 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Understandability: Why are we streaming movies with subtitles?
Mar 22, 2024



Watching movies and TV shows with subtitles enabled is not simply down to audibility or speech intelligibility. A variety of evolving factors related to technological advances, cinema production and social behaviour challenge our perception and understanding. This study seeks to formalise and give context to these influential factors under a wider and novel term referred to as Dialogue Understandability. We propose a working definition for Dialogue Understandability being a listener's capacity to follow the story without undue cognitive effort or concentration being required that impacts their Quality of Experience (QoE). The paper identifies, describes and categorises the factors that influence Dialogue Understandability mapping them over the QoE framework, a media streaming lifecycle, and the stakeholders involved. We then explore available measurement tools in the literature and link them to the factors they could potentially be used for. The maturity and suitability of these tools is evaluated over a set of pilot experiments. Finally, we reflect on the gaps that still need to be filled, what we can measure and what not, future subjective experiments, and new research trends that could help us to fully characterise Dialogue Understandability.
Reduce, Reuse, Recycle: Is Perturbed Data better than Other Language augmentation for Low Resource Self-Supervised Speech Models
Sep 22, 2023



Self-supervised representation learning (SSRL) has improved the performance on downstream phoneme recognition versus supervised models. Training SSRL models requires a large amount of pre-training data and this poses a challenge for low resource languages. A common approach is transferring knowledge from other languages. Instead, we propose to use audio augmentation to pre-train SSRL models in a low resource condition and evaluate phoneme recognition as downstream task. We performed a systematic comparison of augmentation techniques, namely: pitch variation, noise addition, accented target-language speech and other language speech. We found combined augmentations (noise/pitch) was the best augmentation strategy outperforming accent and language knowledge transfer. We compared the performance with various quantities and types of pre-training data. We examined the scaling factor of augmented data to achieve equivalent performance to models pre-trained with target domain speech. Our findings suggest that for resource constrained languages, in-domain synthetic augmentation can outperform knowledge transfer from accented or other language speech.
Unsupervised Automatic Speech Recognition: A Review
Jun 09, 2021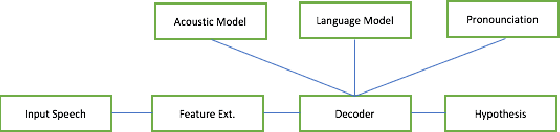



Automatic Speech Recognition (ASR) systems can be trained to achieve remarkable performance given large amounts of manually transcribed speech, but large labeled data sets can be difficult or expensive to acquire for all languages of interest. In this paper, we review the research literature to identify models and ideas that could lead to fully unsupervised ASR, including unsupervised segmentation of the speech signal, unsupervised mapping from speech segments to text, and semi-supervised models with nominal amounts of labeled examples. The objective of the study is to identify the limitations of what can be learned from speech data alone and to understand the minimum requirements for speech recognition. Identifying these limitations would help optimize the resources and efforts in ASR development for low-resource languages.
Code Switching Language Model Using Monolingual Training Data
Dec 24, 2020

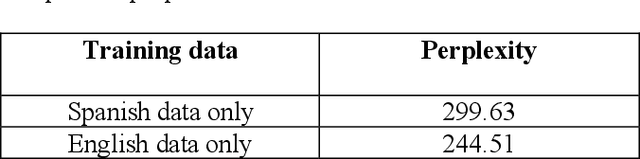
Training a code-switching (CS) language model using only monolingual data is still an ongoing research problem. In this paper, a CS language model is trained using only monolingual training data. As recurrent neural network (RNN) models are best suited for predicting sequential data. In this work, an RNN language model is trained using alternate batches from only monolingual English and Spanish data and the perplexity of the language model is computed. From the results, it is concluded that using alternate batches of monolingual data in training reduced the perplexity of a CS language model. The results were consistently improved using mean square error (MSE) in the output embeddings of RNN based language model. By combining both methods, perplexity is reduced from 299.63 to 80.38. The proposed methods were comparable to the language model fine tune with code-switch training data.
Effect of Analysis Window and Feature Selection on Classification of Hand Movements Using EMG Signal
Feb 13, 2020
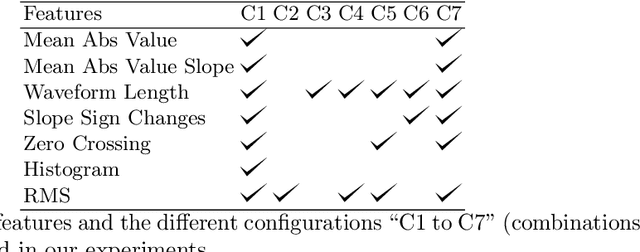


