 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATVis: Context-Aware Thought Visualization
Jul 15, 2025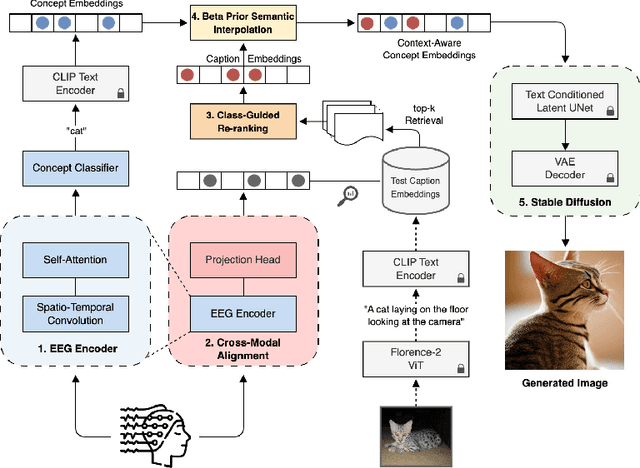
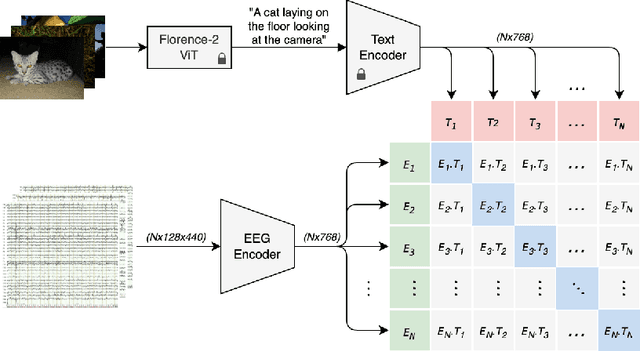
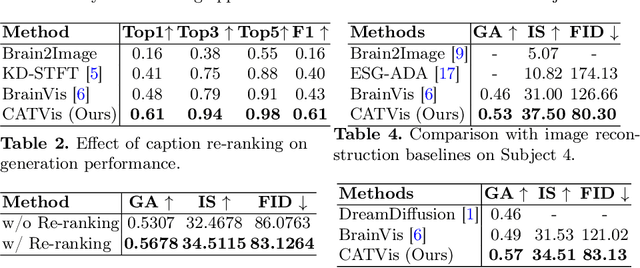

EEG-based brain-computer interfaces (BCIs) have shown promise in various applications, such as motor imagery and cognitive state monitoring. However, decoding visual representations from EEG signals remains a significant challenge due to their complex and noisy nature. We thus propose a novel 5-stage framework for decoding visual representations from EEG signals: (1) an EEG encoder for concept classification, (2) cross-modal alignment of EEG and text embeddings in CLIP feature space, (3) caption refinement via re-ranking, (4) weighted interpolation of concept and caption embeddings for richer semantics, and (5) image generation using a pre-trained Stable Diffusion model. We enable context-aware EEG-to-image generation through cross-modal alignment and re-ranking. Experimental results demonstrate that our method generates high-quality images aligned with visual stimuli, outperforming SOTA approaches by 13.43% in Classification Accuracy, 15.21% in Generation Accuracy and reducing Fr\'echet Inception Distance by 36.61%, indicating superior semantic alignment and image quality.
