 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptX: A Framework for Latent Concept Analysis
Nov 12, 2022

The opacity of deep neural networks remains a challenge in deploying solutions where explanation is as important as precision. We present ConceptX, a human-in-the-loop framework for interpreting and annotating latent representational space in pre-trained Language Models (pLMs). We use an unsupervised method to discover concepts learned in these models and enable a graphical interface for humans to generate explanations for the concepts. To facilitate the process, we provide auto-annotations of the concepts (based on traditional linguistic ontologies). Such annotations enable development of a linguistic resource that directly represents latent concepts learned within deep NLP models. These include not just traditional linguistic concepts, but also task-specific or sensitive concepts (words grouped based on gender or religious connotation) that helps the annotators to mark bias in the model. The framework consists of two parts (i) concept discovery and (ii) annotation platform.
Analyzing Encoded Concepts in Transformer Language Models
Jun 27, 2022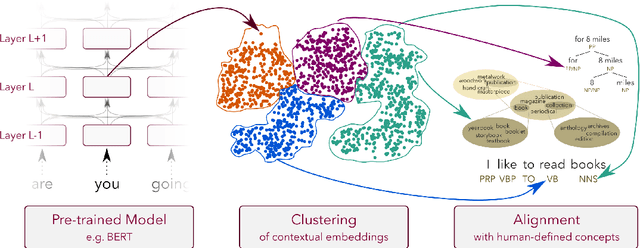

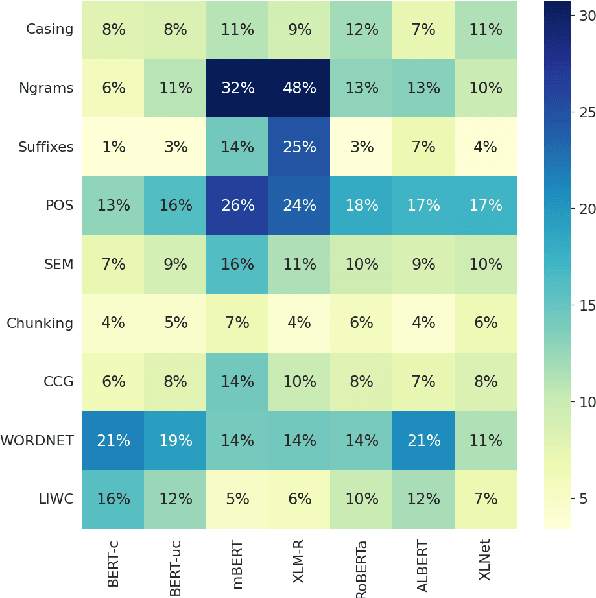

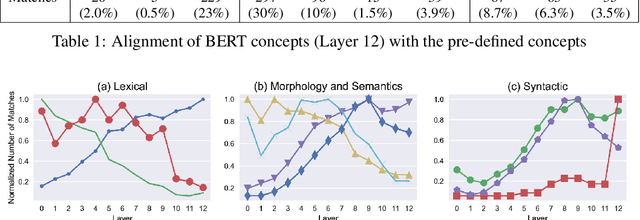
We propose a novel framework ConceptX, to analyze how latent concepts are encoded in representations learned within pre-trained language models. It uses clustering to discover the encoded concepts and explains them by aligning with a large set of human-defined concepts. Our analysis on seven transformer language models reveal interesting insights: i) the latent space within the learned representations overlap with different linguistic concepts to a varying degree, ii) the lower layers in the model are dominated by lexical concepts (e.g., affixation), whereas the core-linguistic concepts (e.g., morphological or syntactic relations) are better represented in the middle and higher layers, iii) some encoded concepts are multi-faceted and cannot be adequately explained using the existing human-defined concepts.
