 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Persistent Effects of Lexicality in Large Language Models
Jun 03, 2026Representations extracted from large language models (LLMs) play an important role in many downstream applications. However, the structure of these representations is often influenced by lexical overlap rather than semantic content. Our understanding of the relationship between this lexical influence and semantic content, and its implications for downstream tasks, remains limited. In this work, we investigate representations to quantify the effect of lexical overlap relative to semantic content. We consider several adversarial semantic stress tests and further connect our findings to the information theory perspective. We find that lexical influence extends across the depth of models, consistently across architectures, training regimes, and objective functions, including the models trained for semantic similarity. Moreover, we observe a mid-depth region in which both lexical and semantic signals degrade simultaneously, indicating a transitional regime where representations are poor for both surface form and meaning. We further demonstrate the effect of lexical influence on downstream uses of LLMs using summarization and model editing as a case study.
Multi-Granular Node Pruning for Circuit Discovery
Dec 11, 2025Circuit discovery aims to identify minimal subnetworks that are responsible for specific behaviors in large language models (LLMs). Existing approaches primarily rely on iterative edge pruning, which is computationally expensive and limited to coarse-grained units such as attention heads or MLP blocks, overlooking finer structures like individual neurons. We propose a node-level pruning framework for circuit discovery that addresses both scalability and granularity limitations. Our method introduces learnable masks across multiple levels of granularity, from entire blocks to individual neurons, within a unified optimization objective. Granularity-specific sparsity penalties guide the pruning process, allowing a comprehensive compression in a single fine-tuning run. Empirically, our approach identifies circuits that are smaller in nodes than those discovered by prior methods; moreover, we demonstrate that many neurons deemed important by coarse methods are actually irrelevant, while still maintaining task performance. Furthermore, our method has a significantly lower memory footprint, 5-10x, as it does not require keeping intermediate activations in the memory to work.
Evaluating Sparse Autoencoders for Monosemantic Representation
Aug 20, 2025A key barrier to interpreting large language models is polysemanticity, where neurons activate for multiple unrelated concepts. Sparse autoencoders (SAEs) have been proposed to mitigate this issue by transforming dense activations into sparse, more interpretable features. While prior work suggests that SAEs promote monosemanticity, there has been no quantitative comparison with their base models. This paper provides the first systematic evaluation of SAEs against base models concerning monosemanticity. We introduce a fine-grained concept separability score based on the Jensen-Shannon distance, which captures how distinctly a neuron's activation distributions vary across concepts. Using Gemma-2-2B and multiple SAE variants across five benchmarks, we show that SAEs reduce polysemanticity and achieve higher concept separability. However, greater sparsity of SAEs does not always yield better separability and often impairs downstream performance. To assess practical utility, we evaluate concept-level interventions using two strategies: full neuron masking and partial suppression. We find that, compared to base models, SAEs enable more precise concept-level control when using partial suppression. Building on this, we propose Attenuation via Posterior Probabilities (APP), a new intervention method that uses concept-conditioned activation distributions for targeted suppression. APP outperforms existing approaches in targeted concept removal.
Looking into Black Box Code Language Models
Jul 05, 2024



