 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity by Phonetics and its Application in Neural Machine Translation
Paper and Code
Nov 11, 2019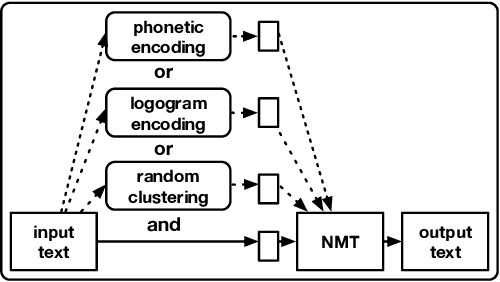

We introduce a powerful approach for Neural Machine Translation (NMT), whereby, during training and testing, together with the input we provide its phonetic encoding and the variants of such an encoding. This way we obtain very significant improvements up to 4 BLEU points over the state-of-the-art large-scale system. The phonetic encoding is the first part of our contribution, with a second being a theory that aims to understand the reason for this improvement. Our hypothesis states that the phonetic encoding helps NMT because it encodes a procedure to emphasize the difference between semantically diverse sentences. We conduct an empirical geometric validation of our hypothesis in support of which we obtain overwhelming evidence. Subsequently, as our third contribution and based on our theory, we develop artificial mechanisms that leverage during learning the hypothesized (and verified) effect phonetics. We achieve significant and consistent improvements overall language pairs and datasets: French-English, German-English, and Chinese-English in medium task IWSLT'17 and French-English in large task WMT'18 Bio, with up to 4 BLEU points over the state-of-the-art. Moreover, our approaches are more robust than baselines when evaluated on unknown out-of-domain test sets with up to a 5 BLEU point increase.