 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Induction of Finite-State Transducers
Jan 16, 2026Finite-State Transducers (FSTs) are effective models for string-to-string rewriting tasks, often providing the efficiency necessary for high-performance applications, but constructing transducers by hand is difficult. In this work, we propose a novel method for automatically constructing unweighted FSTs following the hidden state geometry learned by a recurrent neural network. We evaluate our methods on real-world datasets for morphological inflection, grapheme-to-phoneme prediction, and historical normalization, showing that the constructed FSTs are highly accurate and robust for many datasets, substantially outperforming classical transducer learning algorithms by up to 87% accuracy on held-out test sets.
Massively Multilingual Joint Segmentation and Glossing
Jan 16, 2026Automated interlinear gloss prediction with neural networks is a promising approach to accelerate language documentation efforts. However, while state-of-the-art models like GlossLM achieve high scores on glossing benchmarks, user studies with linguists have found critical barriers to the usefulness of such models in real-world scenarios. In particular, existing models typically generate morpheme-level glosses but assign them to whole words without predicting the actual morpheme boundaries, making the predictions less interpretable and thus untrustworthy to human annotators. We conduct the first study on neural models that jointly predict interlinear glosses and the corresponding morphological segmentation from raw text. We run experiments to determine the optimal way to train models that balance segmentation and glossing accuracy, as well as the alignment between the two tasks. We extend the training corpus of GlossLM and pretrain PolyGloss, a family of seq2seq multilingual models for joint segmentation and glossing that outperforms GlossLM on glossing and beats various open-source LLMs on segmentation, glossing, and alignment. In addition, we demonstrate that PolyGloss can be quickly adapted to a new dataset via low-rank adaptation.
Tree Transformers are an Ineffective Model of Syntactic Constituency
Nov 25, 2024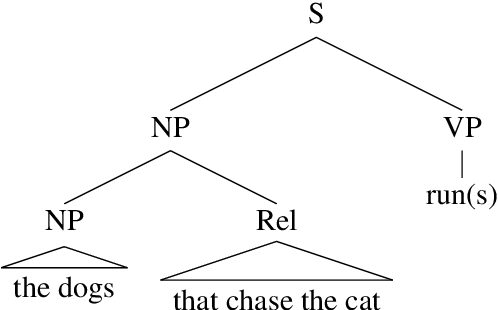

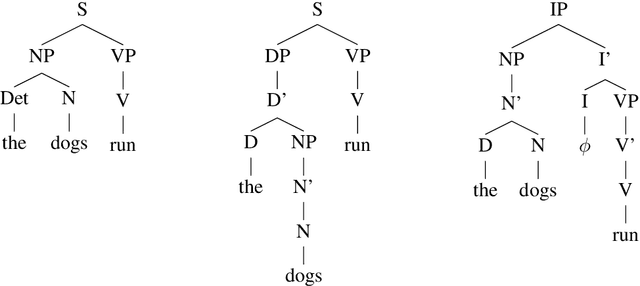

Linguists have long held that a key aspect of natural language syntax is the recursive organization of language units into constituent structures, and research has suggested that current state-of-the-art language models lack an inherent bias towards this feature. A number of alternative models have been proposed to provide inductive biases towards constituency, including the Tree Transformer, which utilizes a modified attention mechanism to organize tokens into constituents. We investigate Tree Transformers to study whether they utilize meaningful and/or useful constituent structures. We pretrain a large Tree Transformer on language modeling in order to investigate the learned constituent tree representations of sentences, finding little evidence for meaningful structures. Next, we evaluate Tree Transformers with similar transformer models on error detection tasks requiring constituent structure. We find that while the Tree Transformer models may slightly outperform at these tasks, there is little evidence to suggest a meaningful improvement. In general, we conclude that there is little evidence to support Tree Transformer as an effective model of syntactic constituency.