Language Independent Sentiment Analysis
Jan 23, 2020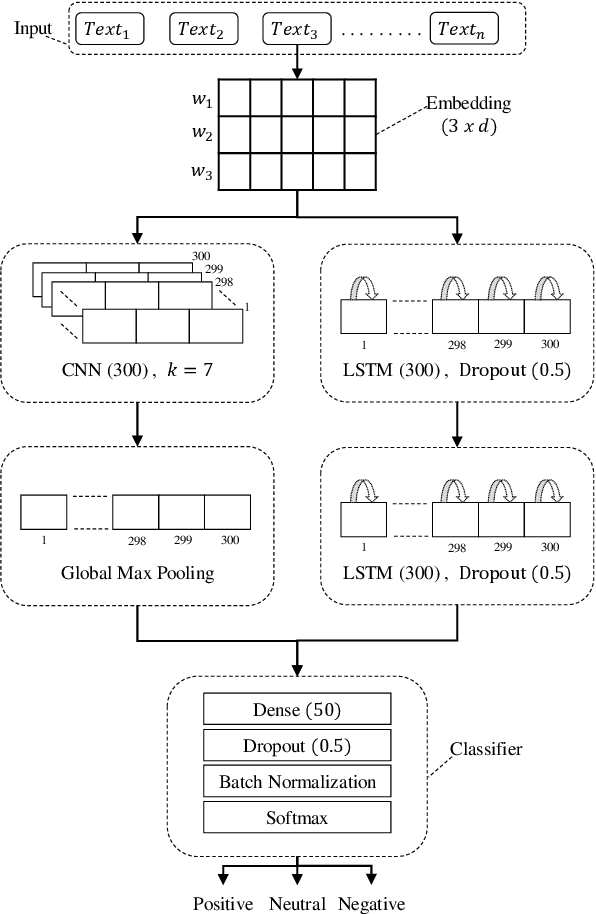
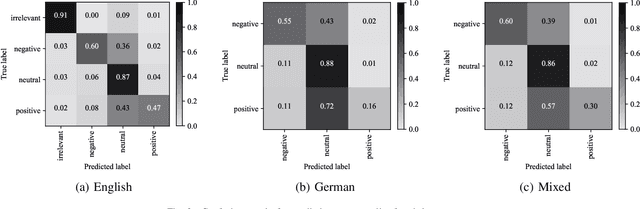

Social media platforms and online forums generate rapid and increasing amount of textual data. Businesses, government agencies, and media organizations seek to perform sentiment analysis on this rich text data. The results of these analytics are used for adapting marketing strategies, customizing products, security and various other decision makings. Sentiment analysis has been extensively studied and various methods have been developed for it with great success. These methods, however apply to texts written in a specific language. This limits applicability to a limited demographic and a specific geographic region. In this paper we propose a general approach for sentiment analysis on data containing texts from multiple languages. This enables all the applications to utilize the results of sentiment analysis in a language oblivious or language-independent fashion.
Adapting Deep Learning for Sentiment Classification of Code-Switched Informal Short Text
Jan 04, 2020
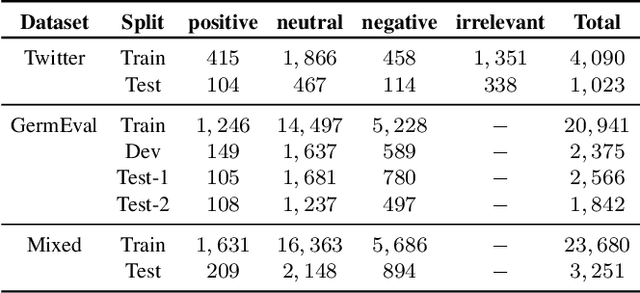
Nowadays, an abundance of short text is being generated that uses nonstandard writing styles influenced by regional languages. Such informal and code-switched content are under-resourced in terms of labeled datasets and language models even for popular tasks like sentiment classification. In this work, we (1) present a labeled dataset called MultiSenti for sentiment classification of code-switched informal short text, (2) explore the feasibility of adapting resources from a resource-rich language for an informal one, and (3) propose a deep learning-based model for sentiment classification of code-switched informal short text. We aim to achieve this without any lexical normalization, language translation, or code-switching indication. The performance of the proposed models is compared with three existing multilingual sentiment classification models. The results show that the proposed model performs better in general and adapting character-based embeddings yield equivalent performance while being computationally more efficient than training word-based domain-specific embeddings.
