 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustLR: Evaluating Robustness to Logical Perturbation in Deductive Reasoning
Paper and Code

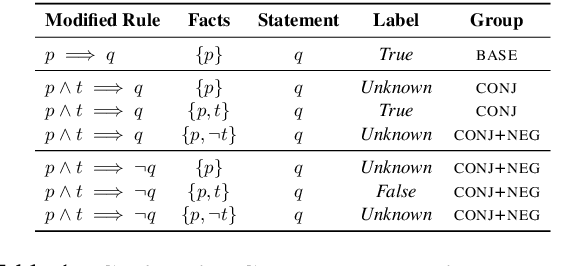

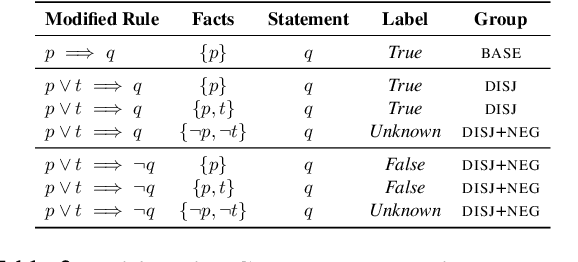
Transformers have been shown to be able to perform deductive reasoning on a logical rulebase containing rules and statements written in English natural language. While the progress is promising, it is currently unclear if these models indeed perform logical reasoning by understanding the underlying logical semantics in the language. To this end, we propose RobustLR, a suite of evaluation datasets that evaluate the robustness of these models to minimal logical edits in rulebases and some standard logical equivalence conditions. In our experiments with RoBERTa and T5, we find that the models trained in prior works do not perform consistently on the different perturbations in RobustLR, thus showing that the models are not robust to the proposed logical perturbations. Further, we find that the models find it especially hard to learn logical negation and disjunction operators. Overall, using our evaluation sets, we demonstrate some shortcomings of the deductive reasoning-based language models, which can eventually help towards designing better models for logical reasoning over natural language.