 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Backbones: Sparsifying Graphs through Zero Forcing for Effective Graph-Based Learning
Feb 24, 2025This paper introduces a novel framework for graph sparsification that preserves the essential learning attributes of original graphs, improving computational efficiency and reducing complexity in learning algorithms. We refer to these sparse graphs as "learning backbones". Our approach leverages the zero-forcing (ZF) phenomenon, a dynamic process on graphs with applications in network control. The key idea is to generate a tree from the original graph that retains critical dynamical properties. By correlating these properties with learning attributes, we construct effective learning backbones. We evaluate the performance of our ZF-based backbones in graph classification tasks across eight datasets and six baseline models. The results demonstrate that our method outperforms existing techniques. Additionally, we explore extensions using node distance metrics to further enhance the framework's utility.
Improving Graph Machine Learning Performance Through Feature Augmentation Based on Network Control Theory
May 03, 2024Network control theory (NCT) offers a robust analytical framework for understanding the influence of network topology on dynamic behaviors, enabling researchers to decipher how certain patterns of external control measures can steer system dynamics towards desired states. Distinguished from other structure-function methodologies, NCT's predictive capabilities can be coupled with deploying Graph Neural Networks (GNNs), which have demonstrated exceptional utility in various network-based learning tasks. However, the performance of GNNs heavily relies on the expressiveness of node features, and the lack of node features can greatly degrade their performance. Furthermore, many real-world systems may lack node-level information, posing a challenge for GNNs.To tackle this challenge, we introduce a novel approach, NCT-based Enhanced Feature Augmentation (NCT-EFA), that assimilates average controllability, along with other centrality indices, into the feature augmentation pipeline to enhance GNNs performance. Our evaluation of NCT-EFA, on six benchmark GNN models across two experimental setting. solely employing average controllability and in combination with additional centrality metrics. showcases an improved performance reaching as high as 11%. Our results demonstrate that incorporating NCT into feature enrichment can substantively extend the applicability and heighten the performance of GNNs in scenarios where node-level information is unavailable.
Control-based Graph Embeddings with Data Augmentation for Contrastive Learning
Mar 07, 2024In this paper, we study the problem of unsupervised graph representation learning by harnessing the control properties of dynamical networks defined on graphs. Our approach introduces a novel framework for contrastive learning, a widely prevalent technique for unsupervised representation learning. A crucial step in contrastive learning is the creation of 'augmented' graphs from the input graphs. Though different from the original graphs, these augmented graphs retain the original graph's structural characteristics. Here, we propose a unique method for generating these augmented graphs by leveraging the control properties of networks. The core concept revolves around perturbing the original graph to create a new one while preserving the controllability properties specific to networks and graphs. Compared to the existing methods, we demonstrate that this innovative approach enhances the effectiveness of contrastive learning frameworks, leading to superior results regarding the accuracy of the classification tasks. The key innovation lies in our ability to decode the network structure using these control properties, opening new avenues for unsupervised graph representation learning.
Enhanced Graph Neural Networks with Ego-Centric Spectral Subgraph Embeddings Augmentation
Oct 10, 2023