Predicting Attributes of Nodes Using Network Structure
Dec 27, 2019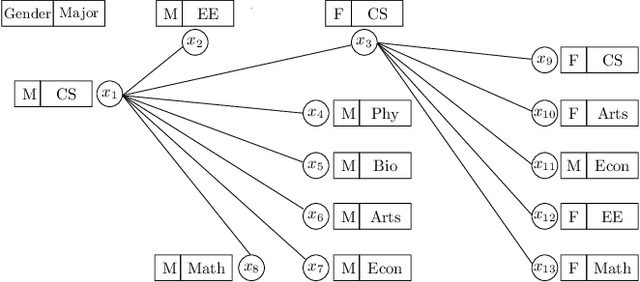
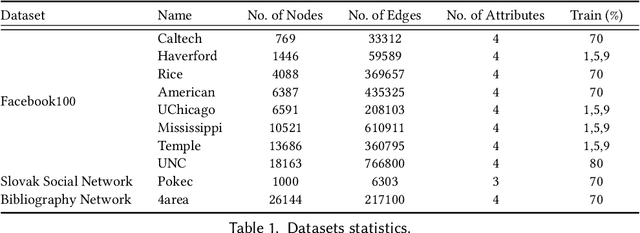
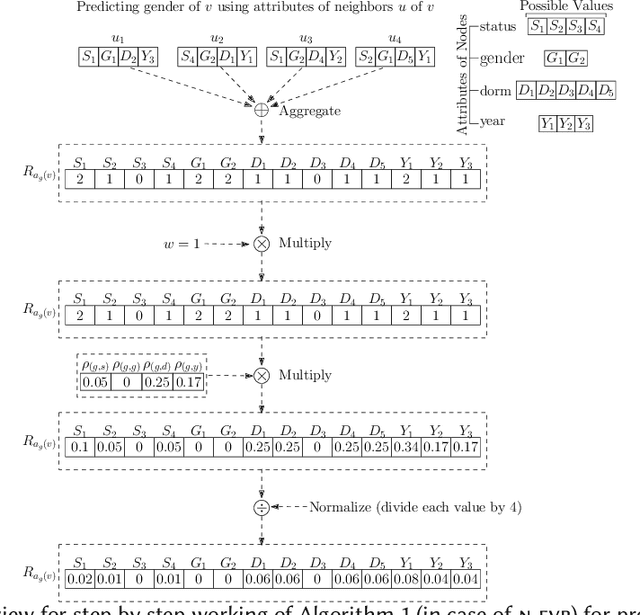
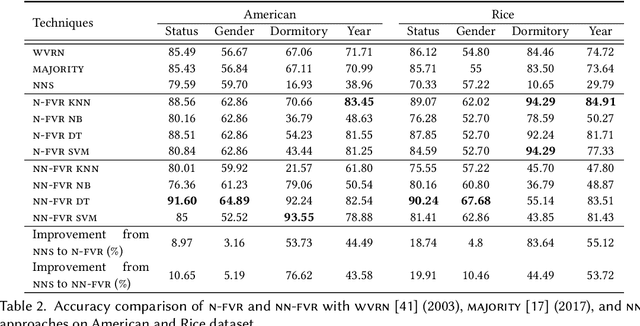
In many graphs such as social networks, nodes have associated attributes representing their behavior. Predicting node attributes in such graphs is an important problem with applications in many domains like recommendation systems, privacy preservation, and targeted advertisement. Attributes values can be predicted by analyzing patterns and correlations among attributes and employing classification/regression algorithms. However, these approaches do not utilize readily available network topology information. In this regard, interconnections between different attributes of nodes can be exploited to improve the prediction accuracy. In this paper, we propose an approach to represent a node by a feature map with respect to an attribute $a_i$ (which is used as input for machine learning algorithms) using all attributes of neighbors to predict attributes values for $a_i$. We perform extensive experimentation on ten real-world datasets and show that the proposed feature map significantly improves the prediction accuracy as compared to baseline approaches on these datasets.
