 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Switching Language Model Using Monolingual Training Data
Dec 24, 2020

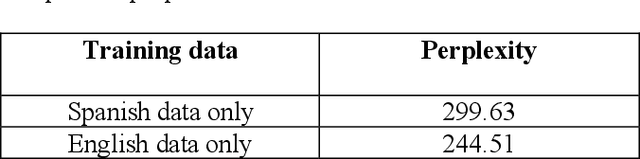
Training a code-switching (CS) language model using only monolingual data is still an ongoing research problem. In this paper, a CS language model is trained using only monolingual training data. As recurrent neural network (RNN) models are best suited for predicting sequential data. In this work, an RNN language model is trained using alternate batches from only monolingual English and Spanish data and the perplexity of the language model is computed. From the results, it is concluded that using alternate batches of monolingual data in training reduced the perplexity of a CS language model. The results were consistently improved using mean square error (MSE) in the output embeddings of RNN based language model. By combining both methods, perplexity is reduced from 299.63 to 80.38. The proposed methods were comparable to the language model fine tune with code-switch training data.