 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Induction of Finite-State Transducers
Jan 16, 2026Finite-State Transducers (FSTs) are effective models for string-to-string rewriting tasks, often providing the efficiency necessary for high-performance applications, but constructing transducers by hand is difficult. In this work, we propose a novel method for automatically constructing unweighted FSTs following the hidden state geometry learned by a recurrent neural network. We evaluate our methods on real-world datasets for morphological inflection, grapheme-to-phoneme prediction, and historical normalization, showing that the constructed FSTs are highly accurate and robust for many datasets, substantially outperforming classical transducer learning algorithms by up to 87% accuracy on held-out test sets.
Can we teach language models to gloss endangered languages?
Jun 27, 2024
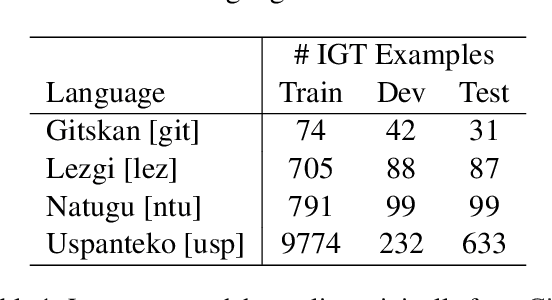

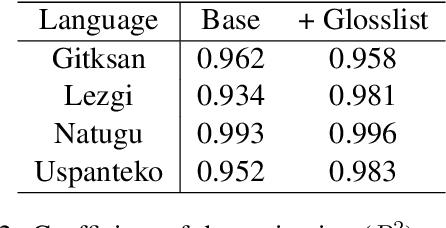
Interlinear glossed text (IGT) is a popular format in language documentation projects, where each morpheme is labeled with a descriptive annotation. Automating the creation of interlinear glossed text can be desirable to reduce annotator effort and maintain consistency across annotated corpora. Prior research has explored a number of statistical and neural methods for automatically producing IGT. As large language models (LLMs) have showed promising results across multilingual tasks, even for rare, endangered languages, it is natural to wonder whether they can be utilized for the task of generating IGT. We explore whether LLMs can be effective at the task of interlinear glossing with in-context learning, without any traditional training. We propose new approaches for selecting examples to provide in-context, observing that targeted selection can significantly improve performance. We find that LLM-based methods beat standard transformer baselines, despite requiring no training at all. These approaches still underperform state-of-the-art supervised systems for the task, but are highly practical for researchers outside of the NLP community, requiring minimal effort to use.