* 20 pages, 10 figures
Discovering Latent Concepts Learned in BERT
May 15, 2022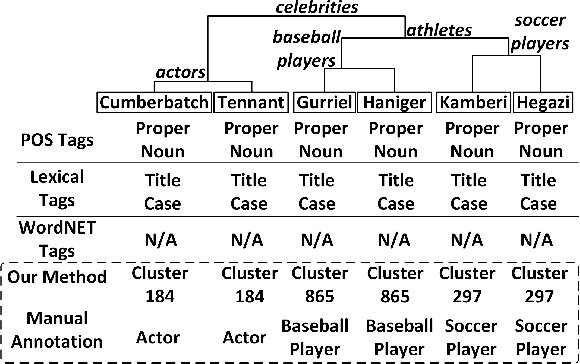

A large number of studies that analyze deep neural network models and their ability to encode various linguistic and non-linguistic concepts provide an interpretation of the inner mechanics of these models. The scope of the analyses is limited to pre-defined concepts that reinforce the traditional linguistic knowledge and do not reflect on how novel concepts are learned by the model. We address this limitation by discovering and analyzing latent concepts learned in neural network models in an unsupervised fashion and provide interpretations from the model's perspective. In this work, we study: i) what latent concepts exist in the pre-trained BERT model, ii) how the discovered latent concepts align or diverge from classical linguistic hierarchy and iii) how the latent concepts evolve across layers. Our findings show: i) a model learns novel concepts (e.g. animal categories and demographic groups), which do not strictly adhere to any pre-defined categorization (e.g. POS, semantic tags), ii) several latent concepts are based on multiple properties which may include semantics, syntax, and morphology, iii) the lower layers in the model dominate in learning shallow lexical concepts while the higher layers learn semantic relations and iv) the discovered latent concepts highlight potential biases learned in the model. We also release a novel BERT ConceptNet dataset (BCN) consisting of 174 concept labels and 1M annotated instances.
Interpreting Criminal Charge Prediction and Its Algorithmic Bias via Quantum-Inspired Complex Valued Networks
Jul 14, 2021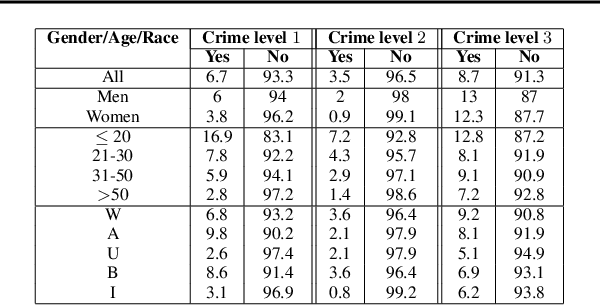
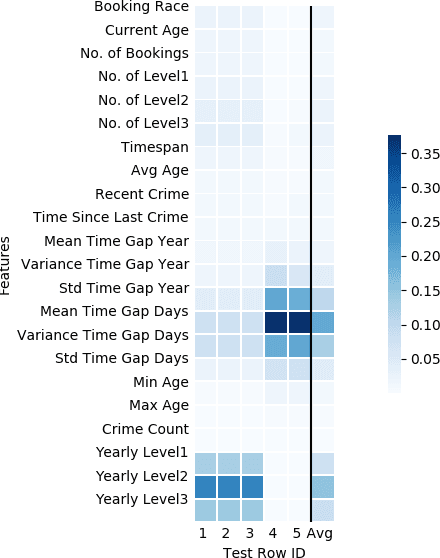
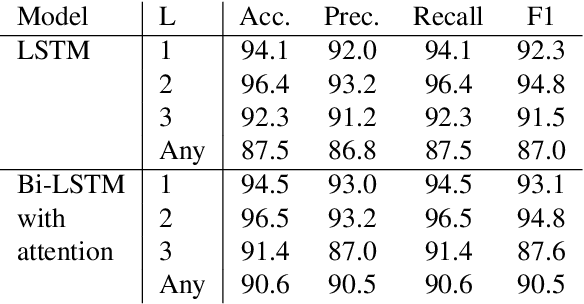
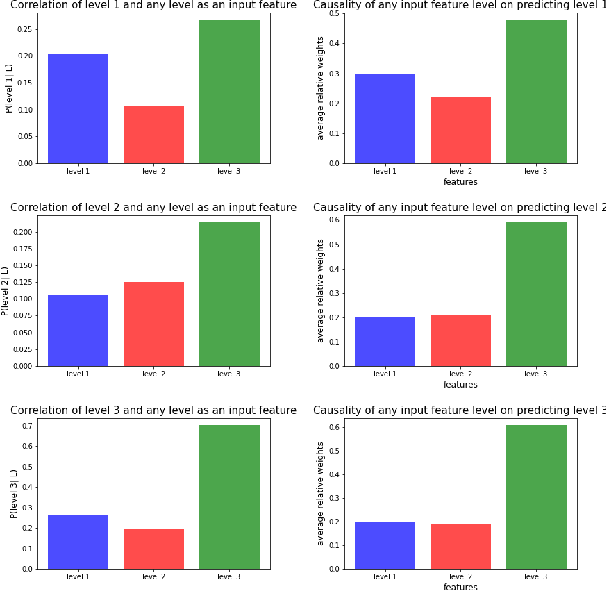
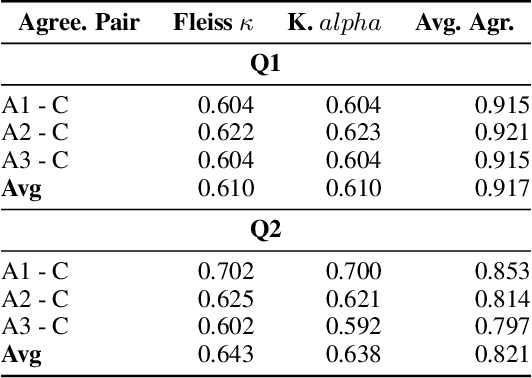