A Multi-cascaded Model with Data Augmentation for Enhanced Paraphrase Detection in Short Texts
Dec 27, 2019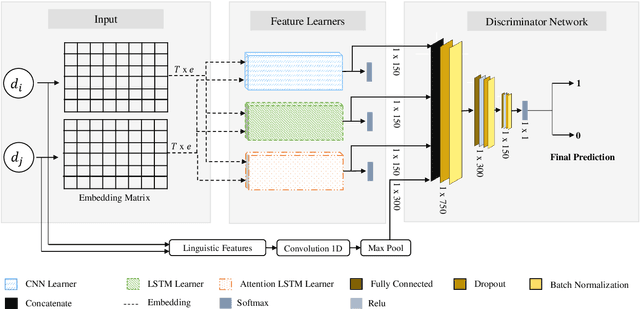
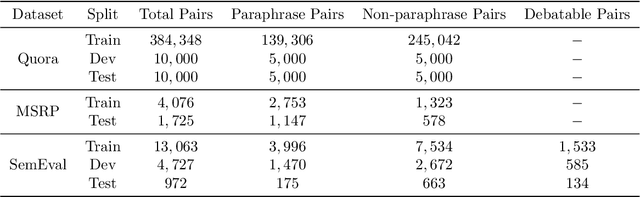
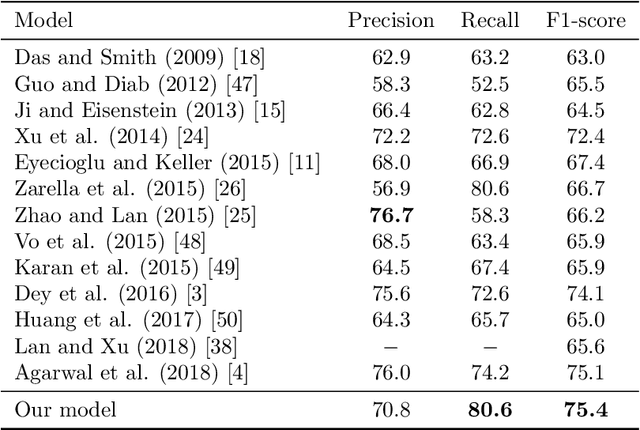
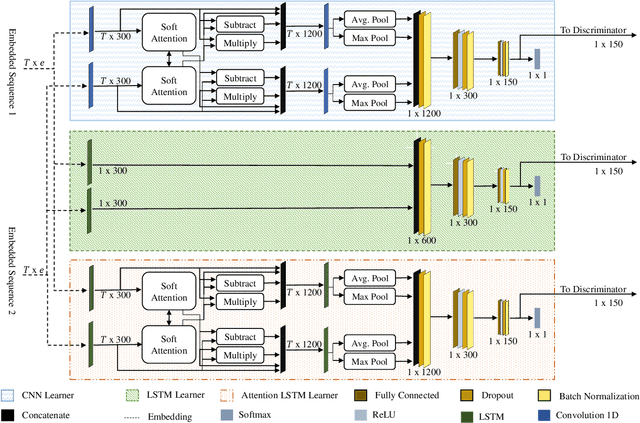
Paraphrase detection is an important task in text analytics with numerous applications such as plagiarism detection, duplicate question identification, and enhanced customer support helpdesks. Deep models have been proposed for representing and classifying paraphrases. These models, however, require large quantities of human-labeled data, which is expensive to obtain. In this work, we present a data augmentation strategy and a multi-cascaded model for improved paraphrase detection in short texts. Our data augmentation strategy considers the notions of paraphrases and non-paraphrases as binary relations over the set of texts. Subsequently, it uses graph theoretic concepts to efficiently generate additional paraphrase and non-paraphrase pairs in a sound manner. Our multi-cascaded model employs three supervised feature learners (cascades) based on CNN and LSTM networks with and without soft-attention. The learned features, together with hand-crafted linguistic features, are then forwarded to a discriminator network for final classification. Our model is both wide and deep and provides greater robustness across clean and noisy short texts. We evaluate our approach on three benchmark datasets and show that it produces a comparable or state-of-the-art performance on all three.
Efficient Data Analytics on Augmented Similarity Triplets
Dec 27, 2019

Many machine learning methods (classification, clustering, etc.) start with a known kernel that provides similarity or distance measure between two objects. Recent work has extended this to situations where the information about objects is limited to comparisons of distances between three objects (triplets). Humans find the comparison task much easier than the estimation of absolute similarities, so this kind of data can be easily obtained using crowd-sourcing. In this work, we give an efficient method of augmenting the triplets data, by utilizing additional implicit information inferred from the existing data. Triplets augmentation improves the quality of kernel-based and kernel-free data analytics tasks. Secondly, we also propose a novel set of algorithms for common supervised and unsupervised machine learning tasks based on triplets. These methods work directly with triplets, avoiding kernel evaluations. Experimental evaluation on real and synthetic datasets shows that our methods are more accurate than the current best-known techniques.
