 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized 3D Gaussian Splatting using Coarse-to-Fine Image Frequency Modulation
Mar 18, 2025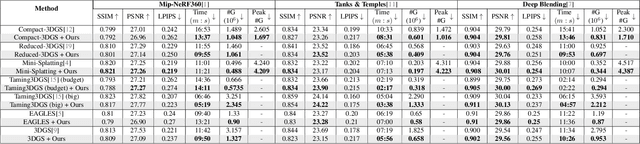
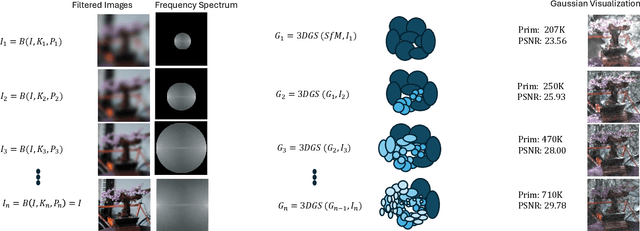
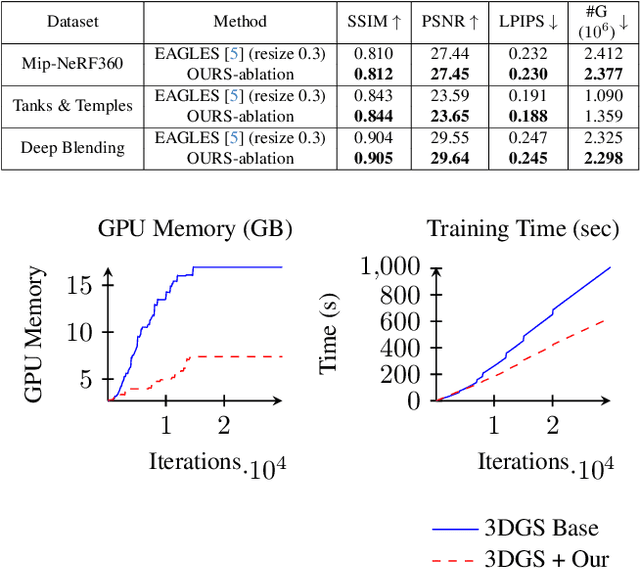

The field of Novel View Synthesis has been revolutionized by 3D Gaussian Splatting (3DGS), which enables high-quality scene reconstruction that can be rendered in real-time. 3DGS-based techniques typically suffer from high GPU memory and disk storage requirements which limits their practical application on consumer-grade devices. We propose Opti3DGS, a novel frequency-modulated coarse-to-fine optimization framework that aims to minimize the number of Gaussian primitives used to represent a scene, thus reducing memory and storage demands. Opti3DGS leverages image frequency modulation, initially enforcing a coarse scene representation and progressively refining it by modulating frequency details in the training images. On the baseline 3DGS, we demonstrate an average reduction of 62% in Gaussians, a 40% reduction in the training GPU memory requirements and a 20% reduction in optimization time without sacrificing the visual quality. Furthermore, we show that our method integrates seamlessly with many 3DGS-based techniques, consistently reducing the number of Gaussian primitives while maintaining, and often improving, visual quality. Additionally, Opti3DGS inherently produces a level-of-detail scene representation at no extra cost, a natural byproduct of the optimization pipeline. Results and code will be made publicly available.
Enhanced Multi-View Pedestrian Detection Using Probabilistic Occupancy Volume
Mar 14, 2025Occlusion poses a significant challenge in pedestrian detection from a single view. To address this, multi-view detection systems have been utilized to aggregate information from multiple perspectives. Recent advances in multi-view detection utilized an early-fusion strategy that strategically projects the features onto the ground plane, where detection analysis is performed. A promising approach in this context is the use of 3D feature-pulling technique, which constructs a 3D feature volume of the scene by sampling the corresponding 2D features for each voxel. However, it creates a 3D feature volume of the whole scene without considering the potential locations of pedestrians. In this paper, we introduce a novel model that efficiently leverages traditional 3D reconstruction techniques to enhance deep multi-view pedestrian detection. This is accomplished by complementing the 3D feature volume with probabilistic occupancy volume, which is constructed using the visual hull technique. The probabilistic occupancy volume focuses the model's attention on regions occupied by pedestrians and improves detection accuracy. Our model outperforms state-of-the-art models on the MultiviewX dataset, with an MODA of 97.3%, while achieving competitive performance on the Wildtrack dataset.
