 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMP: A Context-Aware Cricket Players Performance Metric
Jul 14, 2023Cricket is the second most popular sport after soccer in terms of viewership. However, the assessment of individual player performance, a fundamental task in team sports, is currently primarily based on aggregate performance statistics, including average runs and wickets taken. We propose Context-Aware Metric of player Performance, CAMP, to quantify individual players' contributions toward a cricket match outcome. CAMP employs data mining methods and enables effective data-driven decision-making for selection and drafting, coaching and training, team line-ups, and strategy development. CAMP incorporates the exact context of performance, such as opponents' strengths and specific circumstances of games, such as pressure situations. We empirically evaluate CAMP on data of limited-over cricket matches between 2001 and 2019. In every match, a committee of experts declares one player as the best player, called Man of the M}atch (MoM). The top two rated players by CAMP match with MoM in 83\% of the 961 games. Thus, the CAMP rating of the best player closely matches that of the domain experts. By this measure, CAMP significantly outperforms the current best-known players' contribution measure based on the Duckworth-Lewis-Stern (DLS) method.
Impact Of Missing Data Imputation On The Fairness And Accuracy Of Graph Node Classifiers
Nov 01, 2022Analysis of the fairness of machine learning (ML) algorithms recently attracted many researchers' interest. Most ML methods show bias toward protected groups, which limits the applicability of ML models in many applications like crime rate prediction etc. Since the data may have missing values which, if not appropriately handled, are known to further harmfully affect fairness. Many imputation methods are proposed to deal with missing data. However, the effect of missing data imputation on fairness is not studied well. In this paper, we analyze the effect on fairness in the context of graph data (node attributes) imputation using different embedding and neural network methods. Extensive experiments on six datasets demonstrate severe fairness issues in missing data imputation under graph node classification. We also find that the choice of the imputation method affects both fairness and accuracy. Our results provide valuable insights into graph data fairness and how to handle missingness in graphs efficiently. This work also provides directions regarding theoretical studies on fairness in graph data.