Historia Magistra Vitae: Dynamic Topic Modeling of Roman Literature using Neural Embeddings
Jun 27, 2024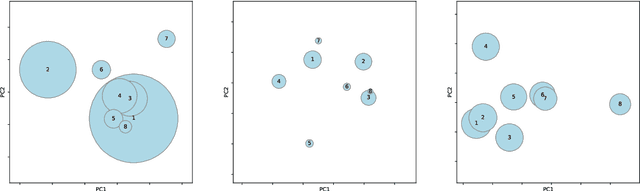
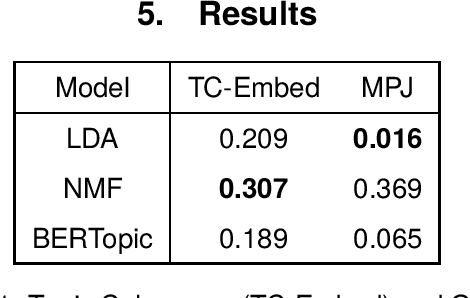
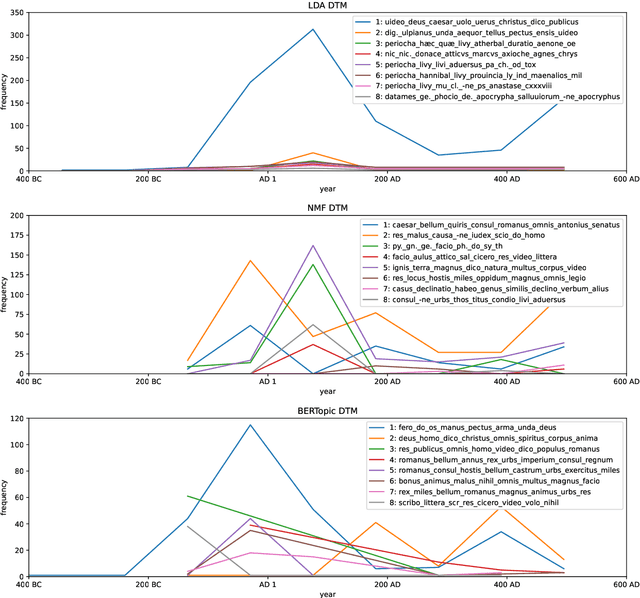
Dynamic topic models have been proposed as a tool for historical analysis, but traditional approaches have had limited usefulness, being difficult to configure, interpret, and evaluate. In this work, we experiment with a recent approach for dynamic topic modeling using BERT embeddings. We compare topic models built using traditional statistical models (LDA and NMF) and the BERT-based model, modeling topics over the entire surviving corpus of Roman literature. We find that while quantitative metrics prefer statistical models, qualitative evaluation finds better insights from the neural model. Furthermore, the neural topic model is less sensitive to hyperparameter configuration and thus may make dynamic topic modeling more viable for historical researchers.
Eeny, meeny, miny, moe. How to choose data for morphological inflection
Oct 26, 2022


Data scarcity is a widespread problem in numerous natural language processing (NLP) tasks for low-resource languages. Within morphology, the labour-intensive work of tagging/glossing data is a serious bottleneck for both NLP and language documentation. Active learning (AL) aims to reduce the cost of data annotation by selecting data that is most informative for improving the model. In this paper, we explore four sampling strategies for the task of morphological inflection using a Transformer model: a pair of oracle experiments where data is chosen based on whether the model already can or cannot inflect the test forms correctly, as well as strategies based on high/low model confidence, entropy, as well as random selection. We investigate the robustness of each strategy across 30 typologically diverse languages. We also perform a more in-depth case study of Nat\"ugu. Our results show a clear benefit to selecting data based on model confidence and entropy. Unsurprisingly, the oracle experiment, where only incorrectly handled forms are chosen for