 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairUDT: Fairness-aware Uplift Decision Trees
Feb 03, 2025Training data used for developing machine learning classifiers can exhibit biases against specific protected attributes. Such biases typically originate from historical discrimination or certain underlying patterns that disproportionately under-represent minority groups, such as those identified by their gender, religion, or race. In this paper, we propose a novel approach, FairUDT, a fairness-aware Uplift-based Decision Tree for discrimination identification. FairUDT demonstrates how the integration of uplift modeling with decision trees can be adapted to include fair splitting criteria. Additionally, we introduce a modified leaf relabeling approach for removing discrimination. We divide our dataset into favored and deprived groups based on a binary sensitive attribute, with the favored dataset serving as the treatment group and the deprived dataset as the control group. By applying FairUDT and our leaf relabeling approach to preprocess three benchmark datasets, we achieve an acceptable accuracy-discrimination tradeoff. We also show that FairUDT is inherently interpretable and can be utilized in discrimination detection tasks. The code for this project is available https://github.com/ara-25/FairUDT
* Published in Knowledge-based Systems (2025)
A Clustering Framework for Lexical Normalization of Roman Urdu
Mar 31, 2020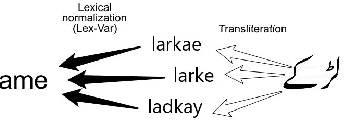
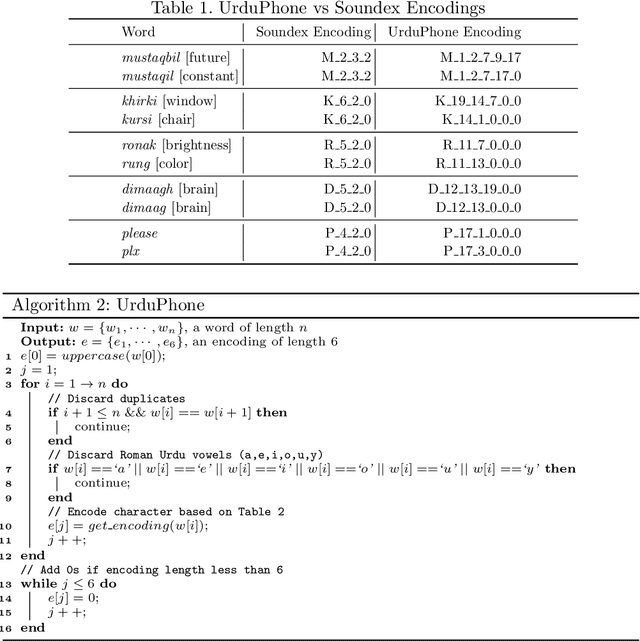
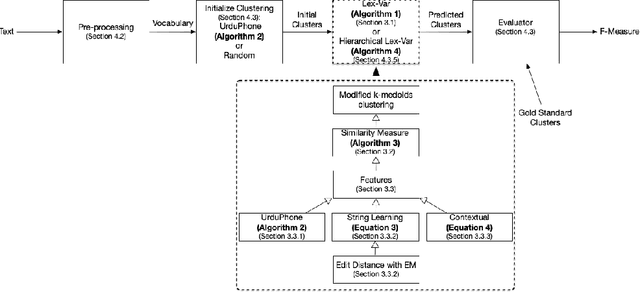

Roman Urdu is an informal form of the Urdu language written in Roman script, which is widely used in South Asia for online textual content. It lacks standard spelling and hence poses several normalization challenges during automatic language processing. In this article, we present a feature-based clustering framework for the lexical normalization of Roman Urdu corpora, which includes a phonetic algorithm UrduPhone, a string matching component, a feature-based similarity function, and a clustering algorithm Lex-Var. UrduPhone encodes Roman Urdu strings to their pronunciation-based representations. The string matching component handles character-level variations that occur when writing Urdu using Roman script.