Patch-based Generative Adversarial Network Towards Retinal Vessel Segmentation
Dec 22, 2019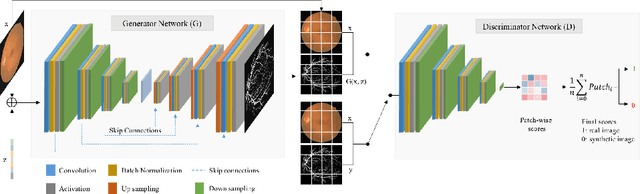
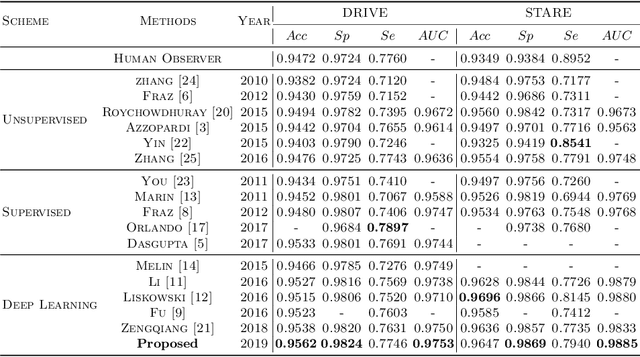
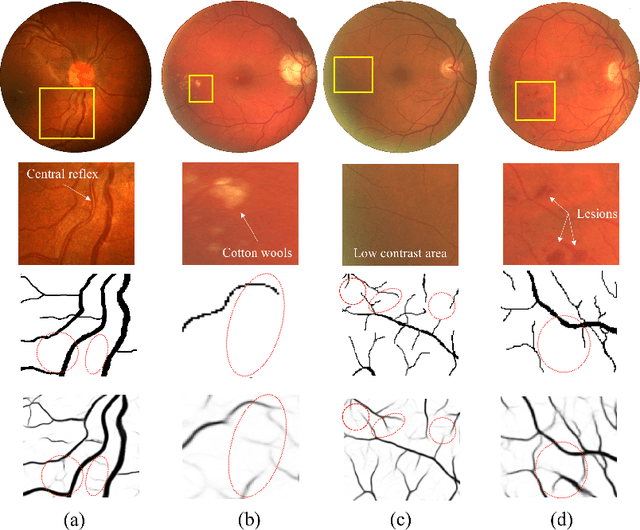
Retinal blood vessels are considered to be the reliable diagnostic biomarkers of ophthalmologic and diabetic retinopathy. Monitoring and diagnosis totally depends on expert analysis of both thin and thick retinal vessels which has recently been carried out by various artificial intelligent techniques. Existing deep learning methods attempt to segment retinal vessels using a unified loss function optimized for both thin and thick vessels with equal importance. Due to variable thickness, biased distribution, and difference in spatial features of thin and thick vessels, unified loss function are more influential towards identification of thick vessels resulting in weak segmentation. To address this problem, a conditional patch-based generative adversarial network is proposed which utilizes a generator network and a patch-based discriminator network conditioned on the sample data with an additional loss function to learn both thin and thick vessels. Experiments are conducted on publicly available STARE and DRIVE datasets which show that the proposed model outperforms the state-of-the-art methods.