further training, which is presented as a proxy for linguist/language consultant feedback, shows the most improvement. This is followed closely by choosing low-confidence and high-entropy predictions. We also show that despite the conventional wisdom of larger data sets yielding better accuracy, introducing more instances of high-confidence or low-entropy forms, or forms that the model can already inflect correctly, can reduce model performance.
UniMorph 4.0: Universal Morphology
May 10, 2022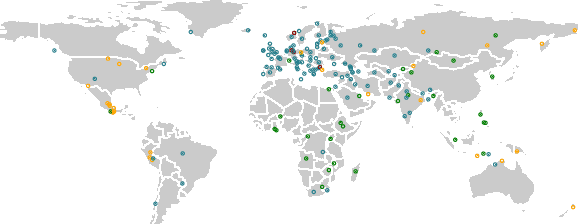

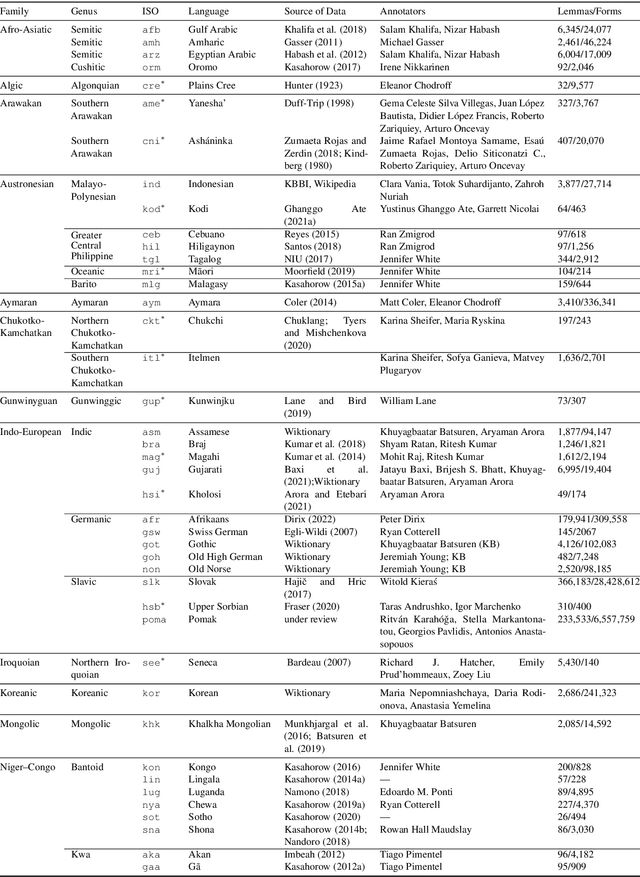
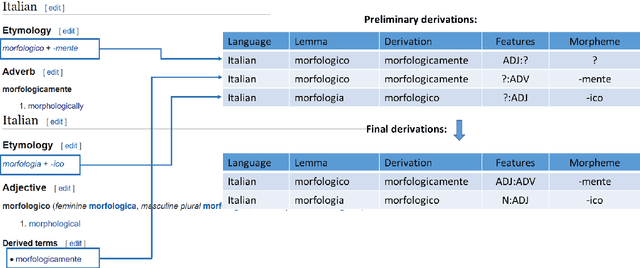
The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Can a Transformer Pass the Wug Test? Tuning Copying Bias in Neural Morphological Inflection Models
Apr 13, 2021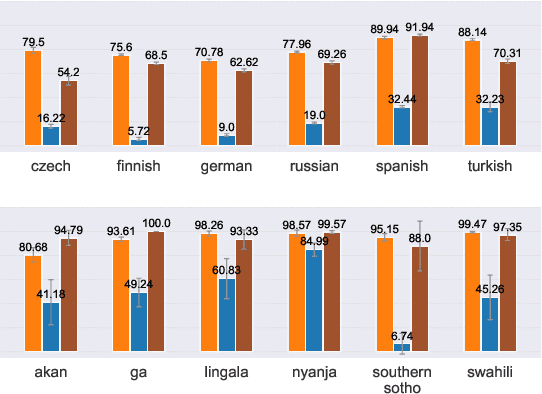
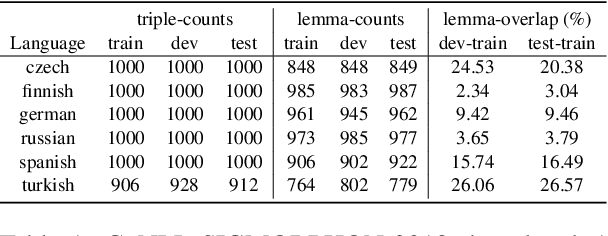
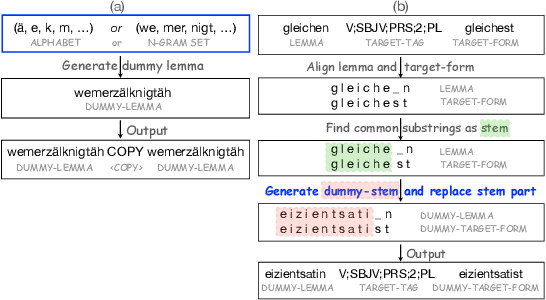
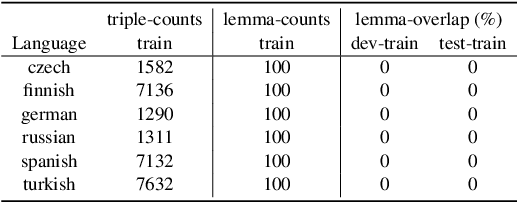
Deep learning sequence models have been successfully applied to the task of morphological inflection. The results of the SIGMORPHON shared tasks in the past several years indicate that such models can perform well, but only if the training data cover a good amount of different lemmata, or if the lemmata that are inflected at test time have also been seen in training, as has indeed been largely the case in these tasks. Surprisingly, standard models such as the Transformer almost completely fail at generalizing inflection patterns when asked to inflect previously unseen lemmata -- i.e. under "wug test"-like circumstances. While established data augmentation techniques can be employed to alleviate this shortcoming by introducing a copying bias through hallucinating synthetic new word forms using the alphabet in the language at hand, we show that, to be more effective, the hallucination process needs to pay attention to substrings of syllable-like length rather than individual characters or stems. We report a significant performance improvement with our substring-based hallucination model over previous data hallucination methods when training and test data do not overlap in their lemmata.
