge in small language models and an inference-time algorithm to facilitate more structured and accurate reasoning. In addition, we introduce a novel task, Counterfactual Planning, that requires a revision of a plan to cope with a counterfactual situation. In both the original and counterfactual setting, we show that orders-of-magnitude smaller models (770M-11B parameters) can compete and often surpass their larger teacher models' capabilities.
APOLLO: A Simple Approach for Adaptive Pretraining of Language Models for Logical Reasoning
Dec 19, 2022



Logical reasoning of text is an important ability that requires understanding the information present in the text, their interconnections, and then reasoning through them to infer new conclusions. Prior works on improving the logical reasoning ability of language models require complex processing of training data (e.g., aligning symbolic knowledge to text), yielding task-specific data augmentation solutions that restrict the learning of general logical reasoning skills. In this work, we propose APOLLO, an adaptively pretrained language model that has improved logical reasoning abilities. We select a subset of Wikipedia, based on a set of logical inference keywords, for continued pretraining of a language model. We use two self-supervised loss functions: a modified masked language modeling loss where only specific parts-of-speech words, that would likely require more reasoning than basic language understanding, are masked, and a sentence-level classification loss that teaches the model to distinguish between entailment and contradiction types of sentences. The proposed training paradigm is both simple and independent of task formats. We demonstrate the effectiveness of APOLLO by comparing it with prior baselines on two logical reasoning datasets. APOLLO performs comparably on ReClor and outperforms baselines on LogiQA.
Generate rather than Retrieve: Large Language Models are Strong Context Generators
Sep 29, 2022
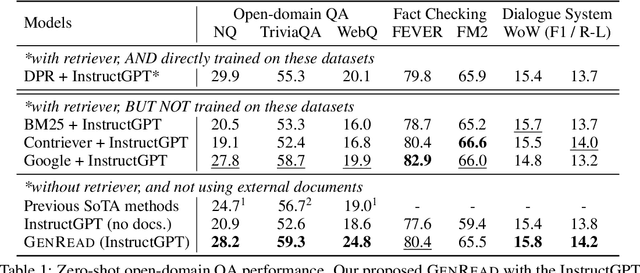
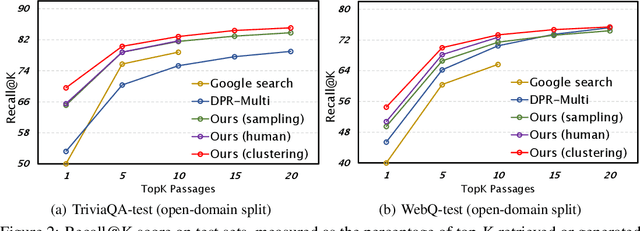
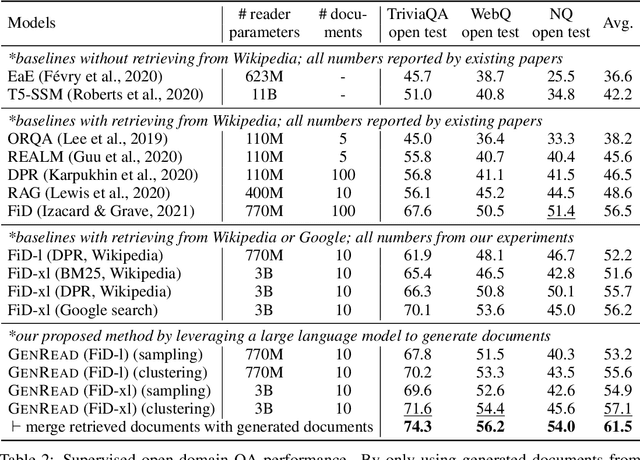
Knowledge-intensive tasks, such as open-domain question answering (QA), require access to a large amount of world or domain knowledge. A common approach for knowledge-intensive tasks is to employ a retrieve-then-read pipeline that first retrieves a handful of relevant contextual documents from an external corpus such as Wikipedia and then predicts an answer conditioned on the retrieved documents. In this paper, we present a novel perspective for solving knowledge-intensive tasks by replacing document retrievers with large language model generators. We call our method generate-then-read (GenRead), which first prompts a large language model to generate contextutal documents based on a given question, and then reads the generated documents to produce the final answer. Furthermore, we propose a novel clustering-based prompting method that selects distinct prompts, resulting in the generated documents that cover different perspectives, leading to better recall over acceptable answers. We conduct extensive experiments on three different knowledge-intensive tasks, including open-domain QA, fact checking, and dialogue system. Notably, GenRead achieves 71.6 and 54.4 exact match scores on TriviaQA and WebQ, significantly outperforming the state-of-the-art retrieve-then-read pipeline DPR-FiD by +4.0 and +3.9, without retrieving any documents from any external knowledge source. Lastly, we demonstrate the model performance can be further improved by combining retrieval and generation.
