 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKUCST@LT-EDI-ACL2022: Detecting Signs of Depression from Social Media Text
Apr 09, 2022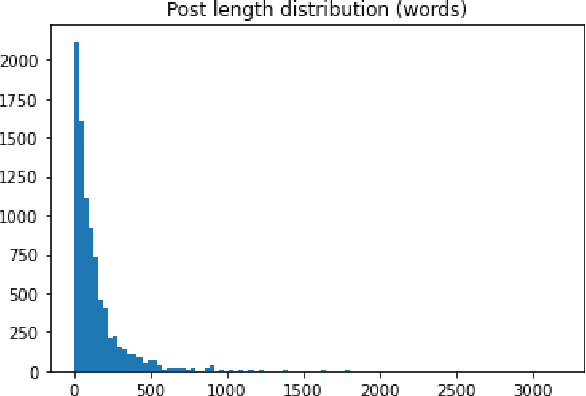
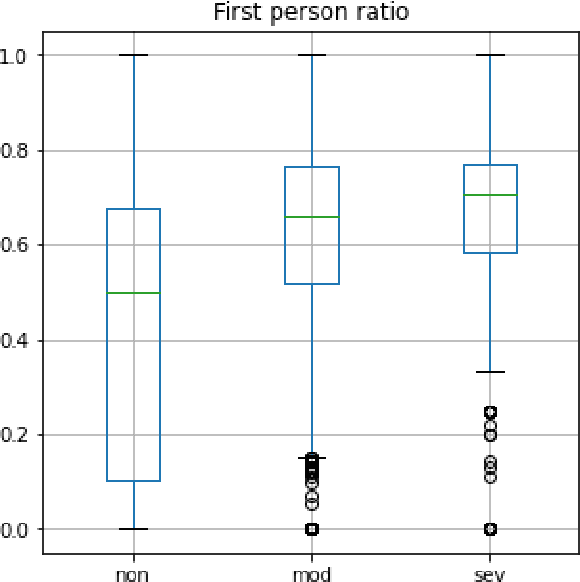
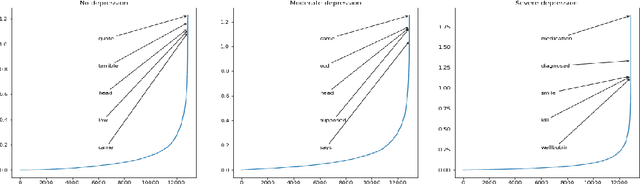
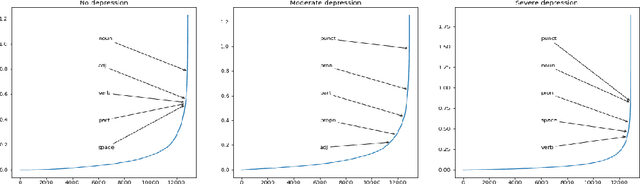
In this paper we present our approach for detecting signs of depression from social media text. Our model relies on word unigrams, part-of-speech tags, readabilitiy measures and the use of first, second or third person and the number of words. Our best model obtained a macro F1-score of 0.439 and ranked 25th, out of 31 teams. We further take advantage of the interpretability of the Logistic Regression model and we make an attempt to interpret the model coefficients with the hope that these will be useful for further research on the topic.
From meaning to perception -- exploring the space between word and odor perception embeddings
Mar 19, 2022
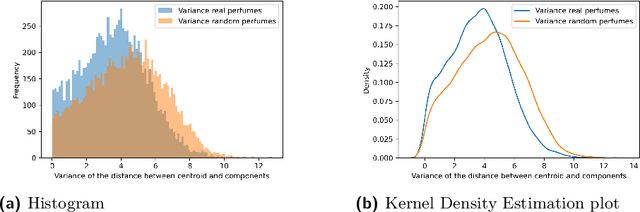


In this paper we propose the use of the Word2vec algorithm in order to obtain odor perception embeddings (or smell embeddings), only using publicly available perfume descriptions. Besides showing meaningful similarity relationships among each other, these embeddings also demonstrate to possess some shared information with their respective word embeddings. The meaningfulness of these embeddings suggests that aesthetics might provide enough constraints for using algorithms motivated by distributional semantics on non-randomly combined data. Furthermore, they provide possibilities for new ways of classifying odors and analyzing perfumes. We have also employed the embeddings in an attempt to understand the aesthetic nature of perfumes, based on the difference between real and randomly generated perfumes. In an additional tentative experiment we explore the possibility of a mapping between the word embedding space and the odor perception embedding space by fitting a regressor on the shared vocabulary and then predict the odor perception embeddings of words without an a priori associated smell, such as night or sky.