 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal LLMs Do Not Compose Skills Optimally Across Modalities
Nov 12, 2025



Skill composition is the ability to combine previously learned skills to solve new tasks. As neural networks acquire increasingly complex skills during their pretraining, it is not clear how successfully they can compose them. In this paper, we focus on Multimodal Large Language Models (MLLM), and study their ability to compose skills across modalities. To this end, we design three evaluation tasks which can be solved sequentially composing two modality-dependent skills, and evaluate several open MLLMs under two main settings: i) prompting the model to directly solve the task, and ii) using a two-step cascaded inference approach, which manually enforces the composition of the two skills for a given task. Even with these straightforward compositions, we find that all evaluated MLLMs exhibit a significant cross-modality skill composition gap. To mitigate the aforementioned gap, we explore two alternatives: i) use chain-of-thought prompting to explicitly instruct MLLMs for skill composition and ii) a specific fine-tuning recipe to promote skill composition. Although those strategies improve model performance, they still exhibit significant skill composition gaps, suggesting that more research is needed to improve cross-modal skill composition in MLLMs.
Improving the Efficiency of Visually Augmented Language Models
Sep 17, 2024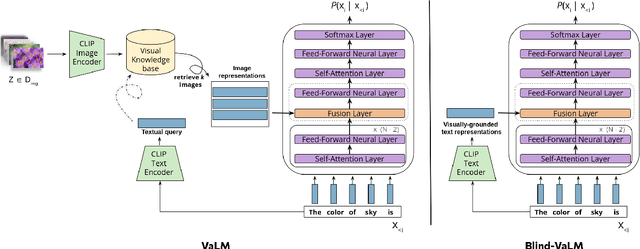
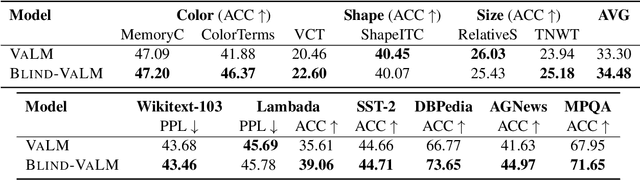
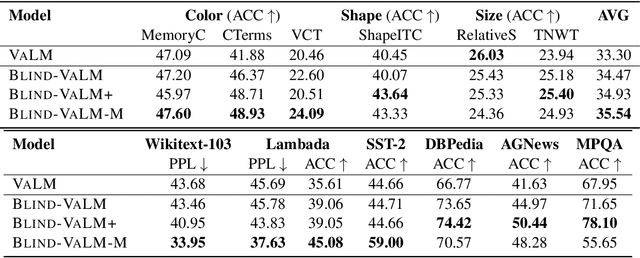

Despite the impressive performance of autoregressive Language Models (LM) it has been shown that due to reporting bias, LMs lack visual knowledge, i.e. they do not know much about the visual world and its properties. To augment LMs with visual knowledge, existing solutions often rely on explicit images, requiring time-consuming retrieval or image generation systems. This paper shows that explicit images are not necessary to visually augment an LM. Instead, we use visually-grounded text representations obtained from the well-known CLIP multimodal system. For a fair comparison, we modify VALM, a visually-augmented LM which uses image retrieval and representation, to work directly with visually-grounded text representations. We name this new model BLIND-VALM. We show that BLIND-VALM performs on par with VALM for Visual Language Understanding (VLU), Natural Language Understanding (NLU) and Language Modeling tasks, despite being significantly more efficient and simpler. We also show that scaling up our model within the compute budget of VALM, either increasing the model or pre-training corpus size, we outperform VALM for all the evaluation tasks.