Efficient Approximate Kernel Based Spike Sequence Classification
Sep 11, 2022
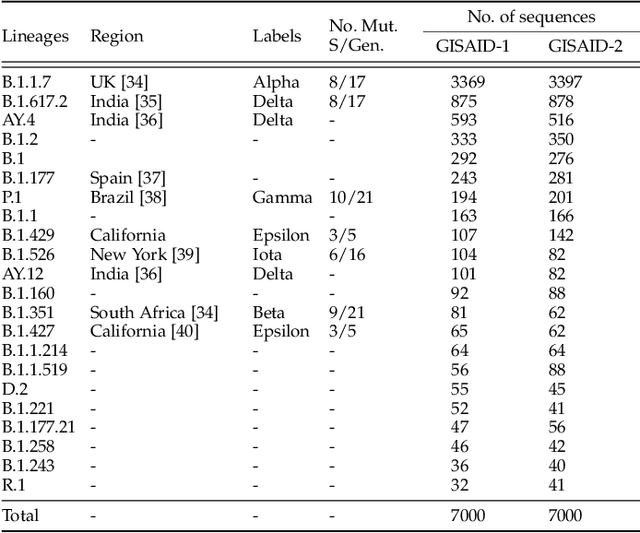
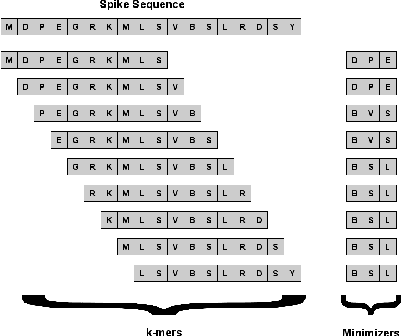
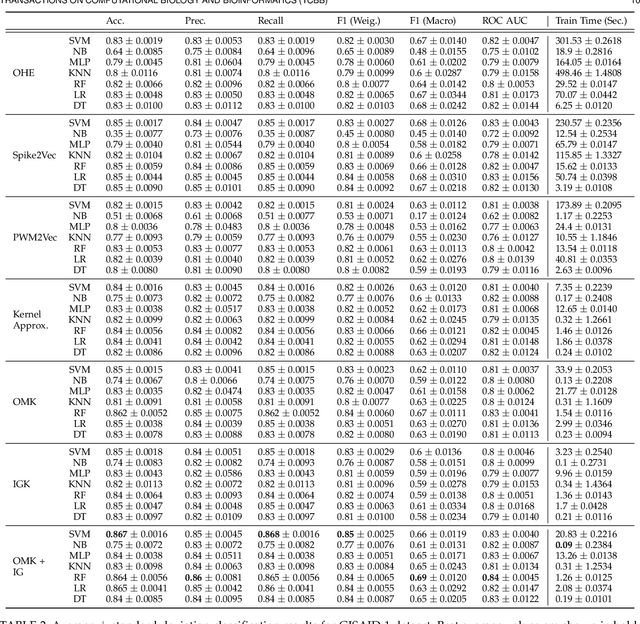
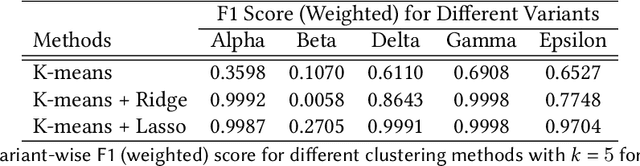
Machine learning (ML) models, such as SVM, for tasks like classification and clustering of sequences, require a definition of distance/similarity between pairs of sequences. Several methods have been proposed to compute the similarity between sequences, such as the exact approach that counts the number of matches between $k$-mers (sub-sequences of length $k$) and an approximate approach that estimates pairwise similarity scores. Although exact methods yield better classification performance, they pose high computational costs, limiting their applicability to a small number of sequences. The approximate algorithms are proven to be more scalable and perform comparably to (sometimes better than) the exact methods -- they are designed in a "general" way to deal with different types of sequences (e.g., music, protein, etc.). Although general applicability is a desired property of an algorithm, it is not the case in all scenarios. For example, in the current COVID-19 (coronavirus) pandemic, there is a need for an approach that can deal specifically with the coronavirus. To this end, we propose a series of ways to improve the performance of the approximate kernel (using minimizers and information gain) in order to enhance its predictive performance pm coronavirus sequences. More specifically, we improve the quality of the approximate kernel using domain knowledge (computed using information gain) and efficient preprocessing (using minimizers computation) to classify coronavirus spike protein sequences corresponding to different variants (e.g., Alpha, Beta, Gamma). We report results using different classification and clustering algorithms and evaluate their performance using multiple evaluation metrics. Using two datasets, we show that our proposed method helps improve the kernel's performance compared to the baseline and state-of-the-art approaches in the healthcare domain.