RobustLR: Evaluating Robustness to Logical Perturbation in Deductive Reasoning
May 25, 2022
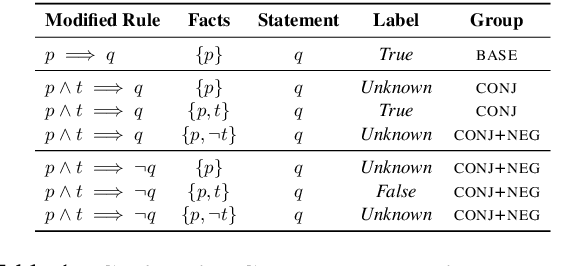

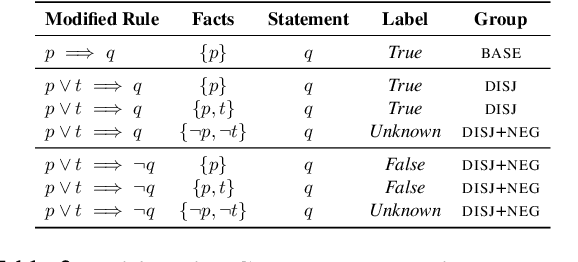
Transformers have been shown to be able to perform deductive reasoning on a logical rulebase containing rules and statements written in English natural language. While the progress is promising, it is currently unclear if these models indeed perform logical reasoning by understanding the underlying logical semantics in the language. To this end, we propose RobustLR, a suite of evaluation datasets that evaluate the robustness of these models to minimal logical edits in rulebases and some standard logical equivalence conditions. In our experiments with RoBERTa and T5, we find that the models trained in prior works do not perform consistently on the different perturbations in RobustLR, thus showing that the models are not robust to the proposed logical perturbations. Further, we find that the models find it especially hard to learn logical negation and disjunction operators. Overall, using our evaluation sets, we demonstrate some shortcomings of the deductive reasoning-based language models, which can eventually help towards designing better models for logical reasoning over natural language.