Vibe-Eval: A hard evaluation suite for measuring progress of multimodal language models
May 03, 2024
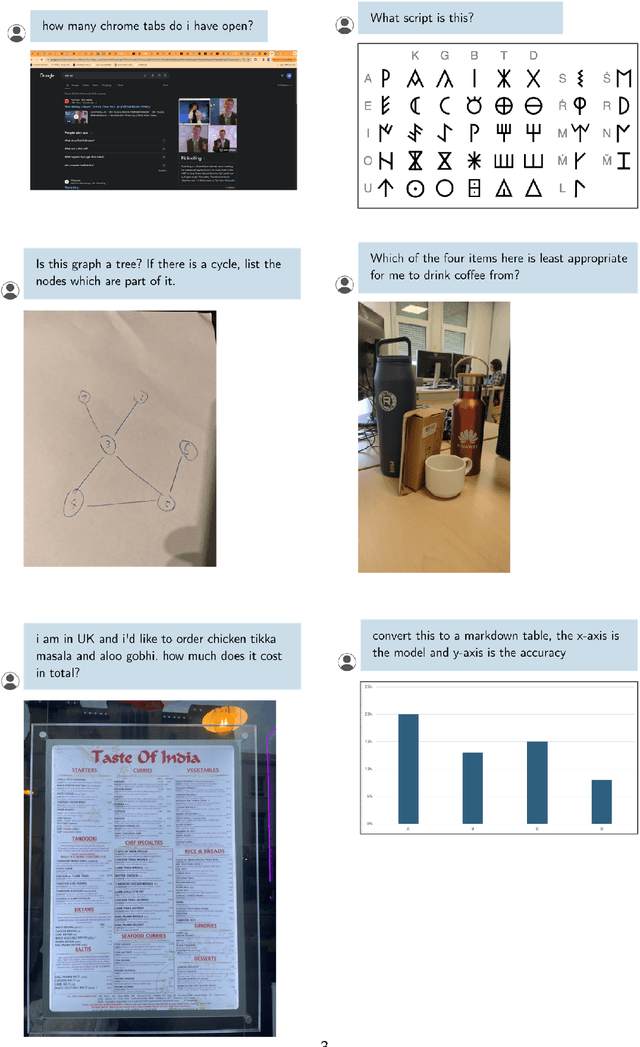
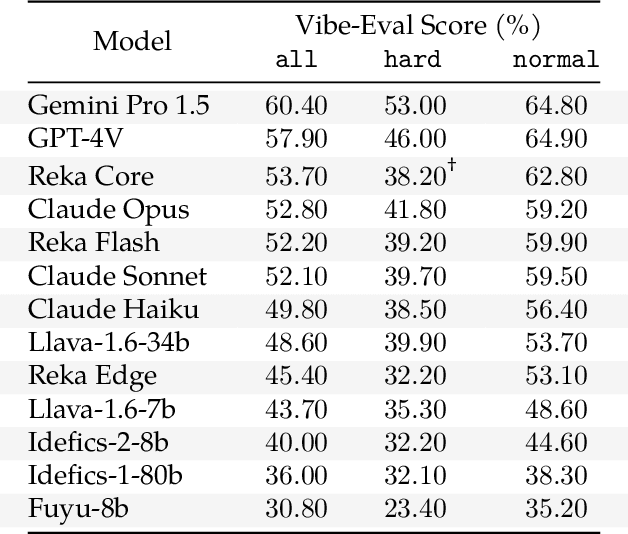
We introduce Vibe-Eval: a new open benchmark and framework for evaluating multimodal chat models. Vibe-Eval consists of 269 visual understanding prompts, including 100 of hard difficulty, complete with gold-standard responses authored by experts. Vibe-Eval is open-ended and challenging with dual objectives: (i) vibe checking multimodal chat models for day-to-day tasks and (ii) rigorously testing and probing the capabilities of present frontier models. Notably, our hard set contains >50% questions that all frontier models answer incorrectly. We explore the nuances of designing, evaluating, and ranking models on ultra challenging prompts. We also discuss trade-offs between human and automatic evaluation, and show that automatic model evaluation using Reka Core roughly correlates to human judgment. We offer free API access for the purpose of lightweight evaluation and plan to conduct formal human evaluations for public models that perform well on the Vibe-Eval's automatic scores. We release the evaluation code and data, see https://github.com/reka-ai/reka-vibe-eval
Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models
Apr 18, 2024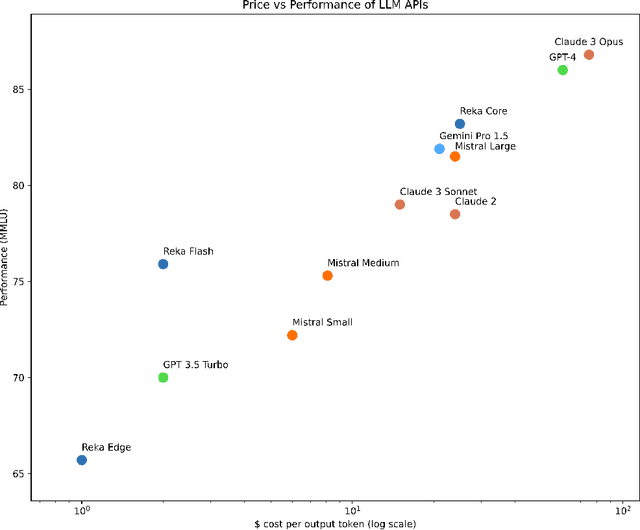


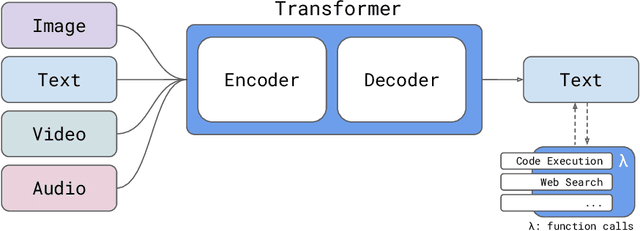
We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs. This technical report discusses details of training some of these models and provides comprehensive evaluation results. We show that Reka Edge and Reka Flash are not only state-of-the-art but also outperform many much larger models, delivering outsized values for their respective compute class. Meanwhile, our most capable and largest model, Reka Core, approaches the best frontier models on both automatic evaluations and blind human evaluations. On image question answering