Do RNN States Encode Abstract Phonological Processes?
Apr 01, 2021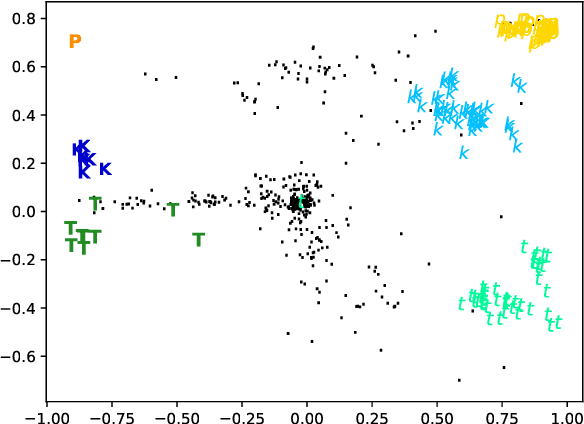
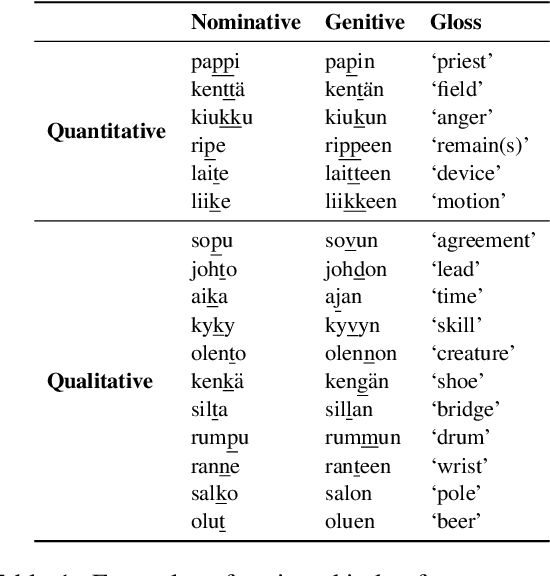

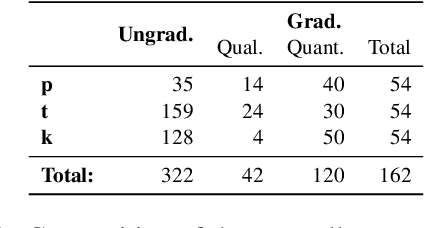
Sequence-to-sequence models have delivered impressive results in word formation tasks such as morphological inflection, often learning to model subtle morphophonological details with limited training data. Despite the performance, the opacity of neural models makes it difficult to determine whether complex generalizations are learned, or whether a kind of separate rote memorization of each morphophonological process takes place. To investigate whether complex alternations are simply memorized or whether there is some level of generalization across related