 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating an Aligned Corpus of Sound and Text: The Multimodal Corpus of Shakespeare and Milton
Jul 26, 2024In this work we present a corpus of poems by William Shakespeare and John Milton that have been enriched with readings from the public domain. We have aligned all the lines with their respective audio segments, at the line, word, syllable and phone level, and we have included their scansion. We make a basic visualization platform for these poems and we conclude by conjecturing possible future directions.
Erato: Automatizing Poetry Evaluation
Oct 31, 2023We present Erato, a framework designed to facilitate the automated evaluation of poetry, including that generated by poetry generation systems. Our framework employs a diverse set of features, and we offer a brief overview of Erato's capabilities and its potential for expansion. Using Erato, we compare and contrast human-authored poetry with automatically-generated poetry, demonstrating its effectiveness in identifying key differences. Our implementation code and software are freely available under the GNU GPLv3 license.
KUCST at CheckThat 2023: How good can we be with a generic model?
Jun 15, 2023In this paper we present our method for tasks 2 and 3A at the CheckThat2023 shared task. We make use of a generic approach that has been used to tackle a diverse set of tasks, inspired by authorship attribution and profiling. We train a number of Machine Learning models and our results show that Gradient Boosting performs the best for both tasks. Based on the official ranking provided by the shared task organizers, our model shows an average performance compared to other teams.
PoeLM: A Meter- and Rhyme-Controllable Language Model for Unsupervised Poetry Generation
May 24, 2022

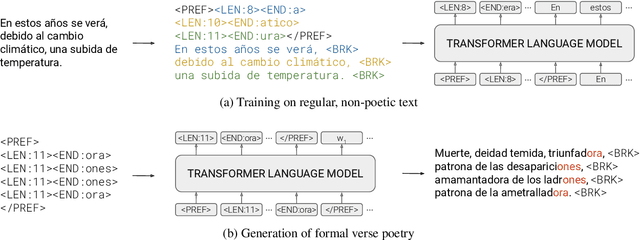
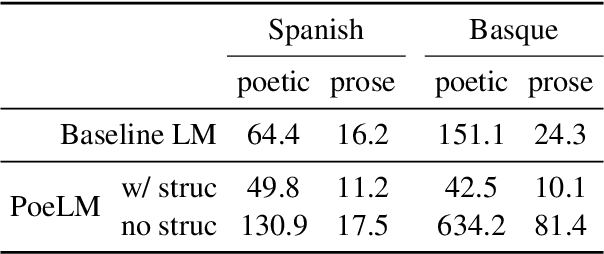
Formal verse poetry imposes strict constraints on the meter and rhyme scheme of poems. Most prior work on generating this type of poetry uses existing poems for supervision, which are difficult to obtain for most languages and poetic forms. In this work, we propose an unsupervised approach to generate poems following any given meter and rhyme scheme, without requiring any poetic text for training. Our method works by splitting a regular, non-poetic corpus into phrases, prepending control codes that describe the length and end rhyme of each phrase, and training a transformer language model in the augmented corpus. During inference, we build control codes for the desired meter and rhyme scheme, and condition our language model on them to generate formal verse poetry. Experiments in Spanish and Basque show that our approach is able to generate valid poems, which are often comparable in quality to those written by humans.
KUCST@LT-EDI-ACL2022: Detecting Signs of Depression from Social Media Text
Apr 09, 2022
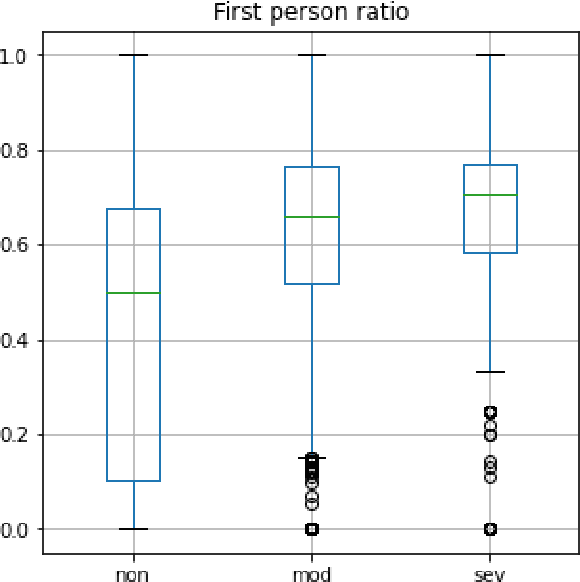
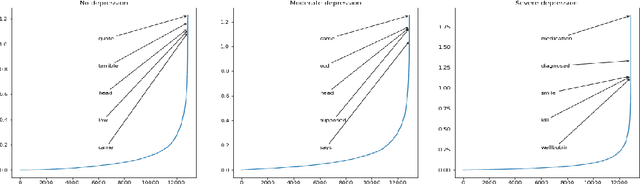
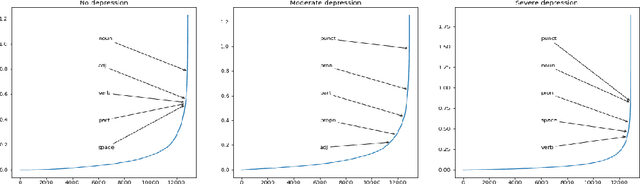
In this paper we present our approach for detecting signs of depression from social media text. Our model relies on word unigrams, part-of-speech tags, readabilitiy measures and the use of first, second or third person and the number of words. Our best model obtained a macro F1-score of 0.439 and ranked 25th, out of 31 teams. We further take advantage of the interpretability of the Logistic Regression model and we make an attempt to interpret the model coefficients with the hope that these will be useful for further research on the topic.
Fashion Style Generation: Evolutionary Search with Gaussian Mixture Models in the Latent Space
Apr 04, 2022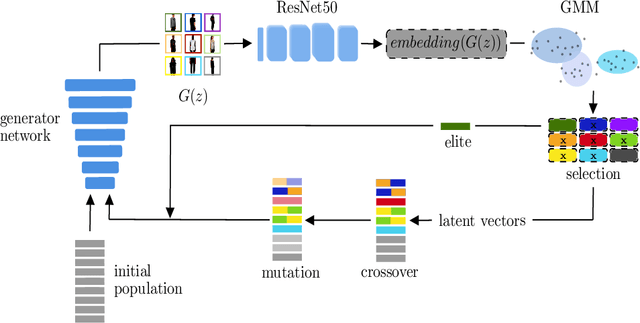