Adapting Deep Learning for Sentiment Classification of Code-Switched Informal Short Text
Jan 04, 2020
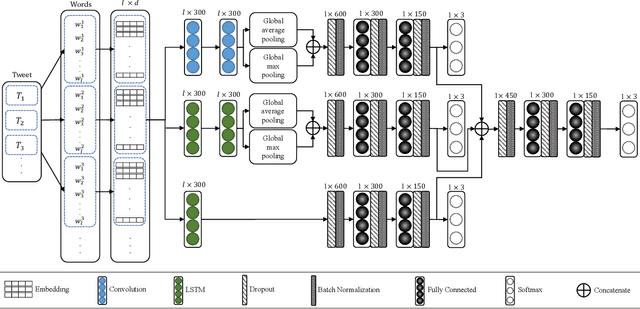
Nowadays, an abundance of short text is being generated that uses nonstandard writing styles influenced by regional languages. Such informal and code-switched content are under-resourced in terms of labeled datasets and language models even for popular tasks like sentiment classification. In this work, we (1) present a labeled dataset called MultiSenti for sentiment classification of code-switched informal short text, (2) explore the feasibility of adapting resources from a resource-rich language for an informal one, and (3) propose a deep learning-based model for sentiment classification of code-switched informal short text. We aim to achieve this without any lexical normalization, language translation, or code-switching indication. The performance of the proposed models is compared with three existing multilingual sentiment classification models. The results show that the proposed model performs better in general and adapting character-based embeddings yield equivalent performance while being computationally more efficient than training word-based domain-specific embeddings.
A Multi-cascaded Model with Data Augmentation for Enhanced Paraphrase Detection in Short Texts
Dec 27, 2019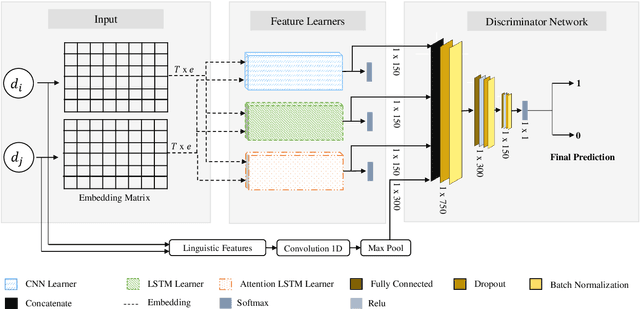
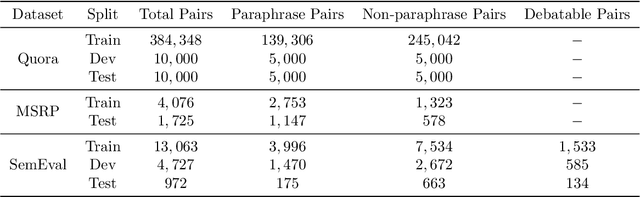
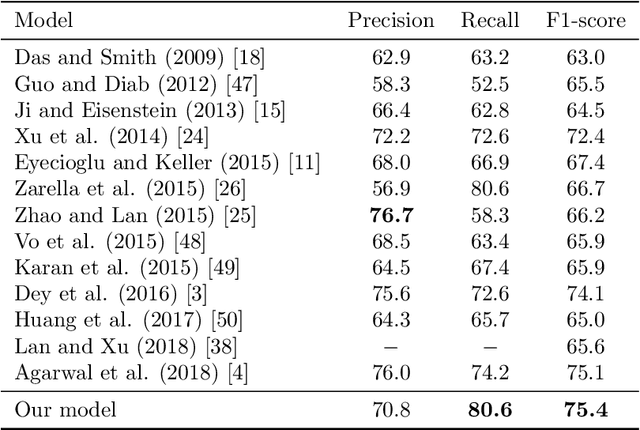
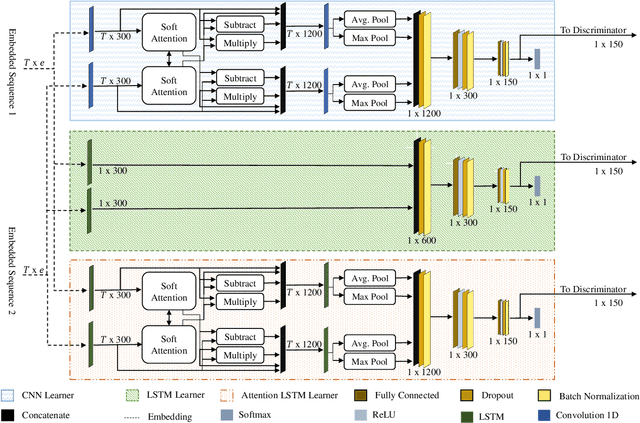
Paraphrase detection is an important task in text analytics with numerous applications such as plagiarism detection, duplicate question identification, and enhanced customer support helpdesks. Deep models have been proposed for representing and classifying paraphrases. These models, however, require large quantities of human-labeled data, which is expensive to obtain. In this work, we present a data augmentation strategy and a multi-cascaded model for improved paraphrase detection in short