 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairUDT: Fairness-aware Uplift Decision Trees
Feb 03, 2025Training data used for developing machine learning classifiers can exhibit biases against specific protected attributes. Such biases typically originate from historical discrimination or certain underlying patterns that disproportionately under-represent minority groups, such as those identified by their gender, religion, or race. In this paper, we propose a novel approach, FairUDT, a fairness-aware Uplift-based Decision Tree for discrimination identification. FairUDT demonstrates how the integration of uplift modeling with decision trees can be adapted to include fair splitting criteria. Additionally, we introduce a modified leaf relabeling approach for removing discrimination. We divide our dataset into favored and deprived groups based on a binary sensitive attribute, with the favored dataset serving as the treatment group and the deprived dataset as the control group. By applying FairUDT and our leaf relabeling approach to preprocess three benchmark datasets, we achieve an acceptable accuracy-discrimination tradeoff. We also show that FairUDT is inherently interpretable and can be utilized in discrimination detection tasks. The code for this project is available https://github.com/ara-25/FairUDT
* Published in Knowledge-based Systems (2025)
A Clustering Framework for Lexical Normalization of Roman Urdu
Mar 31, 2020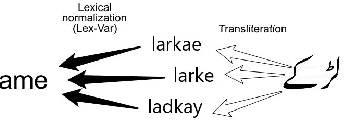
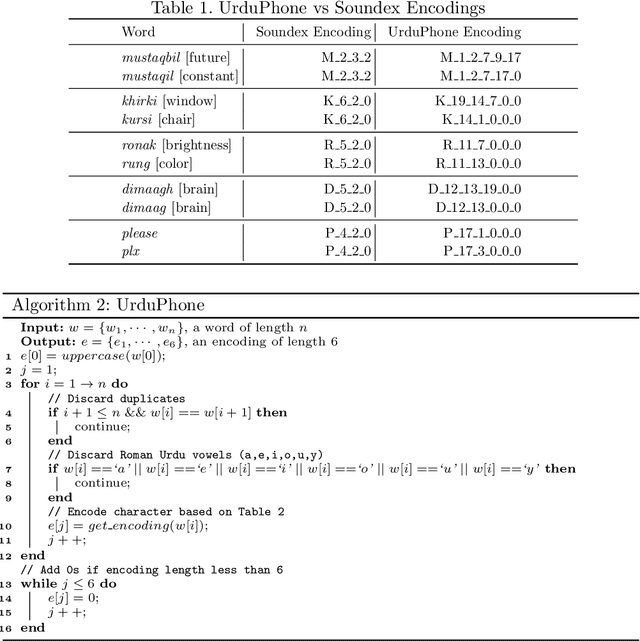
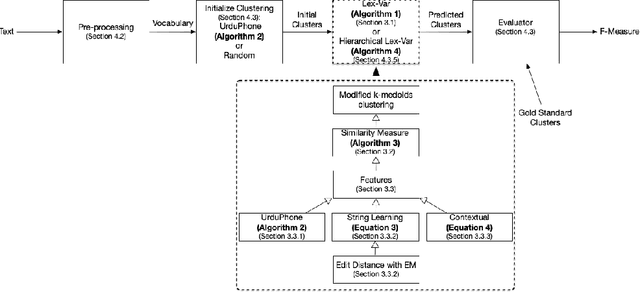

Roman Urdu is an informal form of the Urdu language written in Roman script, which is widely used in South Asia for online textual content. It lacks standard spelling and hence poses several normalization challenges during automatic language processing. In this article, we present a feature-based clustering framework for the lexical normalization of Roman Urdu corpora, which includes a phonetic algorithm UrduPhone, a string matching component, a feature-based similarity function, and a clustering algorithm Lex-Var. UrduPhone encodes Roman Urdu strings to their pronunciation-based representations. The string matching component handles character-level variations that occur when writing Urdu using Roman script.