benchmarks (e.g. MMMU, VQAv2), Core performs competitively to GPT4-V. Meanwhile, on multimodal chat, Core ranks as the second most preferred model under a blind third-party human evaluation setup, outperforming other models such as Claude 3 Opus. On text benchmarks, Core not only performs competitively to other frontier models on a set of well-established benchmarks (e.g. MMLU, GSM8K) but also outperforms GPT4-0613 on human evaluation. On video question answering (Perception-Test), Core outperforms Gemini Ultra. Models are shipped in production at http://chat.reka.ai . A showcase of non cherry picked qualitative examples can also be found at http://showcase.reka.ai .
Latxa: An Open Language Model and Evaluation Suite for Basque
Mar 29, 2024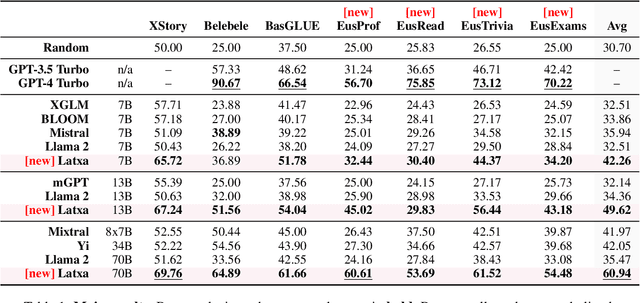
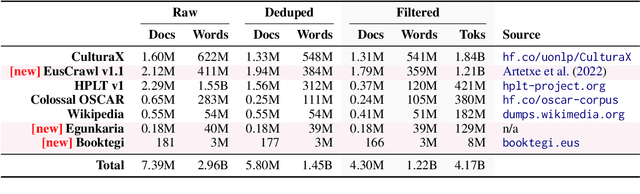
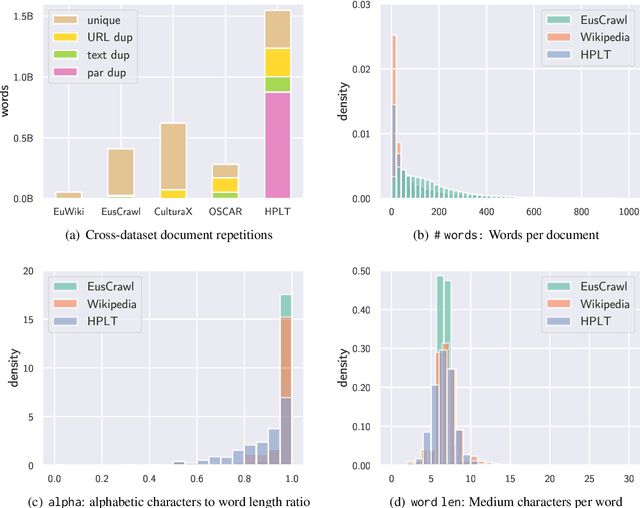
We introduce Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque corpus comprising 4.3M documents and 4.2B tokens. Addressing the scarcity of high-quality benchmarks for Basque, we further introduce 4 multiple choice evaluation datasets: EusProficiency, comprising 5,169 questions from official language proficiency exams; EusReading, comprising 352 reading comprehension questions; EusTrivia, comprising 1,715 trivia questions from 5 knowledge areas; and EusExams, comprising 16,774 questions from public examinations. In our extensive evaluation, Latxa outperforms all previous open models we compare to by a large margin. In addition, it is competitive with GPT-4 Turbo in language proficiency and understanding, despite lagging behind in reading comprehension and knowledge-intensive tasks. Both the Latxa family of models, as well as our new pretraining corpora and evaluation datasets, are publicly available under open licenses at https://github.com/hitz-zentroa/latxa. Our suite enables reproducible research on methods to build LLMs for low-resource languages.
