 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Judging with Large Language Models: Concepts, Methods, and Challenges
Jan 24, 2026Large language models (LLMs) are evolving fast and are now frequently used as evaluators, in a process typically referred to as LLM-as-a-Judge, which provides quality assessments of model outputs. However, recent research points out significant vulnerabilities in such evaluation, including sensitivity to prompts, systematic biases, verbosity effects, and unreliable or hallucinated rationales. These limitations motivated the development of a more robust paradigm, dubbed LLM-as-a-Meta-Judge. This survey reviews recent advances in meta-judging and organizes the literature, by introducing a framework along six key perspectives: (i) Conceptual Foundations, (ii) Mechanisms of Meta-Judging, (iii) Alignment Training Methods, (iv) Evaluation, (v) Limitations and Failure Modes, and (vi) Future Directions. By analyzing the limitations of LLM-as-a-Judge and summarizing recent advances in meta-judging by LLMs, we argue that LLM-as-a-Meta-Judge offers a promising direction for more stable and trustworthy automated evaluation, while highlighting remaining challenges related to cost, prompt sensitivity, and shared model biases, which must be addressed to advance the next generation of LLM evaluation methodologies.
Reasoning or Not? A Comprehensive Evaluation of Reasoning LLMs for Dialogue Summarization
Jul 02, 2025



Dialogue summarization is a challenging task with significant practical value in customer service, meeting analysis, and conversational AI. Although large language models (LLMs) have achieved substantial progress in summarization tasks, the performance of step-by-step reasoning architectures-specifically Long Chain-of-Thought (CoT) implementations such as OpenAI-o1 and DeepSeek-R1-remains unexplored for dialogue scenarios requiring concurrent abstraction and conciseness. In this work, we present the first comprehensive and systematic evaluation of state-of-the-art reasoning LLMs and non-reasoning LLMs across three major paradigms-generic, role-oriented, and query-oriented dialogue summarization. Our study spans diverse languages, domains, and summary lengths, leveraging strong benchmarks (SAMSum, DialogSum, CSDS, and QMSum) and advanced evaluation protocols that include both LLM-based automatic metrics and human-inspired criteria. Contrary to trends in other reasoning-intensive tasks, our findings show that explicit stepwise reasoning does not consistently improve dialogue summarization quality. Instead, reasoning LLMs are often prone to verbosity, factual inconsistencies, and less concise summaries compared to their non-reasoning counterparts. Through scenario-specific analyses and detailed case studies, we further identify when and why explicit reasoning may fail to benefit-or even hinder-summarization in complex dialogue contexts. Our work provides new insights into the limitations of current reasoning LLMs and highlights the need for targeted modeling and evaluation strategies for real-world dialogue summarization.
Unsupervised Flow Discovery from Task-oriented Dialogues
May 02, 2024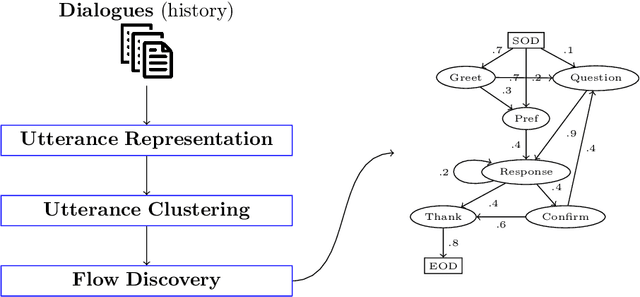



The design of dialogue flows is a critical but time-consuming task when developing task-oriented dialogue (TOD) systems. We propose an approach for the unsupervised discovery of flows from dialogue history, thus making the process applicable to any domain for which such an history is available. Briefly, utterances are represented in a vector space and clustered according to their semantic similarity. Clusters, which can be seen as dialogue states, are then used as the vertices of a transition graph for representing the flows visually. We present concrete examples of flows, discovered from MultiWOZ, a public TOD dataset. We further elaborate on their significance and relevance for the underlying conversations and introduce an automatic validation metric for their assessment. Experimental results demonstrate the potential of the proposed approach for extracting meaningful flows from task-oriented conversations.
Erato: Automatizing Poetry Evaluation
Oct 31, 2023We present Erato, a framework designed to facilitate the automated evaluation of poetry, including that generated by poetry generation systems. Our framework employs a diverse set of features, and we offer a brief overview of Erato's capabilities and its potential for expansion. Using Erato, we compare and contrast human-authored poetry with automatically-generated poetry, demonstrating its effectiveness in identifying key differences. Our implementation code and software are freely available under the GNU GPLv3 license.