Effective and scalable clustering of SARS-CoV-2 sequences
Sep 10, 2021
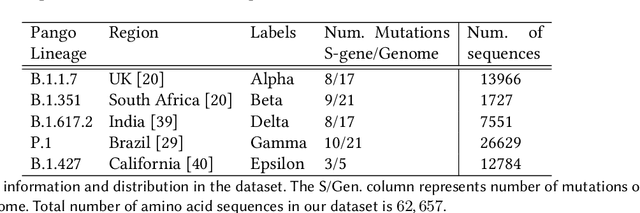
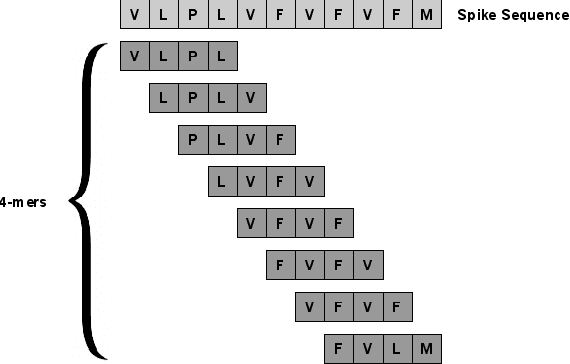
SARS-CoV-2, like any other virus, continues to mutate as it spreads, according to an evolutionary process. Unlike any other virus, the number of currently available sequences of SARS-CoV-2 in public databases such as GISAID is already several million. This amount of data has the potential to uncover the evolutionary dynamics of a virus like never before. However, a million is already several orders of magnitude beyond what can be processed by the traditional methods designed to reconstruct a virus's evolutionary history, such as those that build a phylogenetic tree. Hence, new and scalable methods will need to be devised in order to make use of the ever increasing number of viral sequences being collected. Since identifying variants is an important part of understanding the evolution of a virus, in this paper, we propose an approach based on clustering sequences to identify the current major SARS-CoV-2 variants. Using a $k$-mer based feature vector generation and efficient feature selection methods, our approach is effective in identifying variants, as well as being efficient and scalable to millions of sequences. Such a clustering method allows us to show the relative proportion of each variant over time, giving the rate of spread of each variant in different locations -- something which is important for vaccine development and distribution. We also compute the importance of each amino acid position of the spike protein in identifying a given variant in terms of information gain. Positions of high variant-specific importance tend to agree with those reported by the USA's Centers for Disease Control and Prevention (CDC), further demonstrating our approach.
Effect of Analysis Window and Feature Selection on Classification of Hand Movements Using EMG Signal
Feb 13, 2020
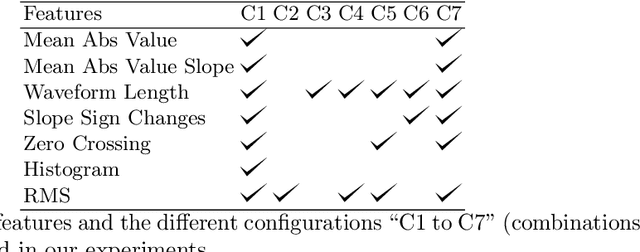


Electromyography (EMG) signals have been successfully employed for driving prosthetic limbs of a single or double degree of freedom. This principle works by using the amplitude of the EMG signals to decide between one or two simpler movements. This method underperforms as compare to the contemporary advances done at the mechanical, electronics, and robotics end, and it lacks intuition. Recently, research on myoelectric control based on pattern recognition (PR) shows promising results with the aid of machine learning classifiers. Using the approach termed as, EMG-PR, EMG signals are divided into analysis windows, and features are extracted for each window. These features are then fed to the machine learning classifiers as input. By offering multiple class movements and intuitive control, this method has the potential to power an amputated subject to perform everyday life movements. In this paper, we investigate the effect of the analysis window and feature selection on classification accuracy of different hand and wrist movements using time-domain features. We show that effective data preprocessing and optimum feature selection helps to improve the classification accuracy of hand movements. We use publicly available hand and wrist gesture dataset of $40$ intact subjects for experimentation. Results computed using different classification algorithms show that the proposed preprocessing and features selection outperforms the baseline and achieve up to $98\%$ classification accuracy.