Erato: Automatizing Poetry Evaluation
Oct 31, 2023We present Erato, a framework designed to facilitate the automated evaluation of poetry, including that generated by poetry generation systems. Our framework employs a diverse set of features, and we offer a brief overview of Erato's capabilities and its potential for expansion. Using Erato, we compare and contrast human-authored poetry with automatically-generated poetry, demonstrating its effectiveness in identifying key differences. Our implementation code and software are freely available under the GNU GPLv3 license.
CombLM: Adapting Black-Box Language Models through Small Fine-Tuned Models
May 23, 2023
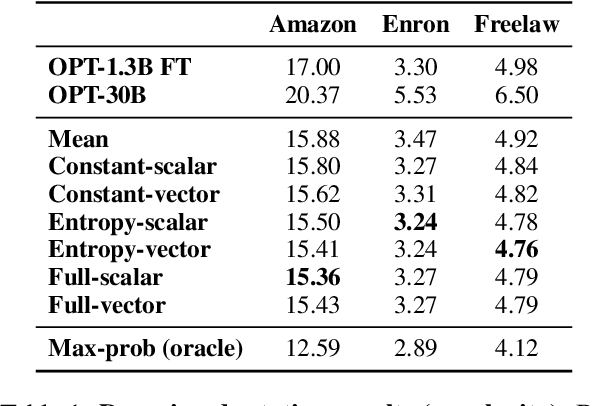


Methods for adapting language models (LMs) to new tasks and domains have traditionally assumed white-box access to the model, and work by modifying its parameters. However, this is incompatible with a recent trend in the field, where the highest quality models are only available as black-boxes through inference APIs. Even when the model weights are available, the computational cost of fine-tuning large LMs can be prohibitive for most practitioners. In this work, we present a lightweight method for adapting large LMs to new domains and tasks, assuming no access to their weights or intermediate activations. Our approach fine-tunes a small white-box LM and combines it with the large black-box LM at the probability level through a small network, learned on a small validation set. We validate our approach by adapting a large LM (OPT-30B) to several domains and a downstream task (machine translation), observing improved performance in all cases, of up to 9%, while using a domain expert 23x smaller.
Principled Paraphrase Generation with Parallel Corpora
May 24, 2022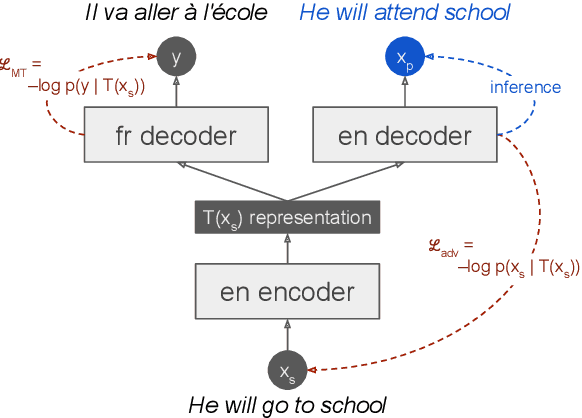
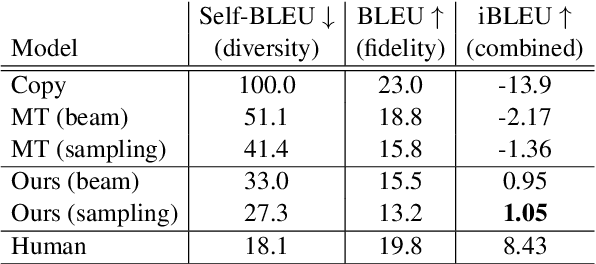

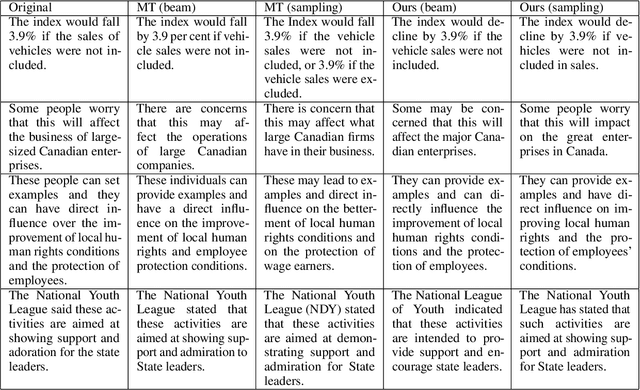
Round-trip Machine Translation (MT) is a popular choice for paraphrase generation, which leverages readily available parallel corpora for supervision. In this paper, we formalize the implicit similarity function induced by this approach, and show that it is susceptible to non-paraphrase pairs sharing a single ambiguous translation. Based on these insights, we design an alternative similarity metric that mitigates this issue by requiring the entire translation distribution to match, and implement a relaxation of it through the Information Bottleneck method. Our approach incorporates an adversarial term into MT training in order to learn representations that encode as much information about the reference translation as possible, while keeping as little information about the input as possible. Paraphrases can be generated by decoding back to the source from this representation, without having to generate pivot translations. In addition to being more principled and efficient than round-trip MT, our approach offers an adjustable parameter to control the fidelity-diversity trade-off, and obtains better results in our experiments.