texts. Our data augmentation strategy considers the notions of paraphrases and non-paraphrases as binary relations over the set of texts. Subsequently, it uses graph theoretic concepts to efficiently generate additional paraphrase and non-paraphrase pairs in a sound manner. Our multi-cascaded model employs three supervised feature learners (cascades) based on CNN and LSTM networks with and without soft-attention. The learned features, together with hand-crafted linguistic features, are then forwarded to a discriminator network for final classification. Our model is both wide and deep and provides greater robustness across clean and noisy short texts. We evaluate our approach on three benchmark datasets and show that it produces a comparable or state-of-the-art performance on all three.
Efficient Data Analytics on Augmented Similarity Triplets
Dec 27, 2019

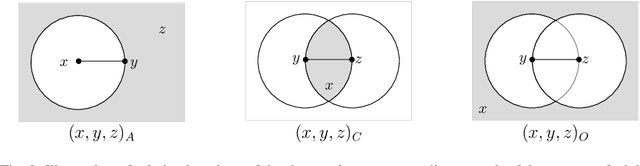
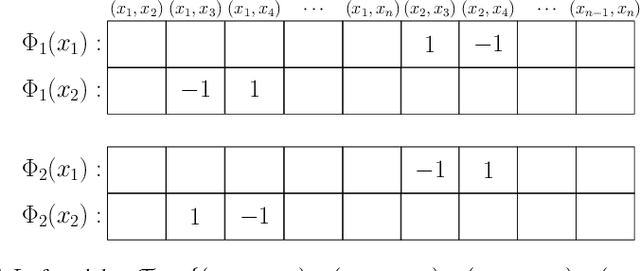
Many machine learning methods (classification, clustering, etc.) start with a known kernel that provides similarity or distance measure between two objects. Recent work has extended this to situations where the information about objects is limited to comparisons of distances between three objects (triplets). Humans find the comparison task much easier than the estimation of absolute similarities, so this kind of data can be easily obtained using crowd-sourcing. In this work, we give an efficient method of augmenting the triplets data, by utilizing additional implicit information inferred from the existing data. Triplets augmentation improves the quality of kernel-based and kernel-free data analytics tasks. Secondly, we also propose a novel set of algorithms for common supervised and unsupervised machine learning tasks based on triplets. These methods work directly with triplets, avoiding kernel evaluations. Experimental evaluation on real and synthetic datasets shows that our methods are more accurate than the current best-known techniques.