Historia Magistra Vitae: Dynamic Topic Modeling of Roman Literature using Neural Embeddings
Jun 27, 2024
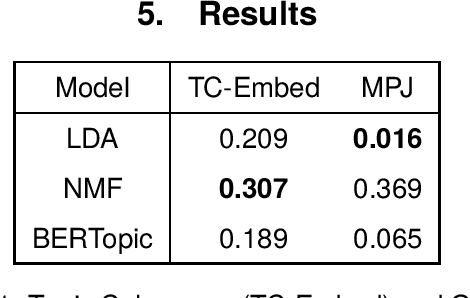
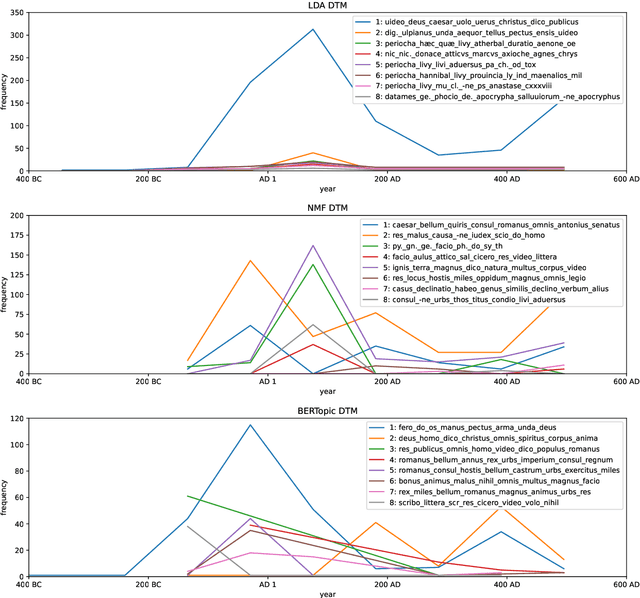
Dynamic topic models have been proposed as a tool for historical analysis, but traditional approaches have had limited usefulness, being difficult to configure, interpret, and evaluate. In this work, we experiment with a recent approach for dynamic topic modeling using BERT embeddings. We compare topic models built using traditional statistical models (LDA and NMF) and the BERT-based model, modeling topics over the entire surviving corpus of Roman literature. We find that while quantitative metrics prefer statistical models, qualitative evaluation finds better insights from the neural model. Furthermore, the neural topic model is less sensitive to hyperparameter configuration and thus may make dynamic topic modeling more viable for historical researchers.
Can we teach language models to gloss endangered languages?
Jun 27, 2024
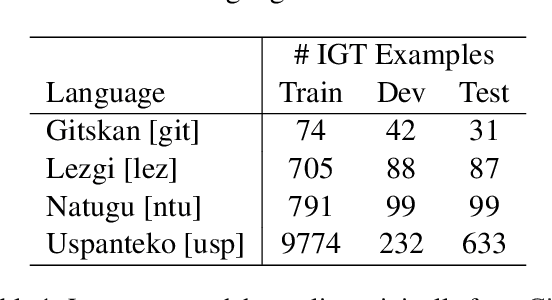

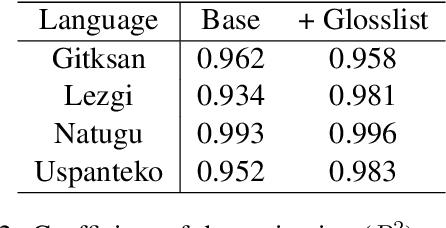
Interlinear glossed text (IGT) is a popular format in language documentation projects, where each morpheme is labeled with a descriptive annotation. Automating the creation of interlinear glossed text can be desirable to reduce annotator effort and maintain consistency across annotated corpora. Prior research has explored a number of statistical and neural methods for automatically producing IGT. As large language models (LLMs) have showed promising results across multilingual tasks, even for rare, endangered languages, it is natural to wonder whether they can be utilized for the task of generating IGT. We explore whether LLMs can be effective at the task of interlinear glossing with in-context learning, without any traditional training. We propose new approaches for selecting examples to provide in-context, observing that targeted selection can significantly improve performance. We find that LLM-based methods beat standard transformer baselines, despite requiring no training at all. These approaches still underperform state-of-the-art supervised systems for the task, but are highly practical for researchers outside of the NLP community, requiring minimal effort to use.