While predictive policing has become increasingly common in assisting with decisions in the criminal justice system, the use of these results is still controversial. Some software based on deep learning lacks accuracy (e.g., in F-1), and importantly many decision processes are not transparent, causing doubt about decision bias, such as perceived racial and age disparities. This paper addresses bias issues with post-hoc explanations to provide a trustable prediction of whether a person will receive future criminal charges given one's previous criminal records by learning temporal behavior patterns over twenty years. Bi-LSTM relieves the vanishing gradient problem, attentional mechanisms allow learning and interpretation of feature importance, and complex-valued networks inspired quantum physics to facilitate a certain level of transparency in modeling the decision process. Our approach shows a consistent and reliable prediction precision and recall on a real-life dataset. Our analysis of the importance of each input feature shows the critical causal impact on decision-making, suggesting that criminal histories are statistically significant factors, while identifiers, such as race and age, are not. Finally, our algorithm indicates that a suspect tends to rather than suddenly increase crime severity level over time gradually.
A Clustering Framework for Lexical Normalization of Roman Urdu
Mar 31, 2020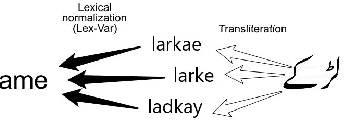
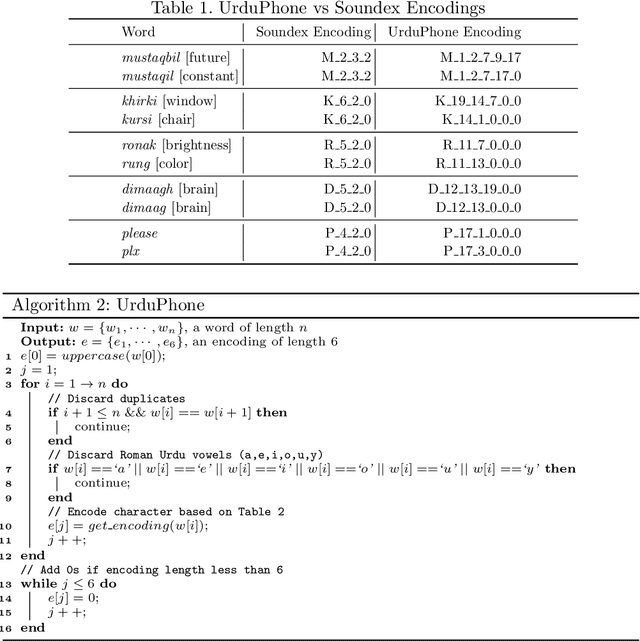
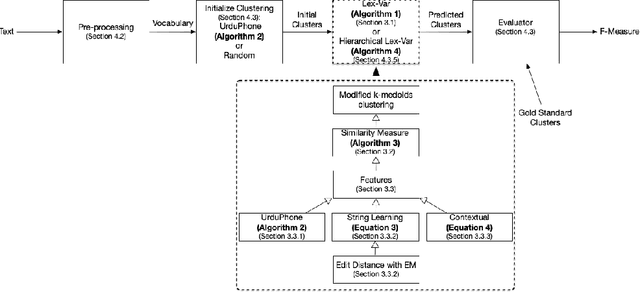

Roman Urdu is an informal form of the Urdu language written in Roman script, which is widely used in South Asia for online textual content. It lacks standard spelling and hence poses several normalization challenges during automatic language processing. In this article, we present a feature-based clustering framework for the lexical normalization of