A Multi-cascaded Deep Model for Bilingual SMS Classification
Nov 29, 2019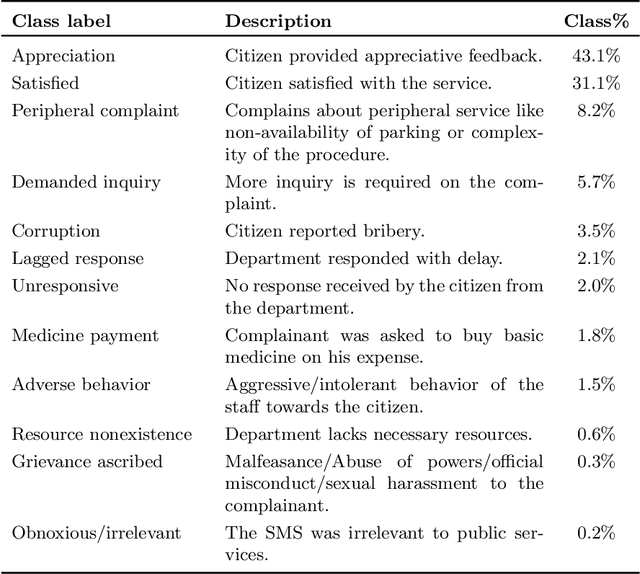
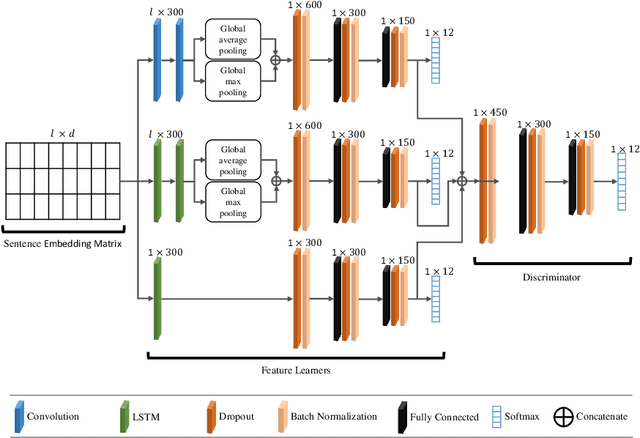

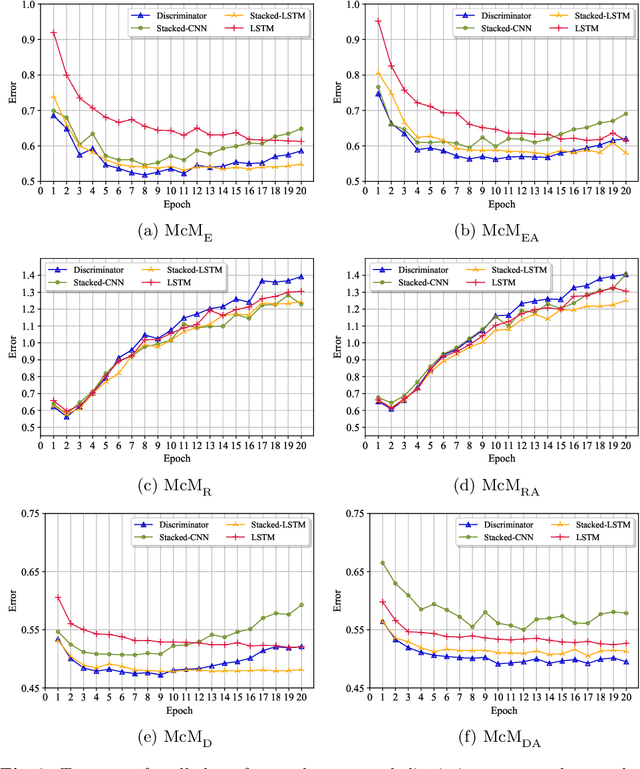
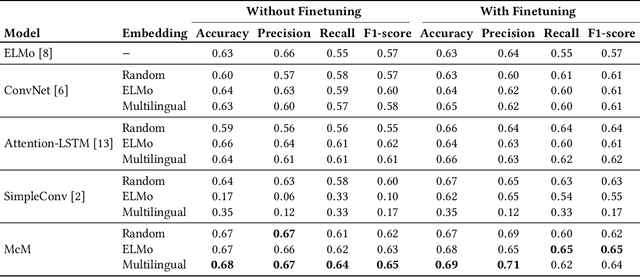
Most studies on text classification are focused on the English language. However, short texts such as SMS are influenced by regional languages. This makes the automatic text classification task challenging due to the multilingual, informal, and noisy nature of language in the text. In this work, we propose a novel multi-cascaded deep learning model called McM for bilingual SMS classification. McM exploits $n$-gram level information as well as long-term dependencies of text for learning. Our approach aims to learn a model without any code-switching indication, lexical normalization, language translation, or language transliteration. The model relies entirely upon the text as no external knowledge base is utilized for learning. For this purpose, a 12 class bilingual text dataset is developed from SMS feedbacks of citizens on public services containing mixed Roman Urdu and English languages. Our model achieves high accuracy for classification on this dataset and outperforms the previous model for multilingual text classification, highlighting language independence of McM.