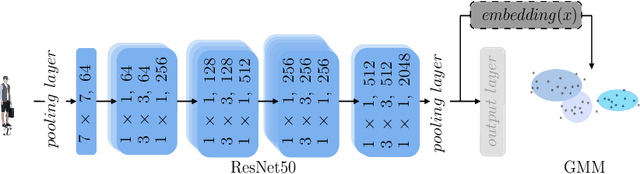

This paper presents a novel approach for guiding a Generative Adversarial Network trained on the FashionGen dataset to generate designs corresponding to target fashion styles. Finding the latent vectors in the generator's latent space that correspond to a style is approached as an evolutionary search problem. A Gaussian mixture model is applied to identify fashion styles based on the higher-layer representations of outfits in a clothing-specific attribute prediction model. Over generations, a genetic algorithm optimizes a population of designs to increase their probability of belonging to one of the Gaussian mixture components or styles. Showing that the developed system can generate images of maximum fitness visually resembling certain styles, our approach provides a promising direction to guide the search for style-coherent designs.
From meaning to perception -- exploring the space between word and odor perception embeddings
Mar 19, 2022
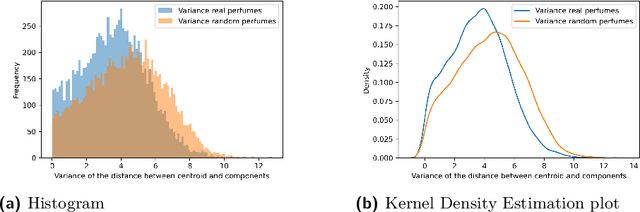


In this paper we propose the use of the Word2vec algorithm in order to obtain odor perception embeddings (or smell embeddings), only using publicly available perfume descriptions. Besides showing meaningful similarity relationships among each other, these embeddings also demonstrate to possess some shared information with their respective word embeddings. The meaningfulness of these embeddings suggests that aesthetics might provide enough constraints for using algorithms motivated by distributional semantics on non-randomly combined data. Furthermore, they provide possibilities for new ways of classifying odors and analyzing perfumes. We have also employed the embeddings in an attempt to understand the aesthetic nature of perfumes, based on the difference between real and randomly generated perfumes. In an additional tentative experiment we explore the possibility of a mapping between the word embedding space and the odor perception embedding space by fitting a regressor on the shared vocabulary and then predict the odor perception embeddings of words without an a priori associated smell, such as night or sky.
The Flipped Classroom model for teaching Conditional Random Fields in an NLP course
May 04, 2021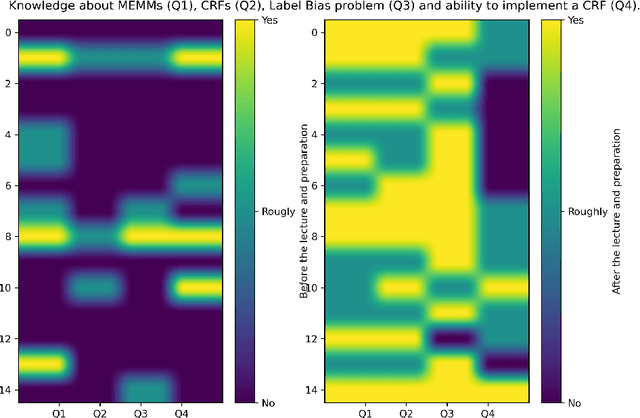
In this article, we show and discuss our experience in applying the flipped classroom method for teaching Conditional Random Fields in a Natural Language Processing course. We present the activities that we developed together with their relationship to a cognitive complexity model (Bloom's taxonomy). After this, we provide our own reflections and expectations of the model itself. Based on the evaluation got from students, it seems that students learn about the topic and also that the method is rewarding for some students. Additionally, we discuss some shortcomings and we propose possible solutions to them. We conclude the paper with some possible future work.
A Comparison of Feature-Based and Neural Scansion of Poetry
Nov 02, 2017Automatic analysis of poetic rhythm is a challenging task that involves linguistics, literature, and computer science. When the language to be analyzed is known, rule-based systems or data-driven methods can be used. In this paper, we analyze poetic rhythm in English and Spanish. We show that the representations of data learned from character-based neural models are more informative than the ones from hand-crafted features, and that a Bi-LSTM+CRF-model produces state-of-the art accuracy on scansion of poetry in two languages. Results also show that the information about whole word structure, and not just independent syllables, is highly informative for performing scansion.