Electromyography (EMG) signals have been successfully employed for driving prosthetic limbs of a single or double degree of freedom. This principle works by using the amplitude of the EMG signals to decide between one or two simpler movements. This method underperforms as compare to the contemporary advances done at the mechanical, electronics, and robotics end, and it lacks intuition. Recently, research on myoelectric control based on pattern recognition (PR) shows promising results with the aid of machine learning classifiers. Using the approach termed as, EMG-PR, EMG signals are divided into analysis windows, and features are extracted for each window. These features are then fed to the machine learning classifiers as input. By offering multiple class movements and intuitive control, this method has the potential to power an amputated subject to perform everyday life movements. In this paper, we investigate the effect of the analysis window and feature selection on classification accuracy of different hand and wrist movements using time-domain features. We show that effective data preprocessing and optimum feature selection helps to improve the classification accuracy of hand movements. We use publicly available hand and wrist gesture dataset of $40$ intact subjects for experimentation. Results computed using different classification algorithms show that the proposed preprocessing and features selection outperforms the baseline and achieve up to $98\%$ classification accuracy.
Rethinking the Artificial Neural Networks: A Mesh of Subnets with a Central Mechanism for Storing and Predicting the Data
Jan 05, 2019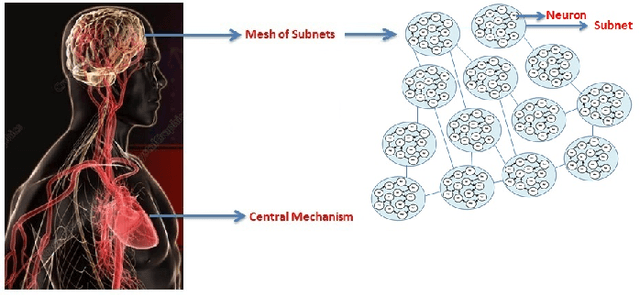
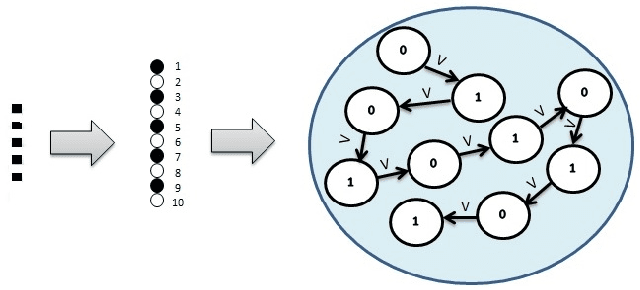
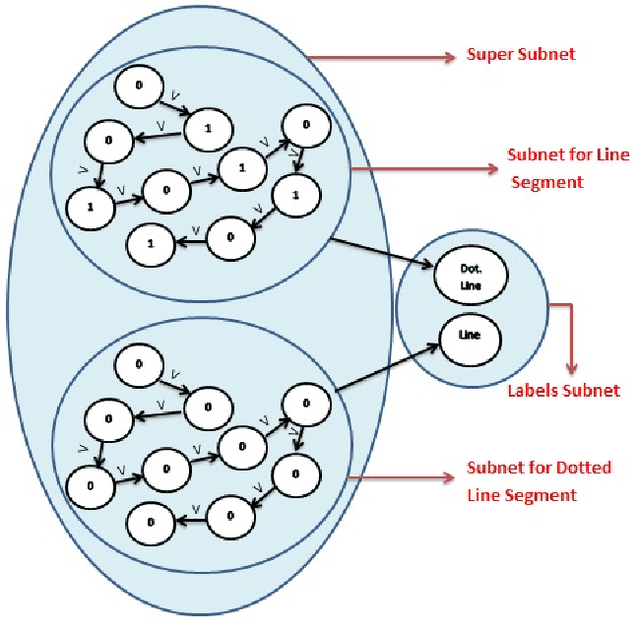
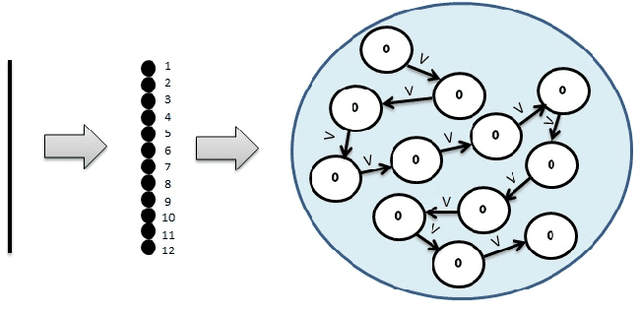
The Artificial Neural Networks (ANNs) have been originally designed to function like a biological neural network, but does an ANN really work in the same way as a biological neural network? As we know, the human brain holds information in its memory cells, so if the ANNs use the same model as our brains, they should store datasets in a similar manner. The most popular type of ANN architecture is based on a layered structure of neurons, whereas a human brain has trillions of complex interconnections of neurons continuously establishing new connections, updating existing ones, and removing the irrelevant connections across different parts of the brain. In this paper, we propose a novel approach to building ANNs which are truly inspired by the biological network containing a mesh of subnets controlled by a central mechanism. A subnet is a network of neurons that hold the dataset values. We attempt to address the following fundamental questions: (1) What is the architecture of the ANN model? Whether the layered architecture is the most appropriate choice? (2) Whether a neuron is a process or a memory cell? (3) What is the best way of interconnecting neurons and what weight-assignment mechanism should be used? (4) How to incorporate prior knowledge, bias, and generalizations for features extraction and prediction? Our proposed ANN architecture leverages the accuracy on textual data and our experimental findings confirm the effectiveness of our model. We also collaborate with the construction of the ANN model for storing and processing the images.