 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Backbones: Sparsifying Graphs through Zero Forcing for Effective Graph-Based Learning
Feb 24, 2025This paper introduces a novel framework for graph sparsification that preserves the essential learning attributes of original graphs, improving computational efficiency and reducing complexity in learning algorithms. We refer to these sparse graphs as "learning backbones". Our approach leverages the zero-forcing (ZF) phenomenon, a dynamic process on graphs with applications in network control. The key idea is to generate a tree from the original graph that retains critical dynamical properties. By correlating these properties with learning attributes, we construct effective learning backbones. We evaluate the performance of our ZF-based backbones in graph classification tasks across eight datasets and six baseline models. The results demonstrate that our method outperforms existing techniques. Additionally, we explore extensions using node distance metrics to further enhance the framework's utility.
Improving Graph Machine Learning Performance Through Feature Augmentation Based on Network Control Theory
May 03, 2024Network control theory (NCT) offers a robust analytical framework for understanding the influence of network topology on dynamic behaviors, enabling researchers to decipher how certain patterns of external control measures can steer system dynamics towards desired states. Distinguished from other structure-function methodologies, NCT's predictive capabilities can be coupled with deploying Graph Neural Networks (GNNs), which have demonstrated exceptional utility in various network-based learning tasks. However, the performance of GNNs heavily relies on the expressiveness of node features, and the lack of node features can greatly degrade their performance. Furthermore, many real-world systems may lack node-level information, posing a challenge for GNNs.To tackle this challenge, we introduce a novel approach, NCT-based Enhanced Feature Augmentation (NCT-EFA), that assimilates average controllability, along with other centrality indices, into the feature augmentation pipeline to enhance GNNs performance. Our evaluation of NCT-EFA, on six benchmark GNN models across two experimental setting. solely employing average controllability and in combination with additional centrality metrics. showcases an improved performance reaching as high as 11%. Our results demonstrate that incorporating NCT into feature enrichment can substantively extend the applicability and heighten the performance of GNNs in scenarios where node-level information is unavailable.
Control-based Graph Embeddings with Data Augmentation for Contrastive Learning
Mar 07, 2024In this paper, we study the problem of unsupervised graph representation learning by harnessing the control properties of dynamical networks defined on graphs. Our approach introduces a novel framework for contrastive learning, a widely prevalent technique for unsupervised representation learning. A crucial step in contrastive learning is the creation of 'augmented' graphs from the input graphs. Though different from the original graphs, these augmented graphs retain the original graph's structural characteristics. Here, we propose a unique method for generating these augmented graphs by leveraging the control properties of networks. The core concept revolves around perturbing the original graph to create a new one while preserving the controllability properties specific to networks and graphs. Compared to the existing methods, we demonstrate that this innovative approach enhances the effectiveness of contrastive learning frameworks, leading to superior results regarding the accuracy of the classification tasks. The key innovation lies in our ability to decode the network structure using these control properties, opening new avenues for unsupervised graph representation learning.
Enhanced Graph Neural Networks with Ego-Centric Spectral Subgraph Embeddings Augmentation
Oct 10, 2023



Graph Neural Networks (GNNs) have shown remarkable merit in performing various learning-based tasks in complex networks. The superior performance of GNNs often correlates with the availability and quality of node-level features in the input networks. However, for many network applications, such node-level information may be missing or unreliable, thereby limiting the applicability and efficacy of GNNs. To address this limitation, we present a novel approach denoted as Ego-centric Spectral subGraph Embedding Augmentation (ESGEA), which aims to enhance and design node features, particularly in scenarios where information is lacking. Our method leverages the topological structure of the local subgraph to create topology-aware node features. The subgraph features are generated using an efficient spectral graph embedding technique, and they serve as node features that capture the local topological organization of the network. The explicit node features, if present, are then enhanced with the subgraph embeddings in order to improve the overall performance. ESGEA is compatible with any GNN-based architecture and is effective even in the absence of node features. We evaluate the proposed method in a social network graph classification task where node attributes are unavailable, as well as in a node classification task where node features are corrupted or even absent. The evaluation results on seven datasets and eight baseline models indicate up to a 10% improvement in AUC and a 7% improvement in accuracy for graph and node classification tasks, respectively.
