 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Overtakes in Trucks Using CAN Data
Apr 08, 2024



Safe overtakes in trucks are crucial to prevent accidents, reduce congestion, and ensure efficient traffic flow, making early prediction essential for timely and informed driving decisions. Accordingly, we investigate the detection of truck overtakes from CAN data. Three classifiers, Artificial Neural Networks (ANN), Random Forest, and Support Vector Machines (SVM), are employed for the task. Our analysis covers up to 10 seconds before the overtaking event, using an overlapping sliding window of 1 second to extract CAN features. We observe that the prediction scores of the overtake class tend to increase as we approach the overtake trigger, while the no-overtake class remain stable or oscillates depending on the classifier. Thus, the best accuracy is achieved when approaching the trigger, making early overtaking prediction challenging. The classifiers show good accuracy in classifying overtakes (Recall/TPR > 93%), but accuracy is suboptimal in classifying no-overtakes (TNR typically 80-90% and below 60% for one SVM variant). We further combine two classifiers (Random Forest and linear SVM) by averaging their output scores. The fusion is observed to improve no-overtake classification (TNR > 92%) at the expense of reducing overtake accuracy (TPR). However, the latter is kept above 91% near the overtake trigger. Therefore, the fusion balances TPR and TNR, providing more consistent performance than individual classifiers.
Multi-task Learning for Camera Calibration
Nov 27, 2022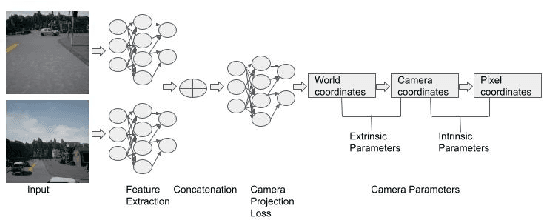
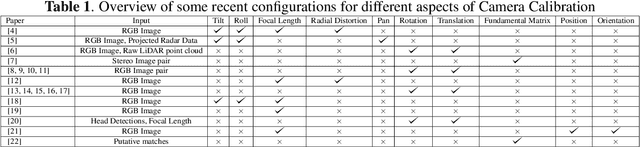
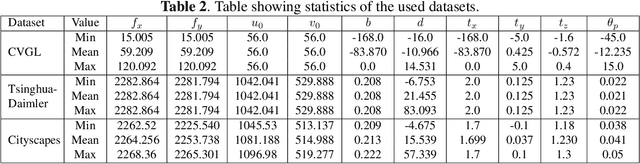
For a number of tasks, such as 3D reconstruction, robotic interface, autonomous driving, etc., camera calibration is essential. In this study, we present a unique method for predicting intrinsic (principal point offset and focal length) and extrinsic (baseline, pitch, and translation) properties from a pair of images. We suggested a novel method where camera model equations are represented as a neural network in a multi-task learning framework, in contrast to existing methods, which build a comprehensive solution. By reconstructing the 3D points using a camera model neural network and then using the loss in reconstruction to obtain the camera specifications, this innovative camera projection loss (CPL) method allows us that the desired parameters should be estimated. As far as we are aware, our approach is the first one that uses an approach to multi-task learning that includes mathematical formulas in a framework for learning to estimate camera parameters to predict both the extrinsic and intrinsic parameters jointly. Additionally, we provided a new dataset named as CVGL Camera Calibration Dataset [1] which has been collected using the CARLA Simulator [2]. Actually, we show that our suggested strategy out performs both conventional methods and methods based on deep learning on 8 out of 10 parameters that were assessed using both real and synthetic data. Our code and generated dataset are available at https://github.com/thanif/Camera-Calibration-through-Camera-Projection-Loss.
Camera Calibration through Camera Projection Loss
Oct 07, 2021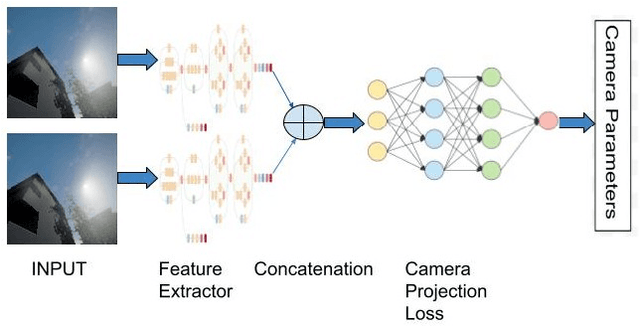



Camera calibration is a necessity in various tasks including 3D reconstruction, hand-eye coordination for a robotic interaction, autonomous driving, etc. In this work we propose a novel method to predict extrinsic (baseline, pitch, and translation), intrinsic (focal length and principal point offset) parameters using an image pair. Unlike existing methods, instead of designing an end-to-end solution, we proposed a new representation that incorporates camera model equations as a neural network in multi-task learning framework. We estimate the desired parameters via novel \emph{camera projection loss} (CPL) that uses the camera model neural network to reconstruct the 3D points and uses the reconstruction loss to estimate the camera parameters. To the best of our knowledge, ours is the first method to jointly estimate both the intrinsic and extrinsic parameters via a multi-task learning methodology that combines analytical equations in learning framework for the estimation of camera parameters. We also proposed a novel dataset using CARLA Simulator. Empirically, we demonstrate that our proposed approach achieves better performance with respect to both deep learning-based and traditional methods on 7 out of 10 parameters evaluated using both synthetic and real data. Our code and generated dataset will be made publicly available to facilitate future research.