GlossLM: Multilingual Pretraining for Low-Resource Interlinear Glossing
Mar 11, 2024



A key aspect of language documentation is the creation of annotated text in a format such as interlinear glossed text (IGT), which captures fine-grained morphosyntactic analyses in a morpheme-by-morpheme format. Prior work has explored methods to automatically generate IGT in order to reduce the time cost of language analysis. However, many languages (particularly those requiring preservation) lack sufficient IGT data to train effective models, and crosslingual transfer has been proposed as a method to overcome this limitation. We compile the largest existing corpus of IGT data from a variety of sources, covering over 450k examples across 1.8k languages, to enable research on crosslingual transfer and IGT generation. Then, we pretrain a large multilingual model on a portion of this corpus, and further finetune it to specific languages. Our model is competitive with state-of-the-art methods for segmented data and large monolingual datasets. Meanwhile, our model outperforms SOTA models on unsegmented text and small corpora by up to 6.6% morpheme accuracy, demonstrating the effectiveness of crosslingual transfer for low-resource languages.
Robust Generalization Strategies for Morpheme Glossing in an Endangered Language Documentation Context
Nov 05, 2023Generalization is of particular importance in resource-constrained settings, where the available training data may represent only a small fraction of the distribution of possible texts. We investigate the ability of morpheme labeling models to generalize by evaluating their performance on unseen genres of text, and we experiment with strategies for closing the gap between performance on in-distribution and out-of-distribution data. Specifically, we use weight decay optimization, output denoising, and iterative pseudo-labeling, and achieve a 2% improvement on a test set containing texts from unseen genres. All experiments are performed using texts written in the Mayan language Uspanteko.
Taxonomic Loss for Morphological Glossing of Low-Resource Languages
Aug 29, 2023Morpheme glossing is a critical task in automated language documentation and can benefit other downstream applications greatly. While state-of-the-art glossing systems perform very well for languages with large amounts of existing data, it is more difficult to create useful models for low-resource languages. In this paper, we propose the use of a taxonomic loss function that exploits morphological information to make morphological glossing more performant when data is scarce. We find that while the use of this loss function does not outperform a standard loss function with regards to single-label prediction accuracy, it produces better predictions when considering the top-n predicted labels. We suggest this property makes the taxonomic loss function useful in a human-in-the-loop annotation setting.
SIGMORPHON 2023 Shared Task of Interlinear Glossing: Baseline Model
Mar 24, 2023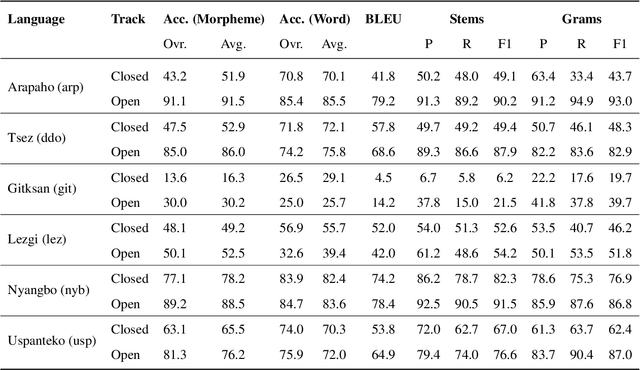
Language documentation is a critical aspect of language preservation, often including the creation of Interlinear Glossed Text (IGT). Creating IGT is time-consuming and tedious, and automating the process can save valuable annotator effort. This paper describes the baseline system for the SIGMORPHON 2023 Shared Task of Interlinear Glossing. In our system, we utilize a transformer architecture and treat gloss generation as a sequence labelling task.