Computing Graph Descriptors on Edge Streams
Sep 02, 2021
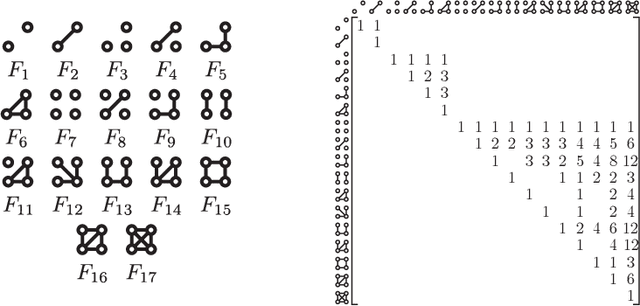

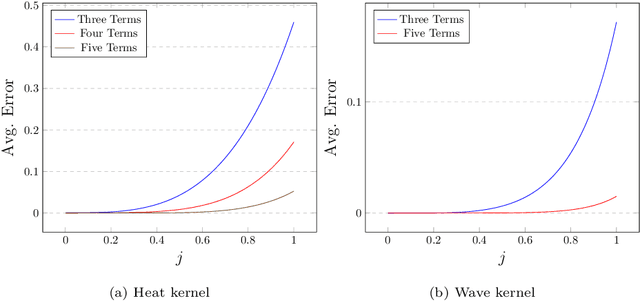
Graph feature extraction is a fundamental task in graphs analytics. Using feature vectors (graph descriptors) in tandem with data mining algorithms that operate on Euclidean data, one can solve problems such as classification, clustering, and anomaly detection on graph-structured data. This idea has proved fruitful in the past, with spectral-based graph descriptors providing state-of-the-art classification accuracy on benchmark datasets. However, these algorithms do not scale to large graphs since: 1) they require storing the entire graph in memory, and 2) the end-user has no control over the algorithm's runtime. In this paper, we present single-pass streaming algorithms to approximate structural features of graphs (counts of subgraphs of order $k \geq 4$). Operating on edge streams allows us to avoid keeping the entire graph in memory, and controlling the sample size enables us to control the time taken by the algorithm. We demonstrate the efficacy of our descriptors by analyzing the approximation error, classification accuracy, and scalability to massive graphs. Our experiments showcase the effect of the sample size on approximation error and predictive accuracy. The proposed descriptors are applicable on graphs with millions of edges within minutes and outperform the state-of-the-art descriptors in classification accuracy.
Byzantine Resilient Distributed Multi-Task Learning
Oct 25, 2020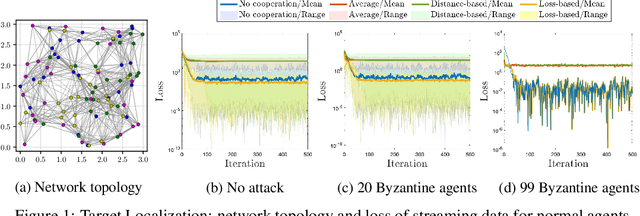
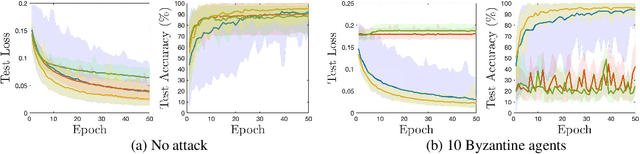
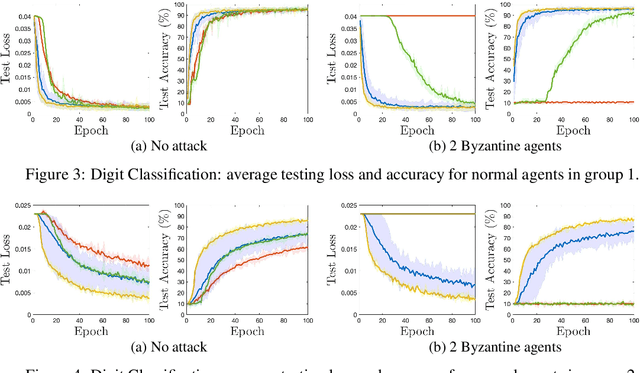
Distributed multi-task learning provides significant advantages in multi-agent networks with heterogeneous data sources where agents aim to learn distinct but correlated models simultaneously. However, distributed algorithms for learning relatedness among tasks are not resilient in the presence of Byzantine agents. In this paper, we present an approach for Byzantine resilient distributed multi-task learning. We propose an efficient online weight assignment rule by measuring the accumulated loss using an agent's data and its neighbors' models. A small accumulated loss indicates a large similarity between the two tasks. In order to ensure the Byzantine resilience of the aggregation at a normal agent, we introduce a step for filtering out larger losses. We analyze the approach for convex models and show that normal agents converge resiliently towards their true targets. Further, an agent's learning performance using the proposed weight assignment rule is guaranteed to be at least as good as in the non-cooperative case as measured by the expected regret. Finally, we demonstrate the approach using three case studies, including regression and classification problems, and show that our method exhibits good empirical performance for non-convex models, such as convolutional neural networks.
