 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Text Normalization by Optimizing Nearest Neighbor Matching
Paper and Code
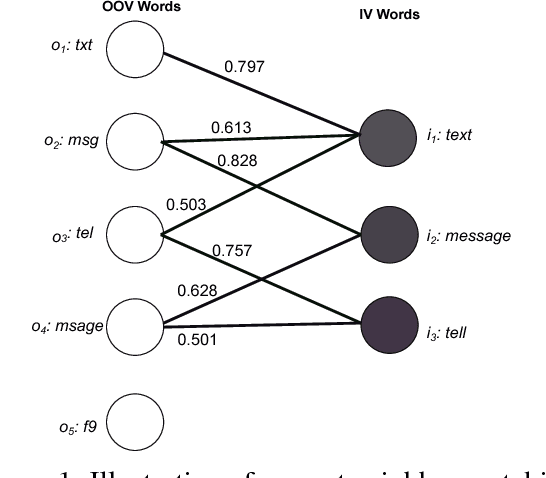
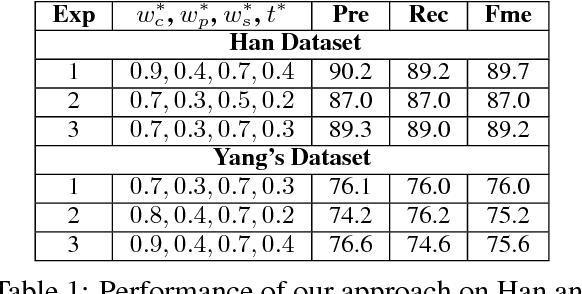
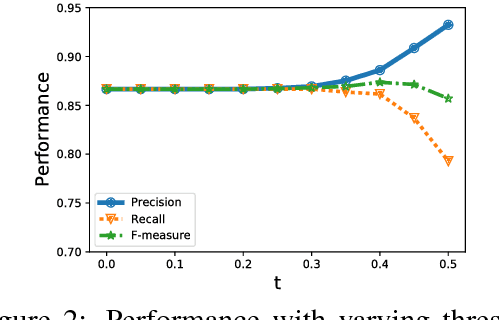
Text normalization is an essential task in the processing and analysis of social media that is dominated with informal writing. It aims to map informal words to their intended standard forms. Previously proposed text normalization approaches typically require manual selection of parameters for improved performance. In this paper, we present an automatic optimizationbased nearest neighbor matching approach for text normalization. This approach is motivated by the observation that text normalization is essentially a matching problem and nearest neighbor matching with an adaptive similarity function is the most direct procedure for it. Our similarity function incorporates weighted contributions of contextual, string, and phonetic similarity, and the nearest neighbor matching involves a minimum similarity threshold. These four parameters are tuned efficiently using grid search. We evaluate the performance of our approach on two benchmark datasets. The results demonstrate that parameter tuning on small sized labeled datasets produce state-of-the-art text normalization performances. Thus, this approach allows practically easy construction of evolving domain-specific normalization lexicons