 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiver Fibrosis Quantification and Analysis: The LiQA Dataset and Baseline Method
Dec 22, 2025Liver fibrosis represents a significant global health burden, necessitating accurate staging for effective clinical management. This report introduces the LiQA (Liver Fibrosis Quantification and Analysis) dataset, established as part of the CARE 2024 challenge. Comprising $440$ patients with multi-phase, multi-center MRI scans, the dataset is curated to benchmark algorithms for Liver Segmentation (LiSeg) and Liver Fibrosis Staging (LiFS) under complex real-world conditions, including domain shifts, missing modalities, and spatial misalignment. We further describe the challenge's top-performing methodology, which integrates a semi-supervised learning framework with external data for robust segmentation, and utilizes a multi-view consensus approach with Class Activation Map (CAM)-based regularization for staging. Evaluation of this baseline demonstrates that leveraging multi-source data and anatomical constraints significantly enhances model robustness in clinical settings.
CATVis: Context-Aware Thought Visualization
Jul 15, 2025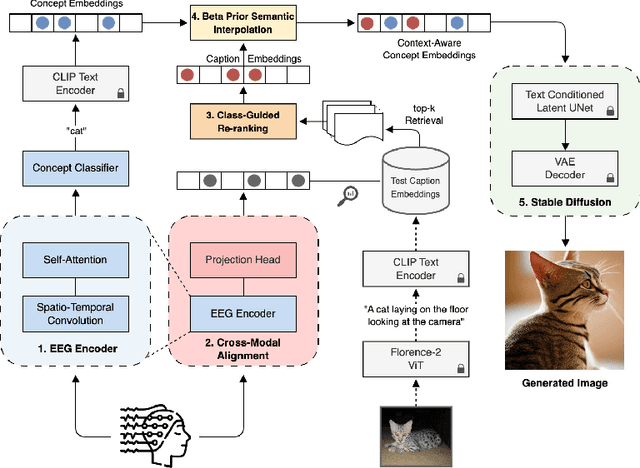
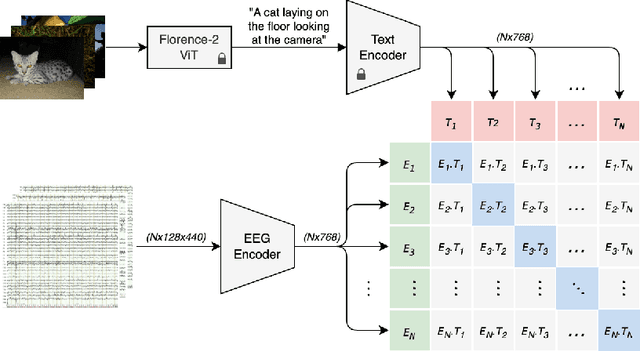
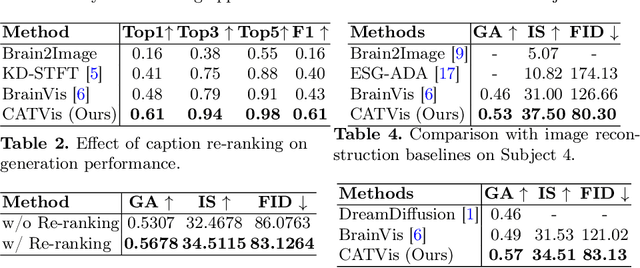

EEG-based brain-computer interfaces (BCIs) have shown promise in various applications, such as motor imagery and cognitive state monitoring. However, decoding visual representations from EEG signals remains a significant challenge due to their complex and noisy nature. We thus propose a novel 5-stage framework for decoding visual representations from EEG signals: (1) an EEG encoder for concept classification, (2) cross-modal alignment of EEG and text embeddings in CLIP feature space, (3) caption refinement via re-ranking, (4) weighted interpolation of concept and caption embeddings for richer semantics, and (5) image generation using a pre-trained Stable Diffusion model. We enable context-aware EEG-to-image generation through cross-modal alignment and re-ranking. Experimental results demonstrate that our method generates high-quality images aligned with visual stimuli, outperforming SOTA approaches by 13.43% in Classification Accuracy, 15.21% in Generation Accuracy and reducing Fr\'echet Inception Distance by 36.61%, indicating superior semantic alignment and image quality.