Patch-based Generative Adversarial Network Towards Retinal Vessel Segmentation
Dec 22, 2019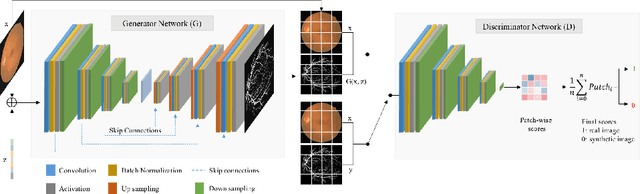
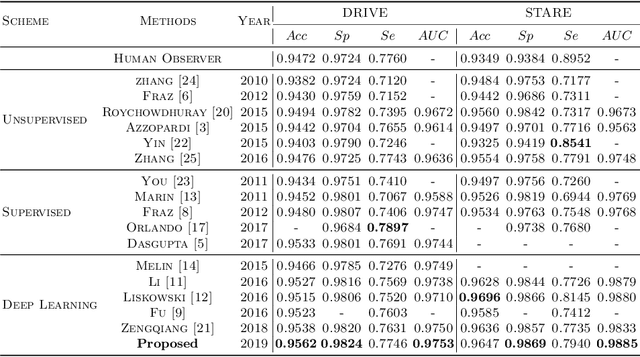
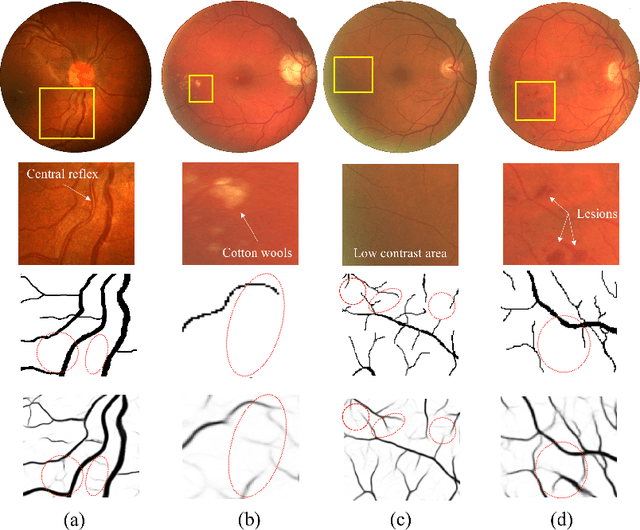
Retinal blood vessels are considered to be the reliable diagnostic biomarkers of ophthalmologic and diabetic retinopathy. Monitoring and diagnosis totally depends on expert analysis of both thin and thick retinal vessels which has recently been carried out by various artificial intelligent techniques. Existing deep learning methods attempt to segment retinal vessels using a unified loss function optimized for both thin and thick vessels with equal importance. Due to variable thickness, biased distribution, and difference in spatial features of thin and thick vessels, unified loss function are more influential towards identification of thick vessels resulting in weak segmentation. To address this problem, a conditional patch-based generative adversarial network is proposed which utilizes a generator network and a patch-based discriminator network conditioned on the sample data with an additional loss function to learn both thin and thick vessels. Experiments are conducted on publicly available STARE and DRIVE datasets which show that the proposed model outperforms the state-of-the-art methods.