sound changes in a sequence-to-sequence model, we perform several experiments on Finnish consonant gradation -- a complex set of sound changes triggered in some words by certain suffixes. We find that our models often -- though not always -- encode 17 different consonant gradation processes in a handful of dimensions in the RNN. We also show that by scaling the activations in these dimensions we can control whether consonant gradation occurs and the direction of the gradation.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020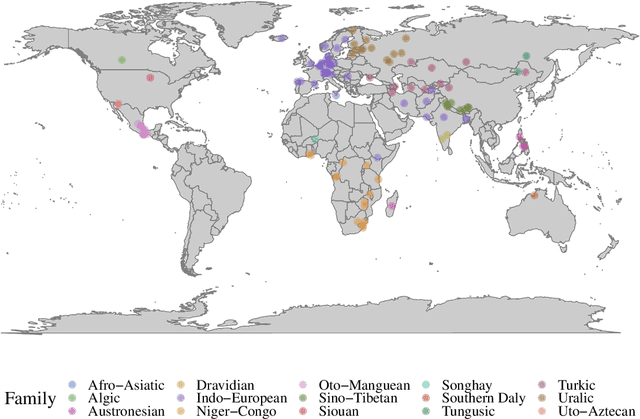
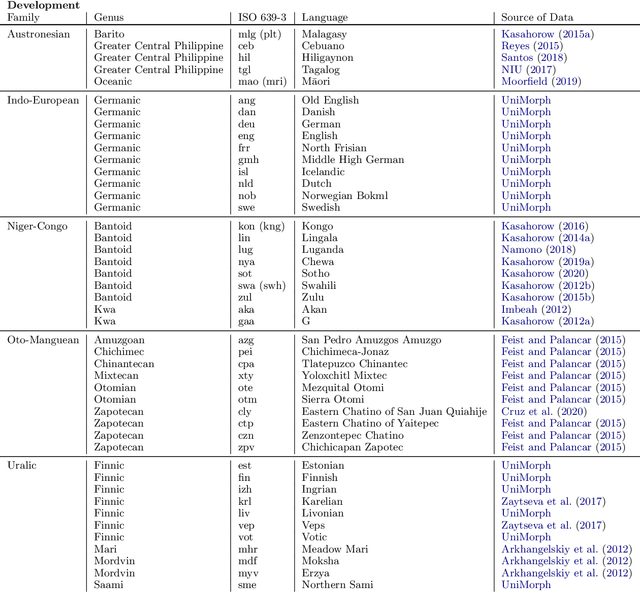
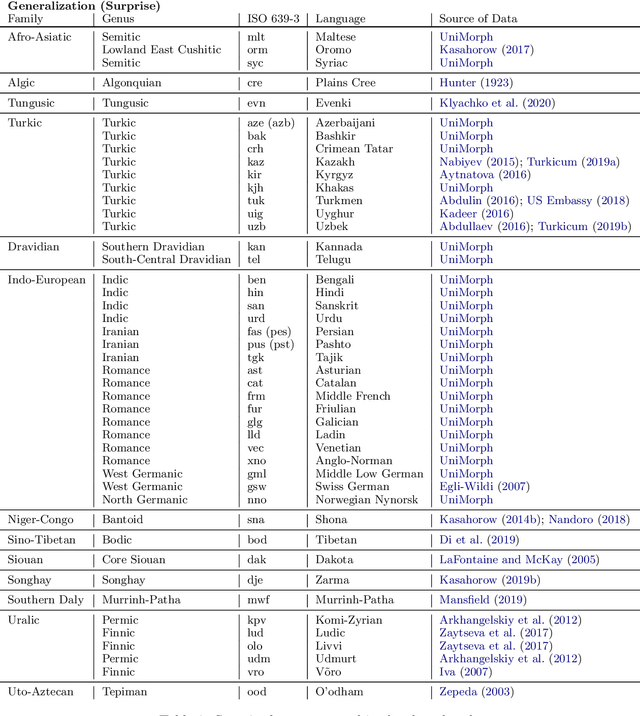
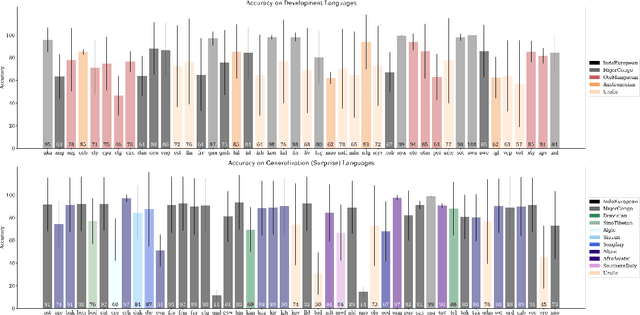
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.
