 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Transformers are an Ineffective Model of Syntactic Constituency
Paper and Code
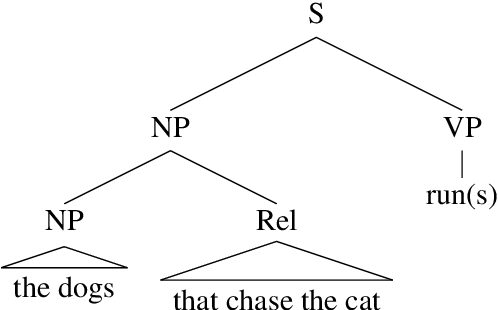


Linguists have long held that a key aspect of natural language syntax is the recursive organization of language units into constituent structures, and research has suggested that current state-of-the-art language models lack an inherent bias towards this feature. A number of alternative models have been proposed to provide inductive biases towards constituency, including the Tree Transformer, which utilizes a modified attention mechanism to organize tokens into constituents. We investigate Tree Transformers to study whether they utilize meaningful and/or useful constituent structures. We pretrain a large Tree Transformer on language modeling in order to investigate the learned constituent tree representations of sentences, finding little evidence for meaningful structures. Next, we evaluate Tree Transformers with similar transformer models on error detection tasks requiring constituent structure. We find that while the Tree Transformer models may slightly outperform at these tasks, there is little evidence to suggest a meaningful improvement. In general, we conclude that there is little evidence to support Tree Transformer as an effective model of syntactic constituency.