Building Height Estimation Using Shadow Length in Satellite Imagery
Nov 14, 2024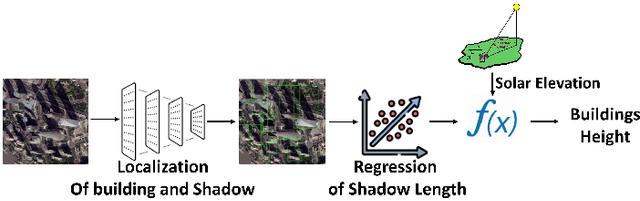
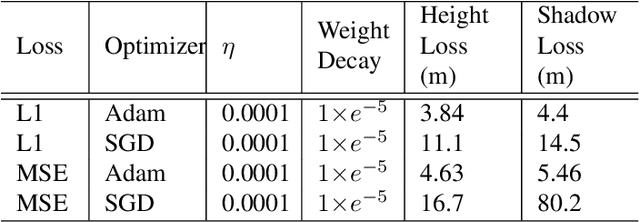
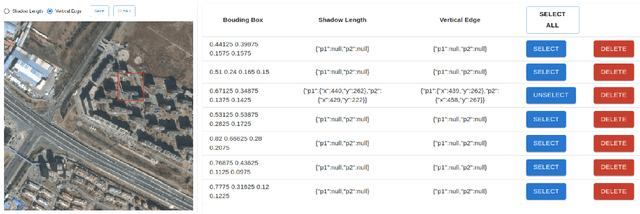
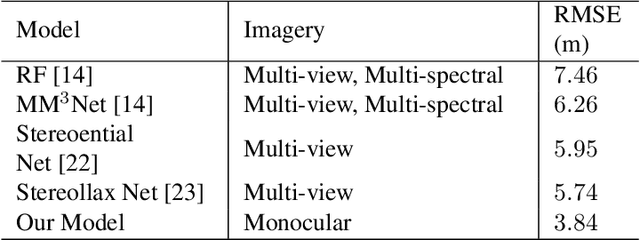
Estimating building height from satellite imagery poses significant challenges, especially when monocular images are employed, resulting in a loss of essential 3D information during imaging. This loss of spatial depth further complicates the height estimation process. We addressed this issue by using shadow length as an additional cue to compensate for the loss of building height estimation using single-view imagery. We proposed a novel method that first localized a building and its shadow in the given satellite image. After localization, the shadow length is estimated using a regression model. To estimate the final height of each building, we utilize the principles of photogrammetry, specifically considering the relationship between the solar elevation angle, the vertical edge length of the building, and the length of the building's shadow. For the localization of buildings in our model, we utilized a modified YOLOv7 detector, and to regress the shadow length for each building we utilized the ResNet18 as backbone architecture. Finally, we estimated the associated building height using solar elevation with shadow length through analytical formulation. We evaluated our method on 42 different cities and the results showed that the proposed framework surpasses the state-of-the-art methods with a suitable margin.
Camera Calibration through Geometric Constraints from Rotation and Projection Matrices
Feb 20, 2024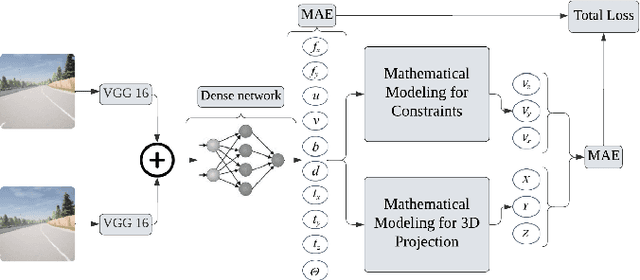
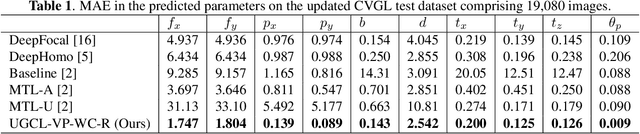
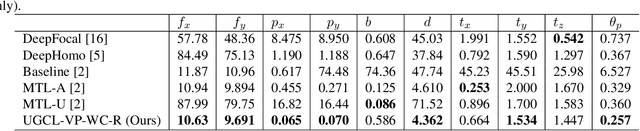

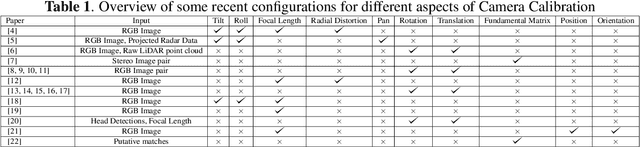
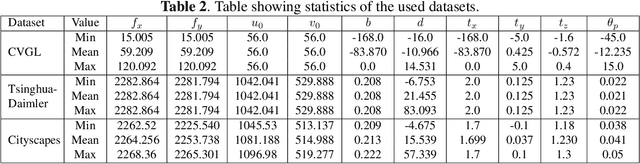
The process of camera calibration involves estimating the intrinsic and extrinsic parameters, which are essential for accurately performing tasks such as 3D reconstruction, object tracking and augmented reality. In this work, we propose a novel constraints-based loss for measuring the intrinsic (focal length: $(f_x, f_y)$ and principal point: $(p_x, p_y)$) and extrinsic (baseline: ($b$), disparity: ($d$), translation: $(t_x, t_y, t_z)$, and rotation specifically pitch: $(\theta_p)$) camera parameters. Our novel constraints are based on geometric properties inherent in the camera model, including the anatomy