Roman Urdu corpora, which includes a phonetic algorithm UrduPhone, a string matching component, a feature-based similarity function, and a clustering algorithm Lex-Var. UrduPhone encodes Roman Urdu strings to their pronunciation-based representations. The string matching component handles character-level variations that occur when writing Urdu using Roman script.
Diversity by Phonetics and its Application in Neural Machine Translation
Nov 11, 2019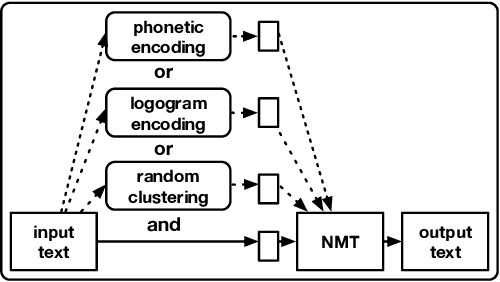

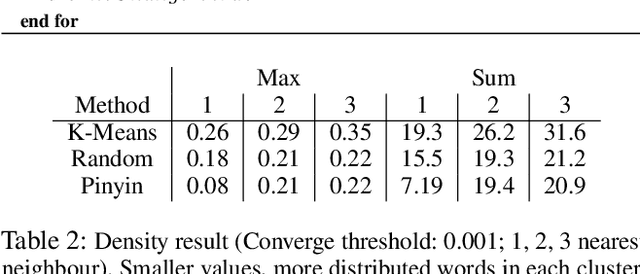
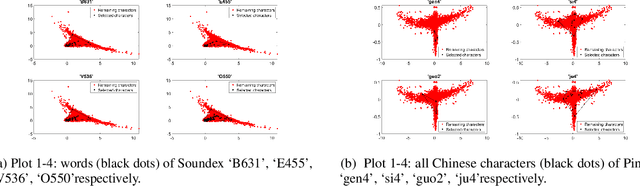
We introduce a powerful approach for Neural Machine Translation (NMT), whereby, during training and testing, together with the input we provide its phonetic encoding and the variants of such an encoding. This way we obtain very significant improvements up to 4 BLEU points over the state-of-the-art large-scale system. The phonetic encoding is the first part of our contribution, with a second being a theory that aims to understand the reason for this improvement. Our hypothesis states that the phonetic encoding helps NMT because it encodes a procedure to emphasize the difference between semantically diverse sentences. We conduct an empirical geometric validation of our hypothesis in support of which we obtain overwhelming evidence. Subsequently, as our third contribution and based on our theory, we develop artificial mechanisms that leverage during learning the hypothesized (and verified) effect phonetics. We achieve significant and consistent improvements overall language pairs and datasets: French-English, German-English, and Chinese-English in medium task IWSLT'17 and French-English in large task WMT'18 Bio, with up to 4 BLEU points over the state-of-the-art. Moreover, our approaches are more robust than baselines when evaluated on unknown out-of-domain test sets with up to a 5 BLEU point increase.