 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Online Network Pruning via Learnable Scaling Factors
Paper and Code
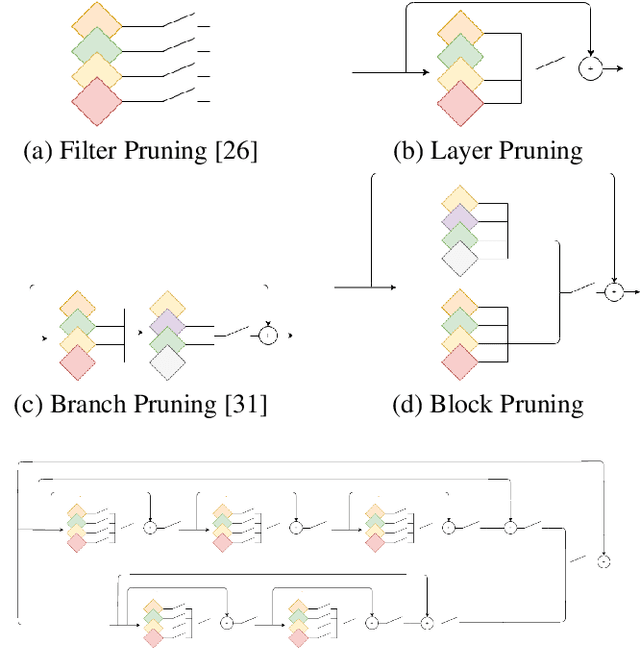

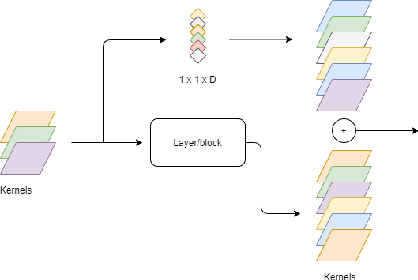

One of the major challenges in deploying deep neural network architectures is their size which has an adverse effect on their inference time and memory requirements. Deep CNNs can either be pruned width-wise by removing filters based on their importance or depth-wise by removing layers and blocks. Width wise pruning (filter pruning) is commonly performed via learnable gates or switches and sparsity regularizers whereas pruning of layers has so far been performed arbitrarily by manually designing a smaller network usually referred to as a student network. We propose a comprehensive pruning strategy that can perform both width-wise as well as depth-wise pruning. This is achieved by introducing gates at different granularities (neuron, filter, layer, block) which are then controlled via an objective function that simultaneously performs pruning at different granularity during each forward pass. Our approach is applicable to wide-variety of architectures without any constraints on spatial dimensions or connection type (sequential, residual, parallel or inception). Our method has resulted in a compression ratio of 70% to 90% without noticeable loss in accuracy when evaluated on benchmark datasets.