of the projection matrix (vanishing points, image of world origin, axis planes) and the orthonormality of the rotation matrix. Thus we proposed a novel Unsupervised Geometric Constraint Loss (UGCL) via a multitask learning framework. Our methodology is a hybrid approach that employs the learning power of a neural network to estimate the desired parameters along with the underlying mathematical properties inherent in the camera projection matrix. This distinctive approach not only enhances the interpretability of the model but also facilitates a more informed learning process. Additionally, we introduce a new CVGL Camera Calibration dataset, featuring over 900 configurations of camera parameters, incorporating 63,600 image pairs that closely mirror real-world conditions. By training and testing on both synthetic and real-world datasets, our proposed approach demonstrates improvements across all parameters when compared to the state-of-the-art (SOTA) benchmarks. The code and the updated dataset can be found here: https://github.com/CVLABLUMS/CVGL-Camera-Calibration
Learning adjacency matrix for dynamic graph neural network
Oct 04, 2023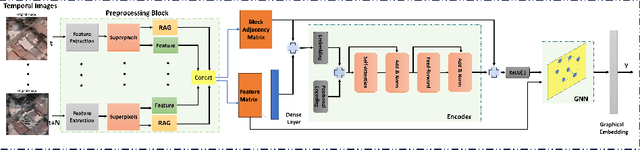
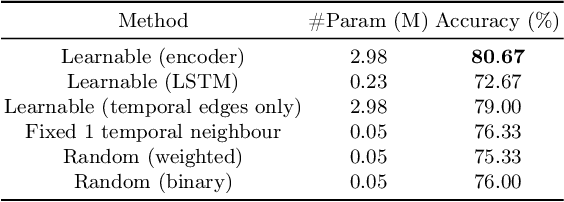
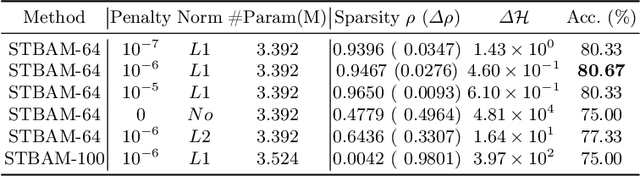
In recent work, [1] introduced the concept of using a Block Adjacency Matrix (BA) for the representation of spatio-temporal data. While their method successfully concatenated adjacency matrices to encapsulate spatio-temporal relationships in a single graph, it formed a disconnected graph. This limitation hampered the ability of Graph Convolutional Networks (GCNs) to perform message passing across nodes belonging to different time steps, as no temporal links were present. To overcome this challenge, we introduce an encoder block specifically designed to learn these missing temporal links. The encoder block processes the BA and predicts connections between previously unconnected subgraphs, resulting in a Spatio-Temporal Block Adjacency Matrix (STBAM). This enriched matrix is then fed into a Graph Neural Network (GNN) to capture the complex spatio-temporal topology of the network. Our evaluations on benchmark datasets, surgVisDom and C2D2, demonstrate that our method, with slightly higher complexity, achieves superior results compared to state-of-the-art results. Our approach's computational overhead remains significantly lower than conventional non-graph-based methodologies for spatio-temporal data.