360U-Former: HDR Illumination Estimation with Panoramic Adapted Vision Transformers
Oct 17, 2024
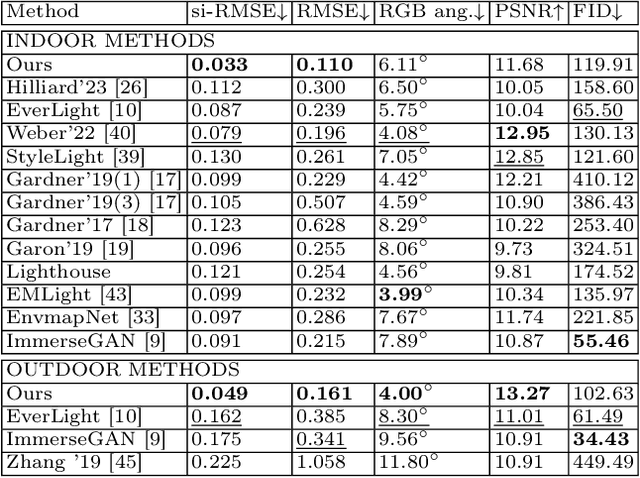
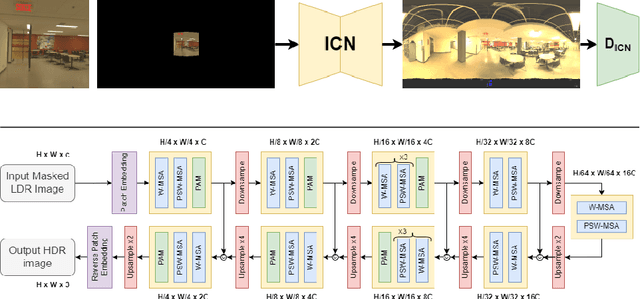
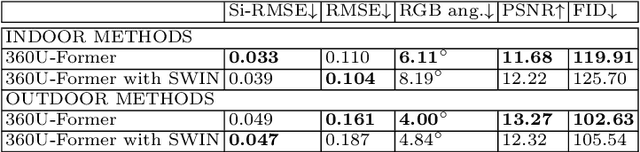
Recent illumination estimation methods have focused on enhancing the resolution and improving the quality and diversity of the generated textures. However, few have explored tailoring the neural network architecture to the Equirectangular Panorama (ERP) format utilised in image-based lighting. Consequently, high dynamic range images (HDRI) results usually exhibit a seam at the side borders and textures or objects that are warped at the poles. To address this shortcoming we propose a novel architecture, 360U-Former, based on a U-Net style Vision-Transformer which leverages the work of PanoSWIN, an adapted shifted window attention tailored to the ERP format. To the best of our knowledge, this is the first purely Vision-Transformer model used in the field of illumination estimation. We train 360U-Former as a GAN to generate HDRI from a limited field of view low dynamic range image (LDRI). We evaluate our method using current illumination estimation evaluation protocols and datasets, demonstrating that our approach outperforms existing and state-of-the-art methods without the artefacts typically associated with the use of the ERP format.
HyperKon: A Self-Supervised Contrastive Network for Hyperspectral Image Analysis
Nov 26, 2023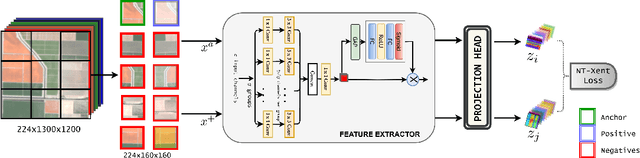

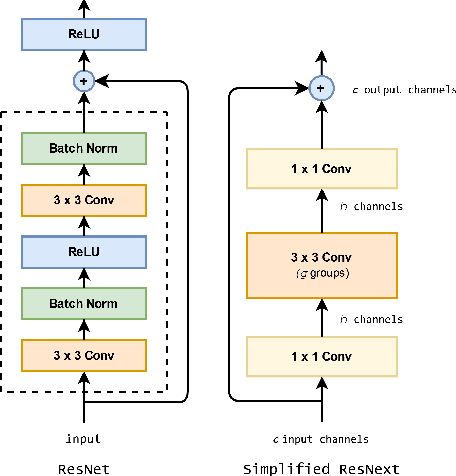
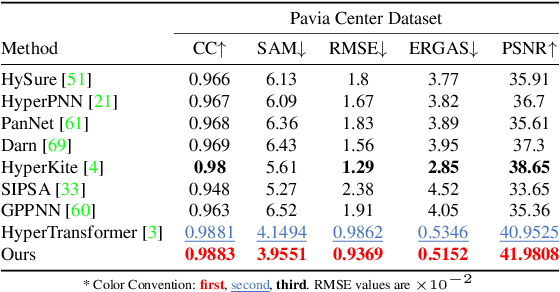
The exceptional spectral resolution of hyperspectral imagery enables material insights that are not possible with RGB or multispectral images. Yet, the full potential of this data is often underutilized by deep learning techniques due to the scarcity of hyperspectral-native CNN backbones. To bridge this gap, we introduce HyperKon, a self-supervised contrastive learning network designed and trained on hyperspectral data from the EnMAP Hyperspectral Satellite\cite{kaufmann2012environmental}. HyperKon uniquely leverages the high spectral continuity, range, and resolution of hyperspectral data through a spectral attention mechanism and specialized convolutional layers. We also perform a thorough ablation study on different kinds of layers, showing their performance in understanding hyperspectral layers. It achieves an outstanding 98% Top-1 retrieval accuracy and outperforms traditional RGB-trained backbones in hyperspectral pan-sharpening tasks. Additionally, in hyperspectral image classification, HyperKon surpasses state-of-the-art methods, indicating a paradigm shift in hyperspectral image analysis and underscoring the importance of hyperspectral-native backbones.