Fair Allocation Based Soft Load Shedding
Feb 02, 2020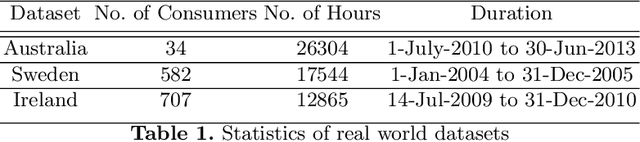
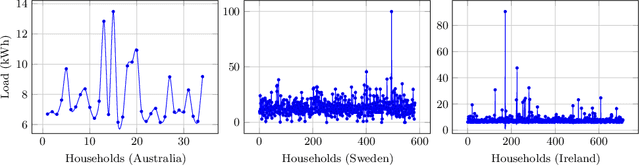
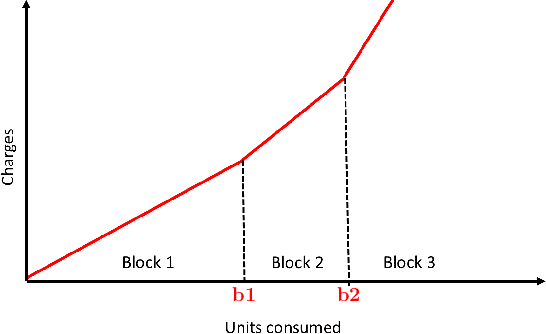
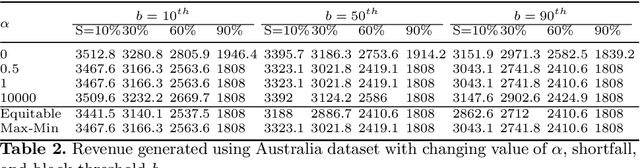
Renewable sources are taking center stage in electricity generation. Due to the intermittent nature of these renewable resources, the problem of the demand-supply gap arises. To solve this problem, several techniques have been proposed in the literature in terms of cost (adding peaker plants), availability of data (Demand Side Management "DSM"), hardware infrastructure (appliance controlling DSM) and safety (voltage reduction). However, these solutions are not fair in terms of electricity distribution. In many cases, although the available supply may not match the demand in peak hours, however, the total aggregated demand remains less than the total supply for the whole day. Load shedding (complete blackout) is a commonly used solution to deal with the demand-supply gap, which can cause substantial economic losses. To solve the demand-supply gap problem, we propose a solution called Soft Load Shedding (SLS), which assigns electricity quota to each household in a fair way. We measure the fairness of SLS by defining a function for household satisfaction level. We model the household utilities by parametric function and formulate the problem of SLS as a social welfare problem. We also consider revenue generated from the fair allocation as a performance measure. To evaluate our approach, extensive experiments have been performed on both synthetic and real-world datasets, and our model is compared with several baselines to show its effectiveness in terms of fair allocation and revenue generation.
Hour-Ahead Load Forecasting Using AMI Data
Jan 08, 2020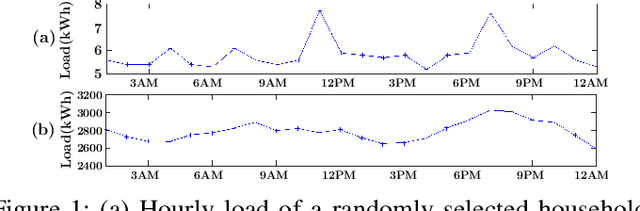
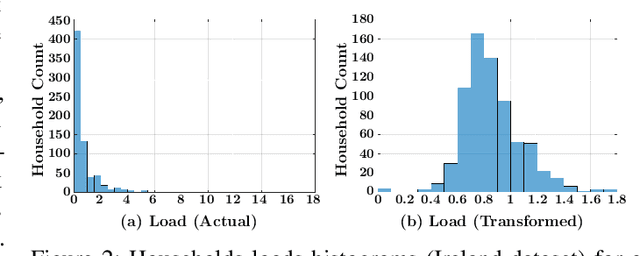


Accurate short-term load forecasting is essential for efficient operation of the power sector. Predicting load at a fine granularity such as individual households or buildings is challenging due to higher volatility and uncertainty in the load. In aggregate loads such as at grids level, the inherent stochasticity and fluctuations are averaged-out, the problem becomes substantially easier. We propose an approach for short-term load forecasting at individual consumers (households) level, called Forecasting using Matrix Factorization (FMF). FMF does not use any consumers' demographic or activity patterns information. Therefore, it can be applied to any locality with the readily available smart meters and weather data. We perform extensive experiments on three benchmark datasets and demonstrate that FMF significantly outperforms the computationally expensive state-of-the-art methods for this problem. We achieve up to 26.5% and 24.4 % improvement in RMSE over Regression Tree and Support Vector Machine, respectively and up to 36% and 73.2% improvement in MAPE over Random Forest and Long Short-Term Memory neural network, respectively.