PoeLM: A Meter- and Rhyme-Controllable Language Model for Unsupervised Poetry Generation
May 24, 2022

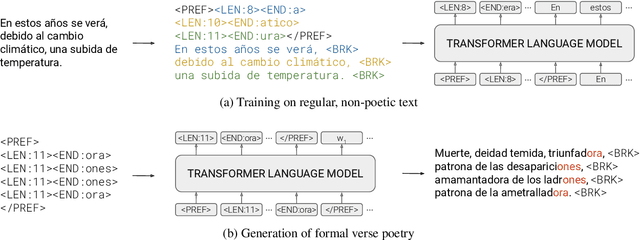
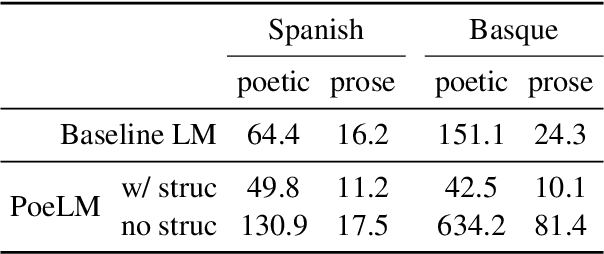
Formal verse poetry imposes strict constraints on the meter and rhyme scheme of poems. Most prior work on generating this type of poetry uses existing poems for supervision, which are difficult to obtain for most languages and poetic forms. In this work, we propose an unsupervised approach to generate poems following any given meter and rhyme scheme, without requiring any poetic text for training. Our method works by splitting a regular, non-poetic corpus into phrases, prepending control codes that describe the length and end rhyme of each phrase, and training a transformer language model in the augmented corpus. During inference, we build control codes for the desired meter and rhyme scheme, and condition our language model on them to generate formal verse poetry. Experiments in Spanish and Basque show that our approach is able to generate valid poems, which are often comparable in quality to those written by humans.
Beyond Offline Mapping: Learning Cross Lingual Word Embeddings through Context Anchoring
Dec 31, 2020
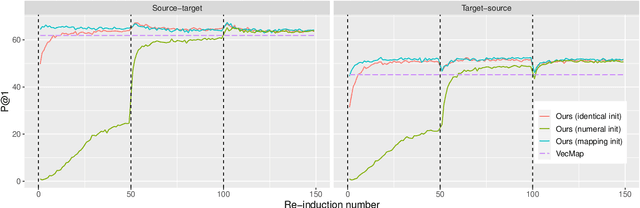


Recent research on cross-lingual word embeddings has been dominated by unsupervised mapping approaches that align monolingual embeddings. Such methods critically rely on those embeddings having a similar structure, but it was recently shown that the separate training in different languages causes departures from this assumption. In this paper, we propose an alternative approach that does not have this limitation, while requiring a weak seed dictionary (e.g., a list of identical words) as the only form of supervision. Rather than aligning two fixed embedding spaces, our method works by fixing the target language embeddings, and learning a new set of embeddings for the source language that are aligned with them. To that end, we use an extension of skip-gram that leverages translated context words as anchor points, and incorporates self-learning and iterative restarts to reduce the dependency on the initial dictionary. Our approach outperforms conventional mapping methods on bilingual lexicon induction, and obtains competitive results in the downstream XNLI task.