Adaptive sampling for scanning pixel cameras
Aug 01, 2022

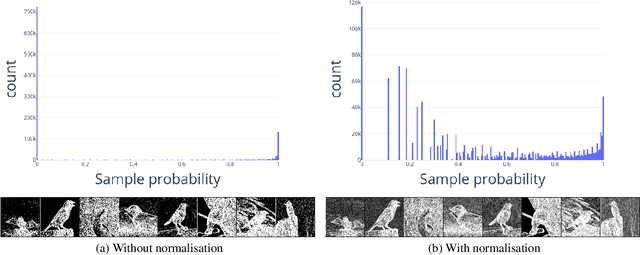
A scanning pixel camera is a novel low-cost, low-power sensor that is not diffraction limited. It produces data as a sequence of samples extracted from various parts of the scene during the course of a scan. It can provide very detailed images at the expense of samplerates and slow image acquisition time. This paper proposes a new algorithm which allows the sensor to adapt the samplerate over the course of this sequence. This makes it possible to overcome some of these limitations by minimising the bandwidth and time required to image and transmit a scene, while maintaining image quality. We examine applications to image classification and semantic segmentation and are able to achieve similar results compared to a fully sampled input, while using 80% fewer samples
Temporally Coherent General Dynamic Scene Reconstruction
Jul 18, 2019
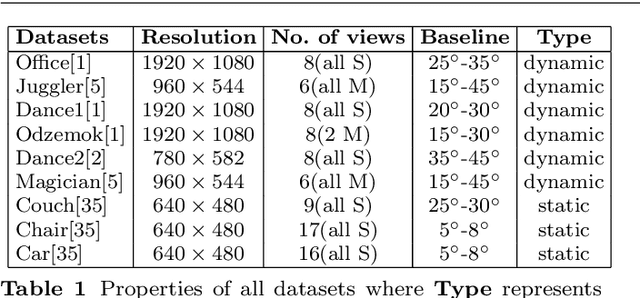

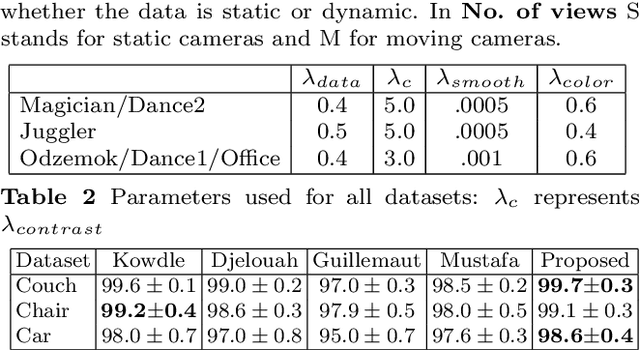
Existing techniques for dynamic scene reconstruction from multiple wide-baseline cameras primarily focus on reconstruction in controlled environments, with fixed calibrated cameras and strong prior constraints. This paper introduces a general approach to obtain a 4D representation of complex dynamic scenes from multi-view wide-baseline static or moving cameras without prior knowledge of the scene structure, appearance, or illumination. Contributions of the work are: An automatic method for initial coarse reconstruction to initialize joint estimation; Sparse-to-dense temporal correspondence integrated with joint multi-view segmentation and reconstruction to introduce temporal coherence; and a general robust approach for joint segmentation refinement and dense reconstruction of dynamic scenes by introducing shape constraint. Comparison with state-of-the-art approaches on a variety of complex indoor and outdoor scenes, demonstrates improved accuracy in both multi-view segmentation and dense reconstruction. This paper demonstrates unsupervised reconstruction of complete temporally coherent 4D scene models with improved non-rigid object segmentation and shape reconstruction and its application to free-viewpoint rendering and virtual reality.