FaiRR: Faithful and Robust Deductive Reasoning over Natural Language
Mar 19, 2022
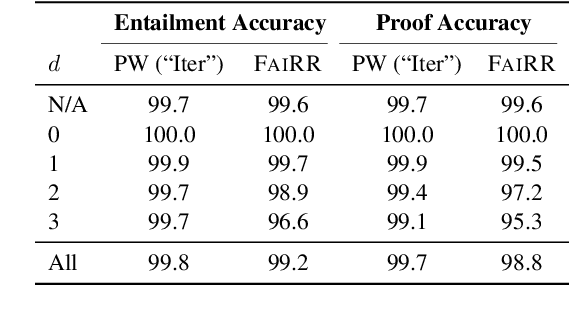
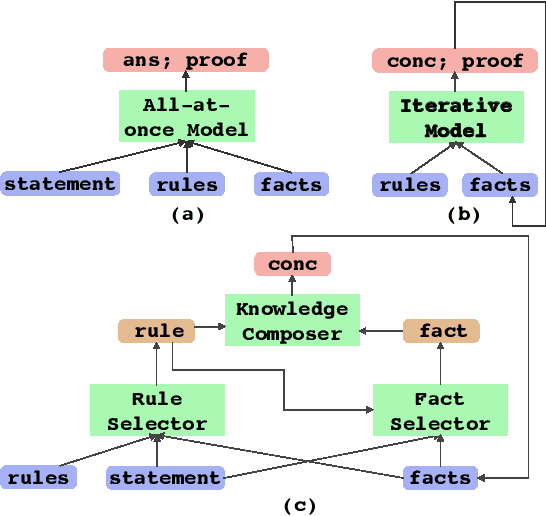
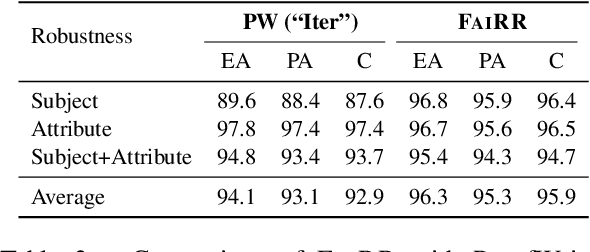
Transformers have been shown to be able to perform deductive reasoning on a logical rulebase containing rules and statements written in natural language. Recent works show that such models can also produce the reasoning steps (i.e., the proof graph) that emulate the model's logical reasoning process. Currently, these black-box models generate both the proof graph and intermediate inferences within the same model and thus may be unfaithful. In this work, we frame the deductive logical reasoning task by defining three modular components: rule selection, fact selection, and knowledge composition. The rule and fact selection steps select the candidate rule and facts to be used and then the knowledge composition combines them to generate new inferences. This ensures model faithfulness by assured causal relation from the proof step to the inference reasoning. To test our framework, we propose FaiRR (Faithful and Robust Reasoner) where the above three components are independently modeled by transformers. We observe that FaiRR is robust to novel language perturbations, and is faster at inference than previous works on existing reasoning datasets. Additionally, in contrast to black-box generative models, the errors made by FaiRR are more interpretable due to the modular approach.
Discretized Integrated Gradients for Explaining Language Models
Aug 31, 2021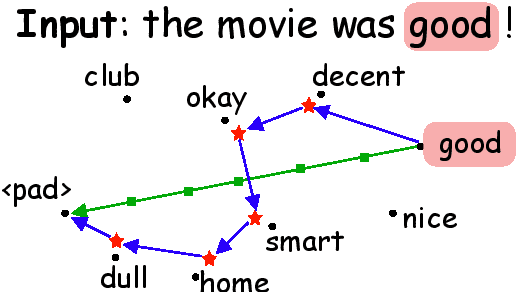
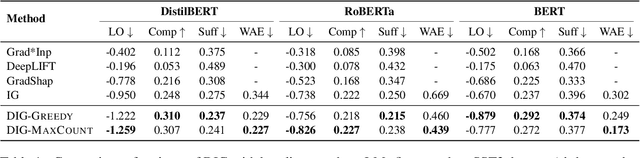
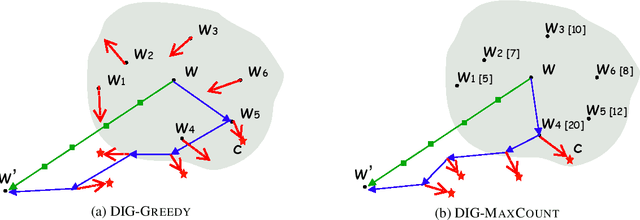
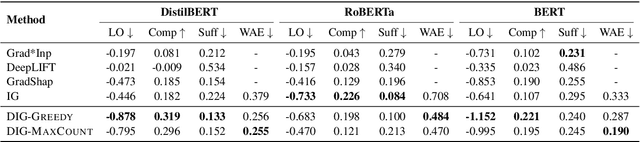
As a prominent attribution-based explanation algorithm, Integrated Gradients (IG) is widely adopted due to its desirable explanation axioms and the ease of gradient computation. It measures feature importance by averaging the model's output gradient interpolated along a straight-line path in the input data space. However, such straight-line interpolated points are not representative of text data due to the inherent discreteness of the word embedding space. This questions the faithfulness of the gradients computed at the interpolated points and consequently, the quality of the generated explanations. Here we propose Discretized Integrated Gradients (DIG), which allows effective attribution along non-linear interpolation paths. We develop two interpolation strategies for the discrete word embedding space that generates interpolation points that lie close to actual words in the embedding space, yielding more faithful gradient computation. We demonstrate the effectiveness of DIG over IG through experimental and human evaluations on multiple sentiment classification datasets. We provide the source code of DIG to encourage reproducible research.