Mitigating climate and health impact of small-scale kiln industry using multi-spectral classifier and deep learning
Mar 21, 2023



Industrial air pollution has a direct health impact and is a major contributor to climate change. Small scale industries particularly bull-trench brick kilns are one of the major causes of air pollution in South Asia often creating hazardous levels of smog that is injurious to human health. To mitigate the climate and health impact of the kiln industry, fine-grained kiln localization at different geographic locations is needed. Kiln localization using multi-spectral remote sensing data such as vegetation index results in a noisy estimates whereas use of high-resolution imagery is infeasible due to cost and compute complexities. This paper proposes a fusion of spatio-temporal multi-spectral data with high-resolution imagery for detection of brick kilns within the "Brick-Kiln-Belt" of South Asia. We first perform classification using low-resolution spatio-temporal multi-spectral data from Sentinel-2 imagery by combining vegetation, burn, build up and moisture indices. Then orientation aware object detector: YOLOv3 (with theta value) is implemented for removal of false detections and fine-grained localization. Our proposed technique, when compared with other benchmarks, results in a 21x improvement in speed with comparable or higher accuracy when tested over multiple countries.
Multi-task Learning for Camera Calibration
Nov 27, 2022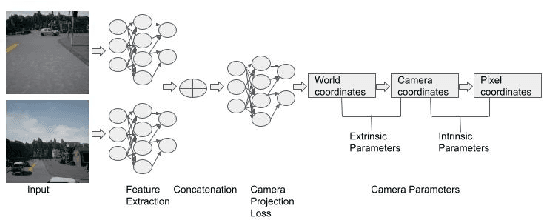
For a number of tasks, such as 3D reconstruction, robotic interface, autonomous driving, etc., camera calibration is essential. In this study, we present a unique method for predicting intrinsic (principal point offset and focal length) and extrinsic (baseline, pitch, and translation) properties from a pair of images. We suggested a novel method where camera model equations are represented as a neural network in a multi-task learning framework, in contrast to existing methods, which build a comprehensive solution. By reconstructing the 3D points using a camera model neural network and then using the loss in reconstruction to obtain the camera specifications, this innovative camera projection loss (CPL) method allows us that the desired parameters should be estimated. As far as we are aware, our approach is the first one that uses an approach to multi-task learning that includes mathematical formulas in a framework for learning to estimate camera parameters to predict both the extrinsic and intrinsic parameters jointly. Additionally, we provided a new dataset named as CVGL Camera Calibration Dataset [1] which has been collected using the CARLA Simulator [2]. Actually, we show that our suggested strategy out performs both conventional methods and methods based on deep learning on 8 out of 10 parameters that were assessed using both real and synthetic data. Our code and generated dataset are available at https://github.com/thanif/Camera-Calibration-through-Camera-Projection-Loss.
Neural Network Pruning Through Constrained Reinforcement Learning
Oct 28, 2021
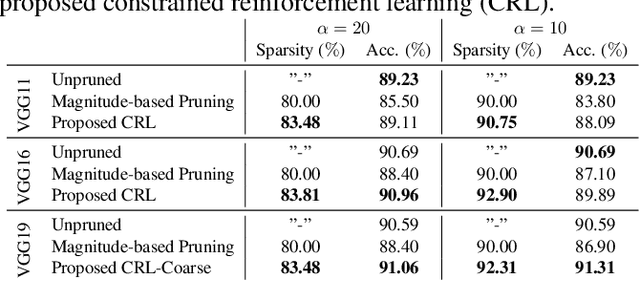
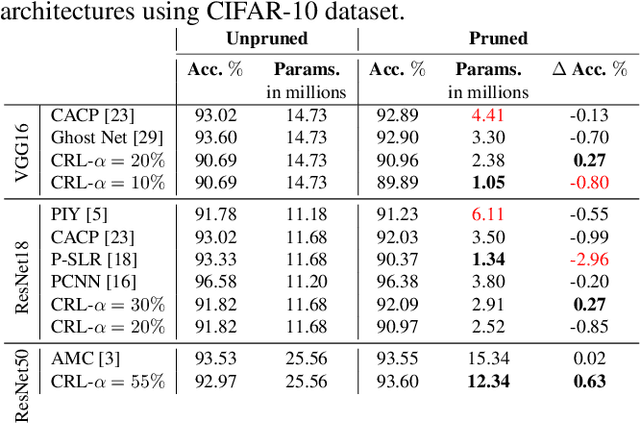
Network pruning reduces the size of neural networks by removing (pruning) neurons such that the performance drop is minimal. Traditional pruning approaches focus on designing metrics to quantify the usefulness of a neuron which is often quite tedious and sub-optimal. More recent approaches have instead focused on training auxiliary networks to automatically learn how useful each neuron is however, they often do not take computational limitations into account. In this work, we propose a general methodology for pruning neural networks. Our proposed methodology can prune neural networks to respect pre-defined computational budgets on arbitrary, possibly non-differentiable, functions. Furthermore, we only assume the ability to be able to evaluate these functions for different inputs, and hence they do not need to be fully specified beforehand. We achieve this by proposing a novel pruning strategy via constrained reinforcement learning algorithms. We prove the effectiveness of our approach via comparison with state-of-the-art methods on standard image classification datasets. Specifically, we reduce 83-92.90 of total parameters on various variants of VGG while achieving comparable or better performance than that of original networks. We also achieved 75.09 reduction in parameters on ResNet18 without incurring any loss in accuracy.