Predicting Attributes of Nodes Using Network Structure
Dec 27, 2019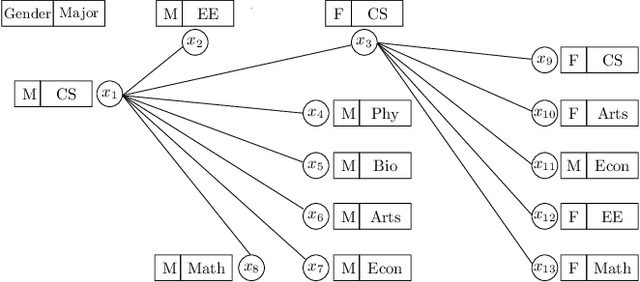
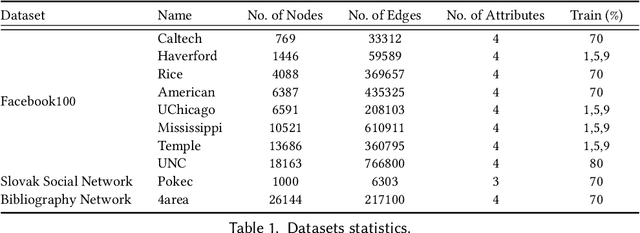
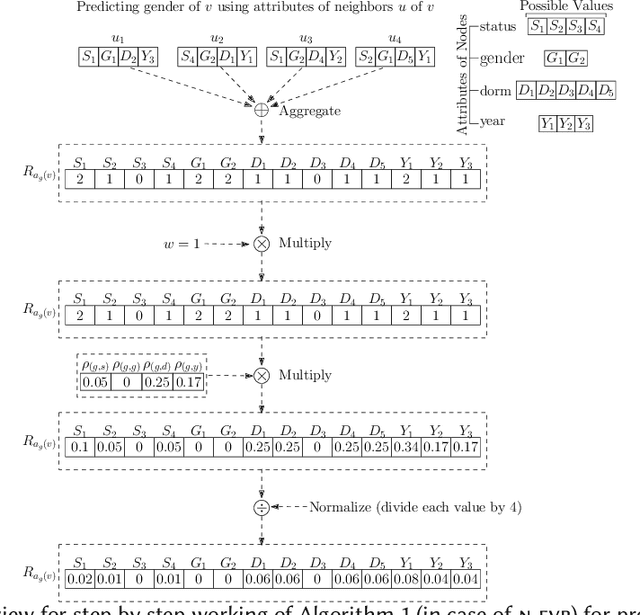
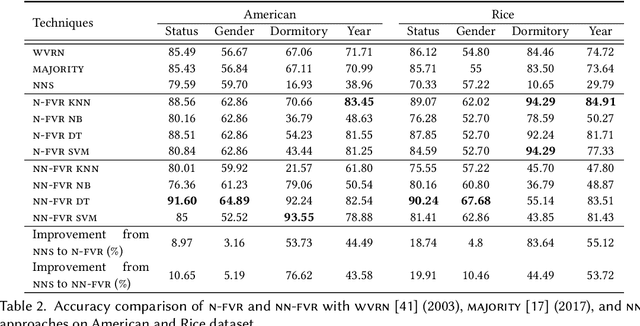
In many graphs such as social networks, nodes have associated attributes representing their behavior. Predicting node attributes in such graphs is an important problem with applications in many domains like recommendation systems, privacy preservation, and targeted advertisement. Attributes values can be predicted by analyzing patterns and correlations among attributes and employing classification/regression algorithms. However, these approaches do not utilize readily available network topology information. In this regard, interconnections between different attributes of nodes can be exploited to improve the prediction accuracy. In this paper, we propose an approach to represent a node by a feature map with respect to an attribute $a_i$ (which is used as input for machine learning algorithms) using all attributes of neighbors to predict attributes values for $a_i$. We perform extensive experimentation on ten real-world datasets and show that the proposed feature map significantly improves the prediction accuracy as compared to baseline approaches on these datasets.