 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Transformer Pass the Wug Test? Tuning Copying Bias in Neural Morphological Inflection Models
Paper and Code
Apr 13, 2021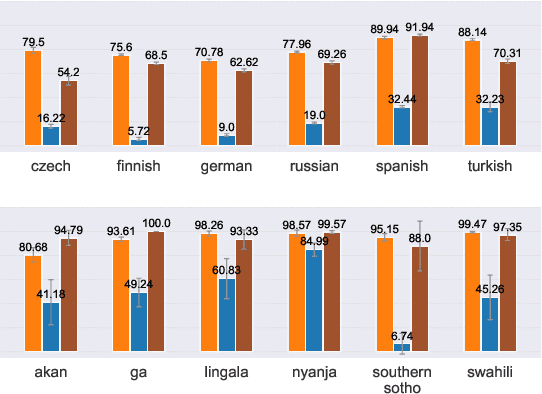
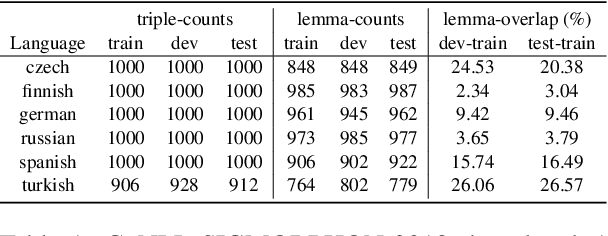
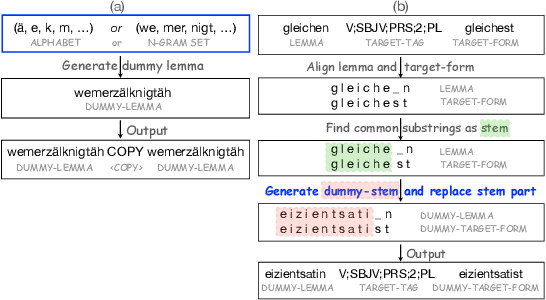
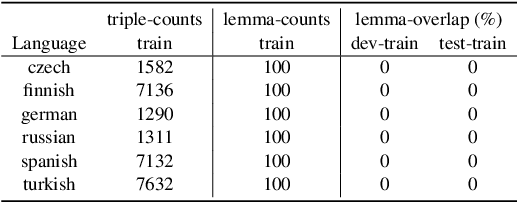
Deep learning sequence models have been successfully applied to the task of morphological inflection. The results of the SIGMORPHON shared tasks in the past several years indicate that such models can perform well, but only if the training data cover a good amount of different lemmata, or if the lemmata that are inflected at test time have also been seen in training, as has indeed been largely the case in these tasks. Surprisingly, standard models such as the Transformer almost completely fail at generalizing inflection patterns when asked to inflect previously unseen lemmata -- i.e. under "wug test"-like circumstances. While established data augmentation techniques can be employed to alleviate this shortcoming by introducing a copying bias through hallucinating synthetic new word forms using the alphabet in the language at hand, we show that, to be more effective, the hallucination process needs to pay attention to substrings of syllable-like length rather than individual characters or stems. We report a significant performance improvement with our substring-based hallucination model over previous data hallucination methods when training and test data do not overlap in their lemmata.