Locomotion and gesture tracking in mice and small animals for neurosceince applications: A survey
Mar 25, 2019


Neuroscience has traditionally relied on manually observing lab animals in controlled environments. Researchers usually record animals behaving in free or restrained manner and then annotate the data manually. The manual annotation is not desirable for three reasons; one, it is time consuming, two, it is prone to human errors and three, no two human annotators will 100\% agree on annotation, so it is not reproducible. Consequently, automated annotation of such data has gained traction because it is efficient and replicable. Usually, the automatic annotation of neuroscience data relies on computer vision and machine leaning techniques. In this article, we have covered most of the approaches taken by researchers for locomotion and gesture tracking of lab animals. We have divided these papers in categories based upon the hardware they use and the software approach they take. We also have summarized their strengths and weaknesses.
Soft Computing Techniques for Dependable Cyber-Physical Systems
Jan 25, 2018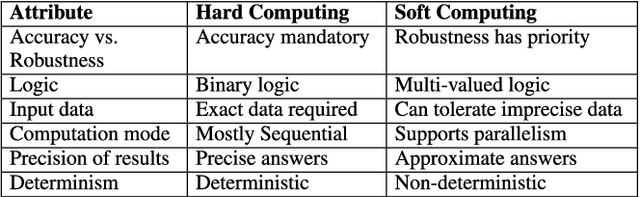
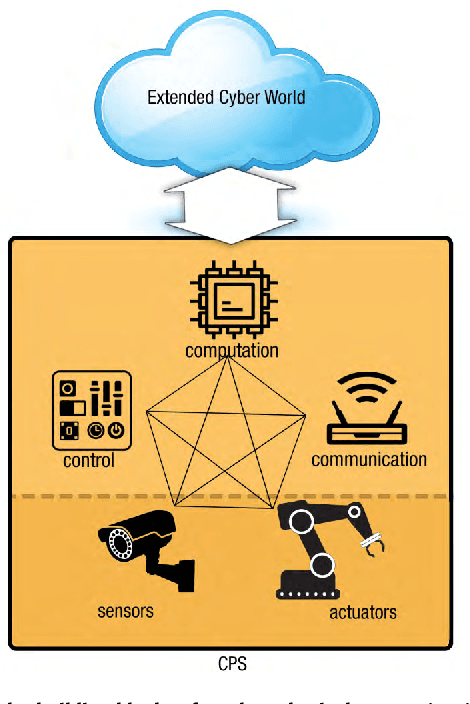
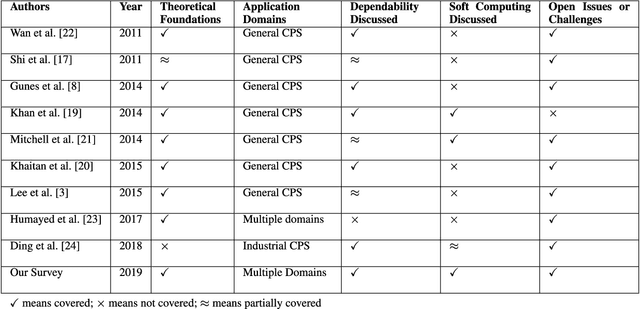

Cyber-Physical Systems (CPS) allow us to manipulate objects in the physical world by providing a communication bridge between computation and actuation elements. In the current scheme of things, this sought-after control is marred by limitations inherent in the underlying communication network(s) as well as by the uncertainty found in the physical world. These limitations hamper fine-grained control of elements that may be separated by large-scale distances. In this regard, soft computing is an emerging paradigm that can help to overcome the vulnerabilities, and unreliability of CPS by using techniques including fuzzy systems, neural network, evolutionary computation, probabilistic reasoning and rough sets. In this paper, we present a comprehensive contemporary review of soft computing techniques for CPS dependability modeling, analysis, and improvement. This paper provides an overview of CPS applications, explores the foundations of dependability engineering, and highlights the potential role of soft computing techniques for CPS dependability with various case studies, while identifying common pitfalls and future directions. In addition, this paper provides a comprehensive survey on the use of various soft computing techniques for making CPS dependable.