SalKG: Learning From Knowledge Graph Explanations for Commonsense Reasoning
Apr 18, 2021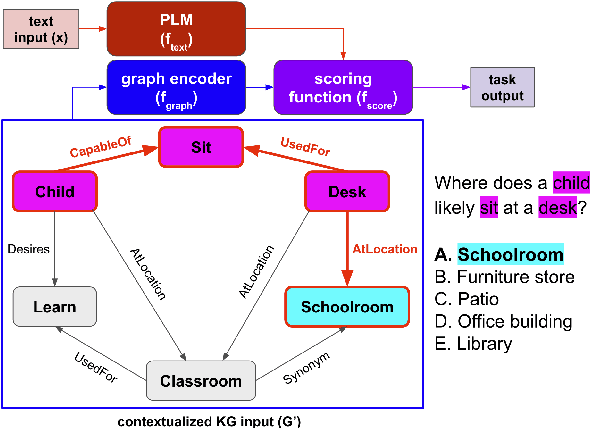

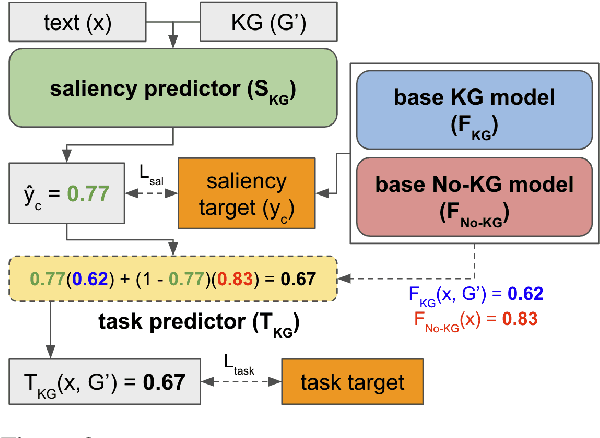
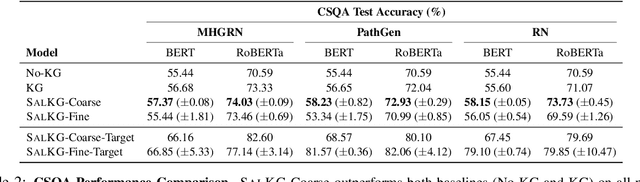
Augmenting pre-trained language models with knowledge graphs (KGs) has achieved success on various commonsense reasoning tasks. Although some works have attempted to explain the behavior of such KG-augmented models by indicating which KG inputs are salient (i.e., important for the model's prediction), it is not always clear how these explanations should be used to make the model better. In this paper, we explore whether KG explanations can be used as supervision for teaching these KG-augmented models how to filter out unhelpful KG information. To this end, we propose SalKG, a simple framework for learning from KG explanations of both coarse (Is the KG salient?) and fine (Which parts of the KG are salient?) granularity. Given the explanations generated from a task's training set, SalKG trains KG-augmented models to solve the task by focusing on KG information highlighted by the explanations as salient. Across two popular commonsense QA benchmarks and three KG-augmented models, we find that SalKG's training process can consistently improve model performance.