Camera Calibration through Camera Projection Loss
Oct 07, 2021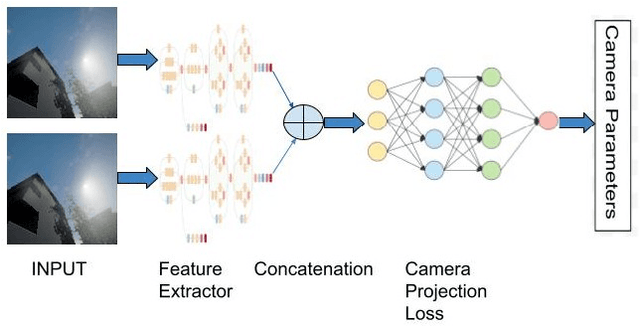



Camera calibration is a necessity in various tasks including 3D reconstruction, hand-eye coordination for a robotic interaction, autonomous driving, etc. In this work we propose a novel method to predict extrinsic (baseline, pitch, and translation), intrinsic (focal length and principal point offset) parameters using an image pair. Unlike existing methods, instead of designing an end-to-end solution, we proposed a new representation that incorporates camera model equations as a neural network in multi-task learning framework. We estimate the desired parameters via novel \emph{camera projection loss} (CPL) that uses the camera model neural network to reconstruct the 3D points and uses the reconstruction loss to estimate the camera parameters. To the best of our knowledge, ours is the first method to jointly estimate both the intrinsic and extrinsic parameters via a multi-task learning methodology that combines analytical equations in learning framework for the estimation of camera parameters. We also proposed a novel dataset using CARLA Simulator. Empirically, we demonstrate that our proposed approach achieves better performance with respect to both deep learning-based and traditional methods on 7 out of 10 parameters evaluated using both synthetic and real data. Our code and generated dataset will be made publicly available to facilitate future research.
Survey of Image Based Graph Neural Networks
Jun 11, 2021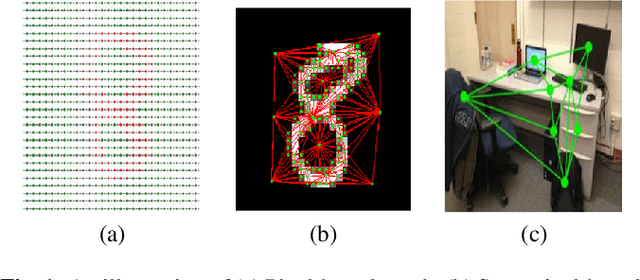



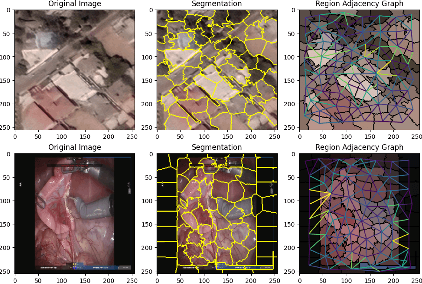
In this survey paper, we analyze image based graph neural networks and propose a three-step classification approach. We first convert the image into superpixels using the Quickshift algorithm so as to reduce 30% of the input data. The superpixels are subsequently used to generate a region adjacency graph. Finally, the graph is passed through a state-of-art graph convolutional neural network to get classification scores. We also analyze the spatial and spectral convolution filtering techniques in graph neural networks. Spectral-based models perform better than spatial-based models and classical CNN with lesser compute cost.