Temporally coherent 4D reconstruction of complex dynamic scenes
Mar 28, 2016
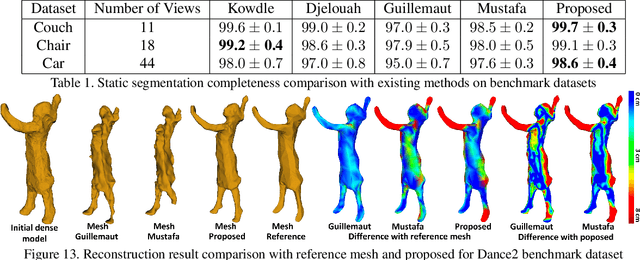

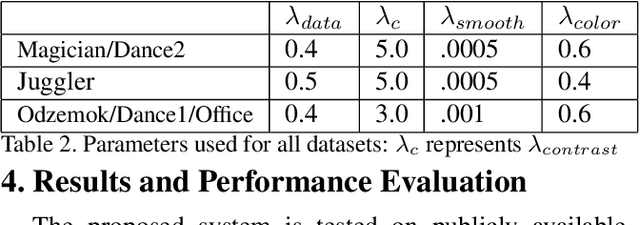
This paper presents an approach for reconstruction of 4D temporally coherent models of complex dynamic scenes. No prior knowledge is required of scene structure or camera calibration allowing reconstruction from multiple moving cameras. Sparse-to-dense temporal correspondence is integrated with joint multi-view segmentation and reconstruction to obtain a complete 4D representation of static and dynamic objects. Temporal coherence is exploited to overcome visual ambiguities resulting in improved reconstruction of complex scenes. Robust joint segmentation and reconstruction of dynamic objects is achieved by introducing a geodesic star convexity constraint. Comparative evaluation is performed on a variety of unstructured indoor and outdoor dynamic scenes with hand-held cameras and multiple people. This demonstrates reconstruction of complete temporally coherent 4D scene models with improved nonrigid object segmentation and shape reconstruction.
General Dynamic Scene Reconstruction from Multiple View Video
Sep 30, 2015
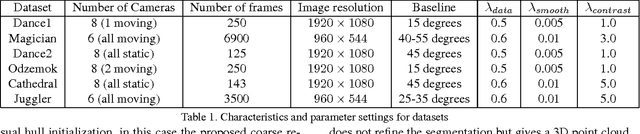
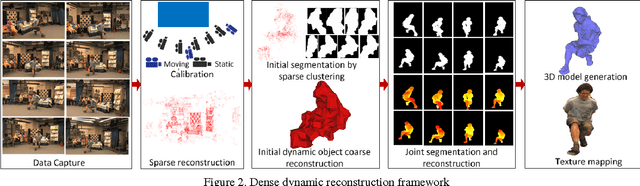

This paper introduces a general approach to dynamic scene reconstruction from multiple moving cameras without prior knowledge or limiting constraints on the scene structure, appearance, or illumination. Existing techniques for dynamic scene reconstruction from multiple wide-baseline camera views primarily focus on accurate reconstruction in controlled environments, where the cameras are fixed and calibrated and background is known. These approaches are not robust for general dynamic scenes captured with sparse moving cameras. Previous approaches for outdoor dynamic scene reconstruction assume prior knowledge of the static background appearance and structure. The primary contributions of this paper are twofold: an automatic method for initial coarse dynamic scene segmentation and reconstruction without prior knowledge of background appearance or structure; and a general robust approach for joint segmentation refinement and dense reconstruction of dynamic scenes from multiple wide-baseline static or moving cameras. Evaluation is performed on a variety of indoor and outdoor scenes with cluttered backgrounds and multiple dynamic non-rigid objects such as people. Comparison with state-of-the-art approaches demonstrates improved accuracy in both multiple view segmentation and dense reconstruction. The proposed approach also eliminates the requirement for prior knowledge of scene structure and appearance.