Language Models (LMs) have shown their application for tasks pertinent to code and several code~LMs have been proposed recently. The majority of the studies in this direction only focus on the improvements in performance of the LMs on different benchmarks, whereas LMs are considered black boxes. Besides this, a handful of works attempt to understand the role of attention layers in the code~LMs. Nonetheless, feed-forward layers remain under-explored which consist of two-thirds of a typical transformer model's parameters. In this work, we attempt to gain insights into the inner workings of code language models by examining the feed-forward layers. To conduct our investigations, we use two state-of-the-art code~LMs, Codegen-Mono and Ploycoder, and three widely used programming languages, Java, Go, and Python. We focus on examining the organization of stored concepts, the editability of these concepts, and the roles of different layers and input context size variations for output generation. Our empirical findings demonstrate that lower layers capture syntactic patterns while higher layers encode abstract concepts and semantics. We show concepts of interest can be edited within feed-forward layers without compromising code~LM performance. Additionally, we observe initial layers serve as ``thinking'' layers, while later layers are crucial for predicting subsequent code tokens. Furthermore, we discover earlier layers can accurately predict smaller contexts, but larger contexts need critical later layers' contributions. We anticipate these findings will facilitate better understanding, debugging, and testing of code~LMs.
Neural Network Pruning Through Constrained Reinforcement Learning
Oct 28, 2021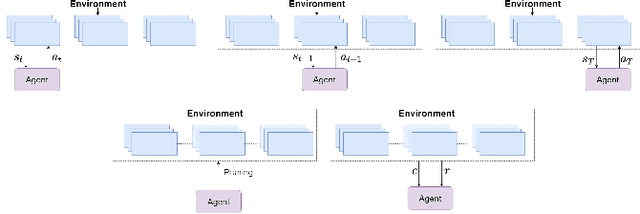
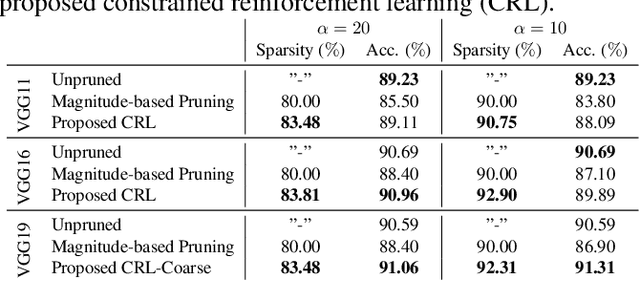
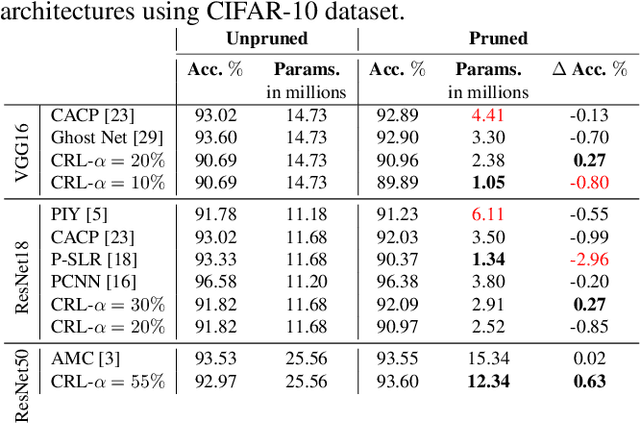
Network pruning reduces the size of neural networks by removing (pruning) neurons such that the performance drop is minimal. Traditional pruning approaches focus on designing metrics to quantify the usefulness of a neuron which is often quite tedious and sub-optimal. More recent approaches have instead focused on training auxiliary networks to automatically learn how useful each neuron is however, they often do not take computational limitations into account. In this work, we propose a general methodology for pruning neural networks. Our proposed methodology can prune neural networks to respect pre-defined computational budgets on arbitrary, possibly non-differentiable, functions. Furthermore, we only assume the ability to be able to evaluate these functions for different inputs, and hence they do not need to be fully specified beforehand. We achieve this by proposing a novel pruning strategy via constrained reinforcement learning algorithms. We prove the effectiveness of our approach via comparison with state-of-the-art methods on standard image classification datasets. Specifically, we reduce 83-92.90 of total parameters on various variants of VGG while achieving comparable or better performance than that of original networks. We also achieved 75.09 reduction in parameters on ResNet18 without incurring any loss in accuracy.
Comprehensive Online Network Pruning via Learnable Scaling Factors
Oct 06, 2020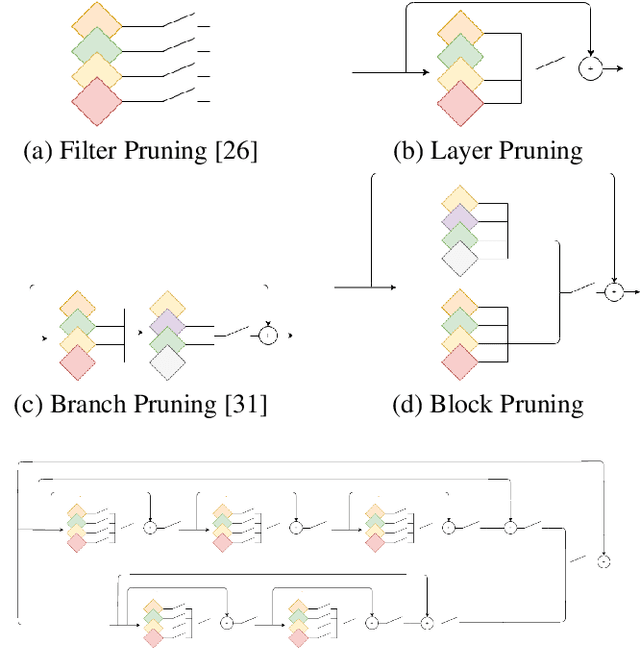

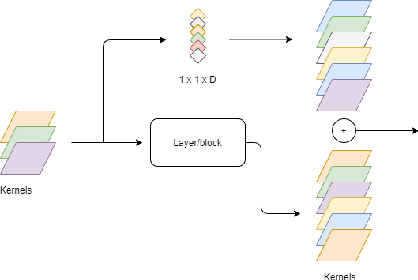

One of the major challenges in deploying deep neural network architectures is their size which has an adverse effect on their inference time and memory requirements. Deep CNNs can either be pruned width-wise by removing filters based on their importance or depth-wise by removing layers and blocks. Width wise pruning (filter pruning) is commonly performed via learnable gates or switches and sparsity regularizers whereas pruning of layers has so far been performed arbitrarily by manually designing a smaller network usually referred to as a student network. We propose a comprehensive pruning strategy that can perform both width-wise as well as depth-wise pruning. This is achieved by introducing gates at different granularities (neuron, filter, layer, block) which are then controlled via an objective function that simultaneously performs pruning at different granularity during each forward pass. Our approach is applicable to wide-variety of architectures without any constraints on spatial dimensions or connection type (sequential, residual, parallel or inception). Our method has resulted in a compression ratio of 70% to 90% without noticeable loss in accuracy when evaluated on benchmark datasets.