Improving Text Normalization by Optimizing Nearest Neighbor Matching
Dec 27, 2017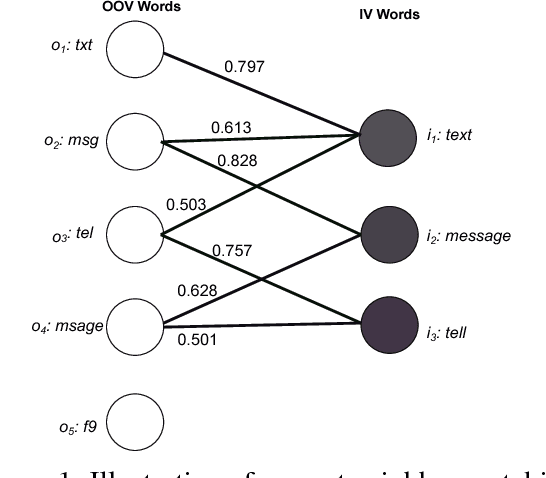
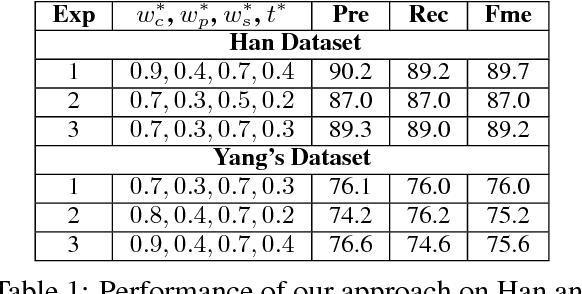
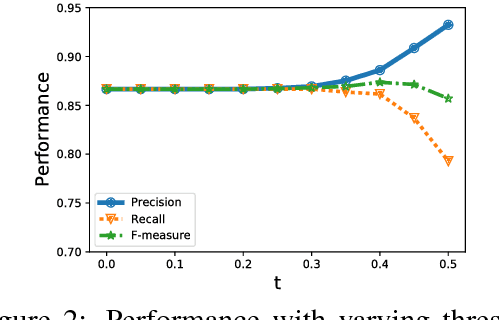
Text normalization is an essential task in the processing and analysis of social media that is dominated with informal writing. It aims to map informal words to their intended standard forms. Previously proposed text normalization approaches typically require manual selection of parameters for improved performance. In this paper, we present an automatic optimizationbased nearest neighbor matching approach for text normalization. This approach is motivated by the observation that text normalization is essentially a matching problem and nearest neighbor matching with an adaptive similarity function is the most direct procedure for it. Our similarity function incorporates weighted contributions of contextual, string, and phonetic similarity, and the nearest neighbor matching involves a minimum similarity threshold. These four parameters are tuned efficiently using grid search. We evaluate the performance of our approach on two benchmark datasets. The results demonstrate that parameter tuning on small sized labeled datasets produce state-of-the-art text normalization performances. Thus, this approach allows practically easy construction of evolving domain-specific normalization lexicons