A Multi-cascaded Deep Model for Bilingual SMS Classification
Nov 29, 2019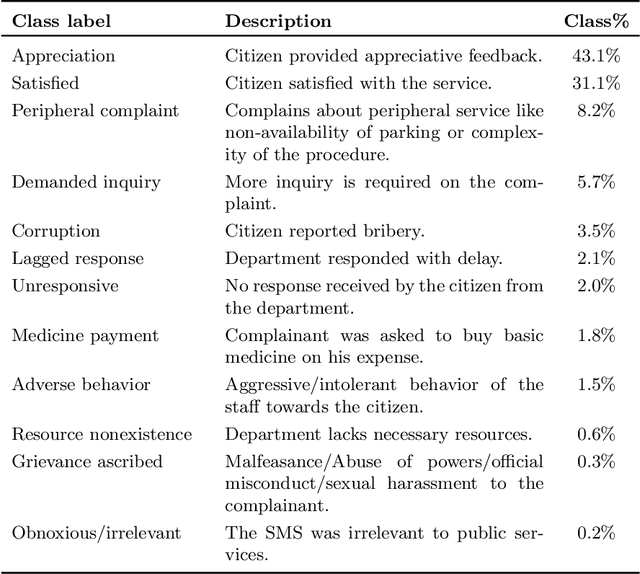
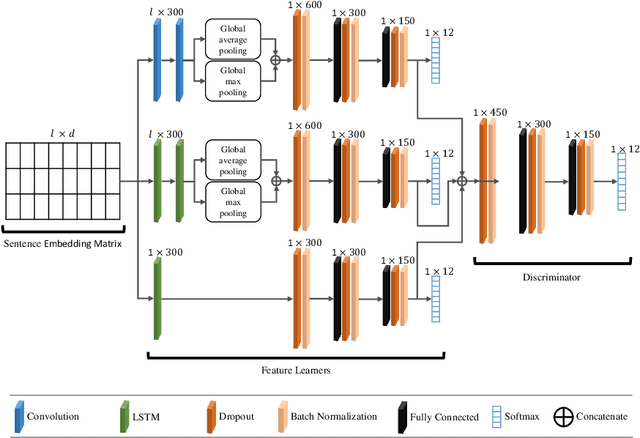

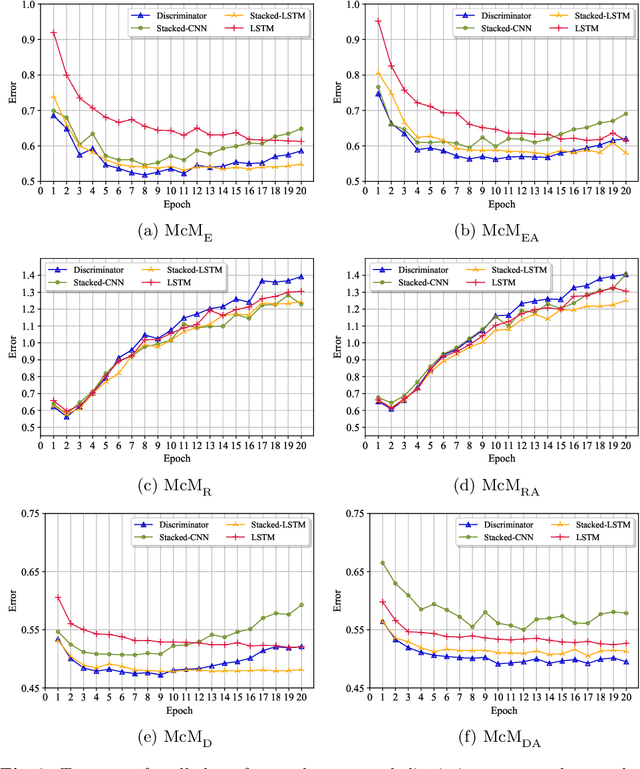
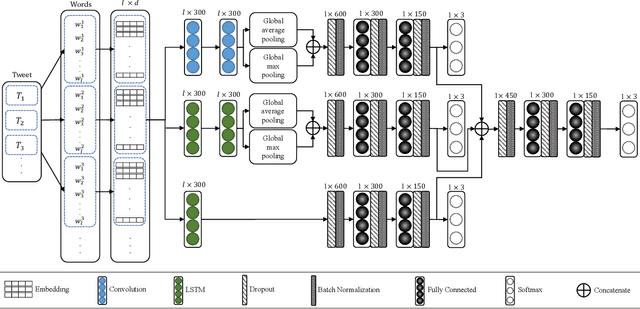
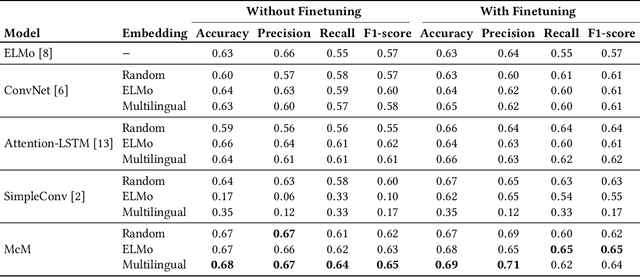
Most studies on text classification are focused on the English language. However, short texts such as SMS are influenced by regional languages. This makes the automatic text classification task challenging due to the multilingual, informal, and noisy nature of language in the text. In this work, we propose a novel multi-cascaded deep learning model called McM for bilingual SMS classification. McM exploits $n$-gram level information as well as long-term dependencies of text for learning. Our approach aims to learn a model without any code-switching indication, lexical normalization, language translation, or language transliteration. The model relies entirely upon the text as no external knowledge base is utilized for learning. For this purpose, a 12 class bilingual text dataset is developed from SMS feedbacks of citizens on public services containing mixed Roman Urdu and English languages. Our model achieves high accuracy for classification on this dataset and outperforms the previous model for multilingual text classification, highlighting language independence of McM.