The SIGMORPHON 2020 Shared Task on Unsupervised Morphological Paradigm Completion
May 28, 2020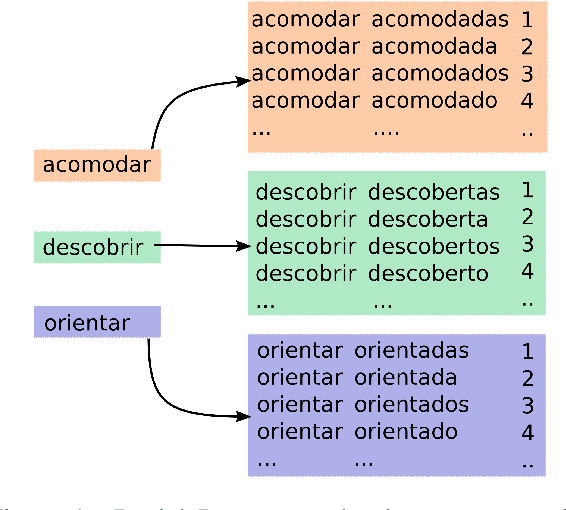

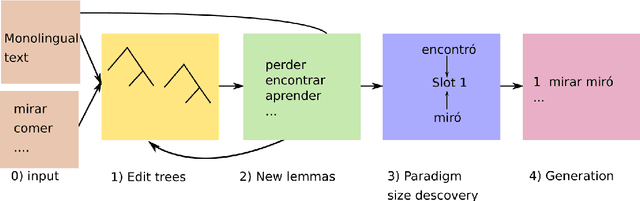
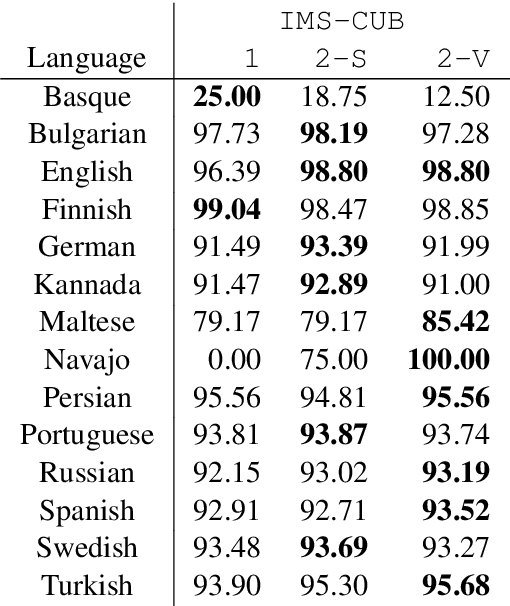
In this paper, we describe the findings of the SIGMORPHON 2020 shared task on unsupervised morphological paradigm completion (SIGMORPHON 2020 Task 2), a novel task in the field of inflectional morphology. Participants were asked to submit systems which take raw text and a list of lemmas as input, and output all inflected forms, i.e., the entire morphological paradigm, of each lemma. In order to simulate a realistic use case, we first released data for 5 development languages. However, systems were officially evaluated on 9 surprise languages, which were only revealed a few days before the submission deadline. We provided a modular baseline system, which is a pipeline of 4 components. 3 teams submitted a total of 7 systems, but, surprisingly, none of the submitted systems was able to improve over the baseline on average over all 9 test languages. Only on 3 languages did a submitted system obtain the best results. This shows that unsupervised morphological paradigm completion is still largely unsolved. We present an analysis here, so that this shared task will ground further research on the topic.
Applying the Transformer to Character-level Transduction
May 20, 2020



The transformer has been shown to outperform recurrent neural network-based sequence-to-sequence models in various word-level NLP tasks. The model offers other benefits as well: It trains faster and has fewer parameters. Yet for character-level transduction tasks, e.g. morphological inflection generation and historical text normalization, few shows success on outperforming recurrent models with the transformer. In an empirical study, we uncover that, in contrast to recurrent sequence-to-sequence models, the batch size plays a crucial role in the performance of the transformer on character-level tasks, and we show that with a large enough batch size, the transformer does indeed outperform recurrent models. We also introduce a simple technique to handle feature-guided character-level transduction that further improves performance. With these insights, we achieve state-of-the-art performance on morphological inflection and historical text normalization. We also show that the transformer outperforms a strong baseline on two other character-level transduction tasks: grapheme-to-phoneme conversion and transliteration. Code is available at https://github.com/shijie-wu/neural-transducer.