 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Study on the Development and Issues of Multi-Agent AI Systems
Jan 12, 2026The rapid emergence of multi-agent AI systems (MAS), including LangChain, CrewAI, and AutoGen, has shaped how large language model (LLM) applications are developed and orchestrated. However, little is known about how these systems evolve and are maintained in practice. This paper presents the first large-scale empirical study of open-source MAS, analyzing over 42K unique commits and over 4.7K resolved issues across eight leading systems. Our analysis identifies three distinct development profiles: sustained, steady, and burst-driven. These profiles reflect substantial variation in ecosystem maturity. Perfective commits constitute 40.8% of all changes, suggesting that feature enhancement is prioritized over corrective maintenance (27.4%) and adaptive updates (24.3%). Data about issues shows that the most frequent concerns involve bugs (22%), infrastructure (14%), and agent coordination challenges (10%). Issue reporting also increased sharply across all frameworks starting in 2023. Median resolution times range from under one day to about two weeks, with distributions skewed toward fast responses but a minority of issues requiring extended attention. These results highlight both the momentum and the fragility of the current ecosystem, emphasizing the need for improved testing infrastructure, documentation quality, and maintenance practices to ensure long-term reliability and sustainability.
What Users Value and Critique: Large-Scale Analysis of User Feedback on AI-Powered Mobile Apps
Jun 12, 2025
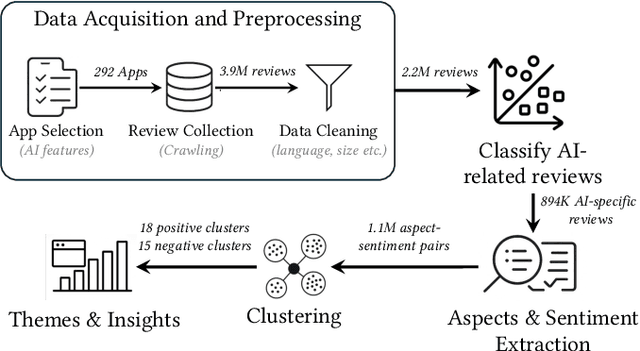
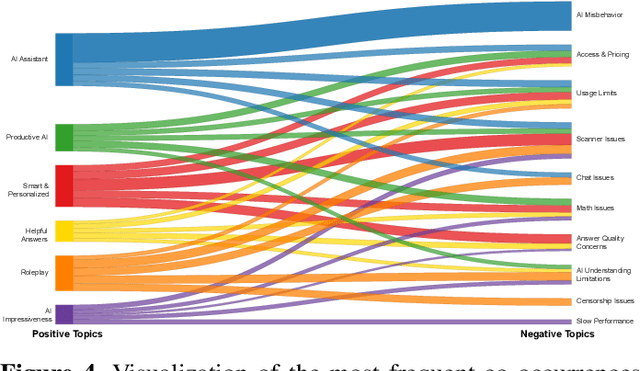
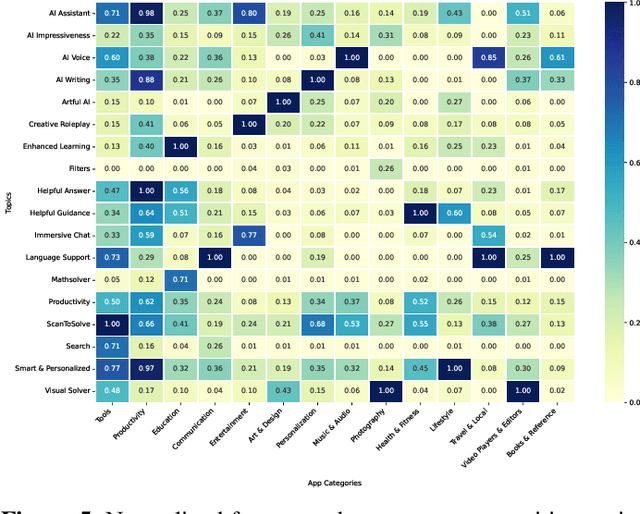
Artificial Intelligence (AI)-powered features have rapidly proliferated across mobile apps in various domains, including productivity, education, entertainment, and creativity. However, how users perceive, evaluate, and critique these AI features remains largely unexplored, primarily due to the overwhelming volume of user feedback. In this work, we present the first comprehensive, large-scale study of user feedback on AI-powered mobile apps, leveraging a curated dataset of 292 AI-driven apps across 14 categories with 894K AI-specific reviews from Google Play. We develop and validate a multi-stage analysis pipeline that begins with a human-labeled benchmark and systematically evaluates large language models (LLMs) and prompting strategies. Each stage, including review classification, aspect-sentiment extraction, and clustering, is validated for accuracy and consistency. Our pipeline enables scalable, high-precision analysis of user feedback, extracting over one million aspect-sentiment pairs clustered into 18 positive and 15 negative user topics. Our analysis reveals that users consistently focus on a narrow set of themes: positive comments emphasize productivity, reliability, and personalized assistance, while negative feedback highlights technical failures (e.g., scanning and recognition), pricing concerns, and limitations in language support. Our pipeline surfaces both satisfaction with one feature and frustration with another within the same review. These fine-grained, co-occurring sentiments are often missed by traditional approaches that treat positive and negative feedback in isolation or rely on coarse-grained analysis. To this end, our approach provides a more faithful reflection of the real-world user experiences with AI-powered apps. Category-aware analysis further uncovers both universal drivers of satisfaction and domain-specific frustrations.
MobileConvRec: A Conversational Dataset for Mobile Apps Recommendations
May 28, 2024Existing recommendation systems have focused on two paradigms: 1- historical user-item interaction-based recommendations and 2- conversational recommendations. Conversational recommendation systems facilitate natural language dialogues between users and the system, allowing the system to solicit users' explicit needs while enabling users to inquire about recommendations and provide feedback. Due to substantial advancements in natural language processing, conversational recommendation systems have gained prominence. Existing conversational recommendation datasets have greatly facilitated research in their respective domains. Despite the exponential growth in mobile users and apps in recent years, research in conversational mobile app recommender systems has faced substantial constraints. This limitation can primarily be attributed to the lack of high-quality benchmark datasets specifically tailored for mobile apps. To facilitate research for conversational mobile app recommendations, we introduce MobileConvRec. MobileConvRec simulates conversations by leveraging real user interactions with mobile apps on the Google Play store, originally captured in large-scale mobile app recommendation dataset MobileRec. The proposed conversational recommendation dataset synergizes sequential user-item interactions, which reflect implicit user preferences, with comprehensive multi-turn conversations to effectively grasp explicit user needs. MobileConvRec consists of over 12K multi-turn recommendation-related conversations spanning 45 app categories. Moreover, MobileConvRec presents rich metadata for each app such as permissions data, security and privacy-related information, and binary executables of apps, among others. We demonstrate that MobileConvRec can serve as an excellent testbed for conversational mobile app recommendation through a comparative study of several pre-trained large language models.