 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Data Analytics on Augmented Similarity Triplets
Dec 27, 2019

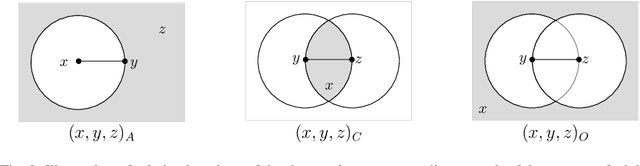
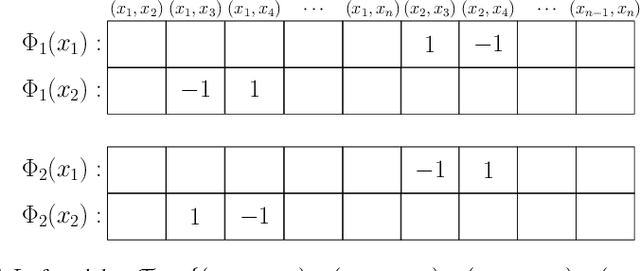
Many machine learning methods (classification, clustering, etc.) start with a known kernel that provides similarity or distance measure between two objects. Recent work has extended this to situations where the information about objects is limited to comparisons of distances between three objects (triplets). Humans find the comparison task much easier than the estimation of absolute similarities, so this kind of data can be easily obtained using crowd-sourcing. In this work, we give an efficient method of augmenting the triplets data, by utilizing additional implicit information inferred from the existing data. Triplets augmentation improves the quality of kernel-based and kernel-free data analytics tasks. Secondly, we also propose a novel set of algorithms for common supervised and unsupervised machine learning tasks based on triplets. These methods work directly with triplets, avoiding kernel evaluations. Experimental evaluation on real and synthetic datasets shows that our methods are more accurate than the current best-known techniques.