Graph Neural Networks (GNNs) have shown remarkable merit in performing various learning-based tasks in complex networks. The superior performance of GNNs often correlates with the availability and quality of node-level features in the input networks. However, for many network applications, such node-level information may be missing or unreliable, thereby limiting the applicability and efficacy of GNNs. To address this limitation, we present a novel approach denoted as Ego-centric Spectral subGraph Embedding Augmentation (ESGEA), which aims to enhance and design node features, particularly in scenarios where information is lacking. Our method leverages the topological structure of the local subgraph to create topology-aware node features. The subgraph features are generated using an efficient spectral graph embedding technique, and they serve as node features that capture the local topological organization of the network. The explicit node features, if present, are then enhanced with the subgraph embeddings in order to improve the overall performance. ESGEA is compatible with any GNN-based architecture and is effective even in the absence of node features. We evaluate the proposed method in a social network graph classification task where node attributes are unavailable, as well as in a node classification task where node features are corrupted or even absent. The evaluation results on seven datasets and eight baseline models indicate up to a 10% improvement in AUC and a 7% improvement in accuracy for graph and node classification tasks, respectively.
NeuroGraph: Benchmarks for Graph Machine Learning in Brain Connectomics
Jun 25, 2023Machine learning provides a valuable tool for analyzing high-dimensional functional neuroimaging data, and is proving effective in predicting various neurological conditions, psychiatric disorders, and cognitive patterns. In functional Magnetic Resonance Imaging (MRI) research, interactions between brain regions are commonly modeled using graph-based representations. The potency of graph machine learning methods has been established across myriad domains, marking a transformative step in data interpretation and predictive modeling. Yet, despite their promise, the transposition of these techniques to the neuroimaging domain remains surprisingly under-explored due to the expansive preprocessing pipeline and large parameter search space for graph-based datasets construction. In this paper, we introduce NeuroGraph, a collection of graph-based neuroimaging datasets that span multiple categories of behavioral and cognitive traits. We delve deeply into the dataset generation search space by crafting 35 datasets within both static and dynamic contexts, running in excess of 15 baseline methods for benchmarking. Additionally, we provide generic frameworks for learning on dynamic as well as static graphs. Our extensive experiments lead to several key observations. Notably, using correlation vectors as node features, incorporating larger number of regions of interest, and employing sparser graphs lead to improved performance. To foster further advancements in graph-based data driven Neuroimaging, we offer a comprehensive open source Python package that includes the datasets, baseline implementations, model training, and standard evaluation. The package is publicly accessible at https://anwar-said.github.io/anwarsaid/neurograph.html .
Learning-Based Heuristic for Combinatorial Optimization of the Minimum Dominating Set Problem using Graph Convolutional Networks
Jun 06, 2023A dominating set of a graph $\mathcal{G=(V, E)}$ is a subset of vertices $S\subseteq\mathcal{V}$ such that every vertex $v\in \mathcal{V} \setminus S$ outside the dominating set is adjacent to a vertex $u\in S$ within the set. The minimum dominating set problem seeks to find a dominating set of minimum cardinality and is a well-established NP-hard combinatorial optimization problem. We propose a novel learning-based heuristic approach to compute solutions for the minimum dominating set problem using graph convolutional networks. We conduct an extensive experimental evaluation of the proposed method on a combination of randomly generated graphs and real-world graph datasets. Our results indicate that the proposed learning-based approach can outperform a classical greedy approximation algorithm. Furthermore, we demonstrate the generalization capability of the graph convolutional network across datasets and its ability to scale to graphs of higher order than those on which it was trained. Finally, we utilize the proposed learning-based heuristic in an iterative greedy algorithm, achieving state-of-the-art performance in the computation of dominating sets.
Computing Graph Descriptors on Edge Streams
Sep 02, 2021
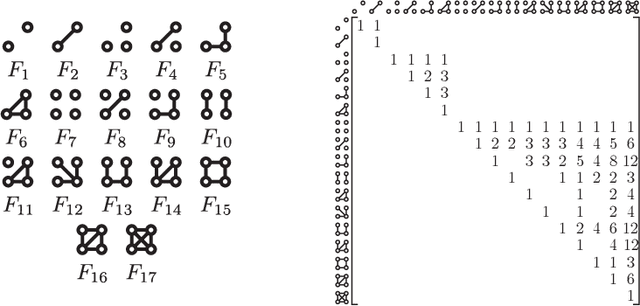

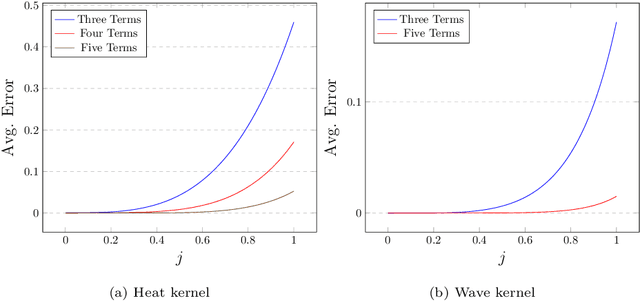
Graph feature extraction is a fundamental task in graphs analytics. Using feature vectors (graph descriptors) in tandem with data mining algorithms that operate on Euclidean data, one can solve problems such as classification, clustering, and anomaly detection on graph-structured data. This idea has proved fruitful in the past, with spectral-based graph descriptors providing state-of-the-art classification accuracy on benchmark datasets. However, these algorithms do not scale to large graphs since: 1) they require storing the entire graph in memory, and 2) the end-user has no control over the algorithm's runtime. In this paper, we present single-pass streaming algorithms to approximate structural features of graphs (counts of subgraphs of order $k \geq 4$). Operating on edge streams allows us to avoid keeping the entire graph in memory, and controlling the sample size enables us to control the time taken by the algorithm. We demonstrate the efficacy of our descriptors by analyzing the approximation error, classification accuracy, and scalability to massive graphs. Our experiments showcase the effect of the sample size on approximation error and predictive accuracy. The proposed descriptors are applicable on graphs with millions of edges within minutes and outperform the state-of-the-art descriptors in classification accuracy.
SEMOUR: A Scripted Emotional Speech Repository for Urdu
May 19, 2021

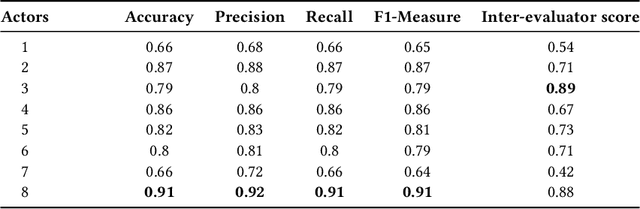
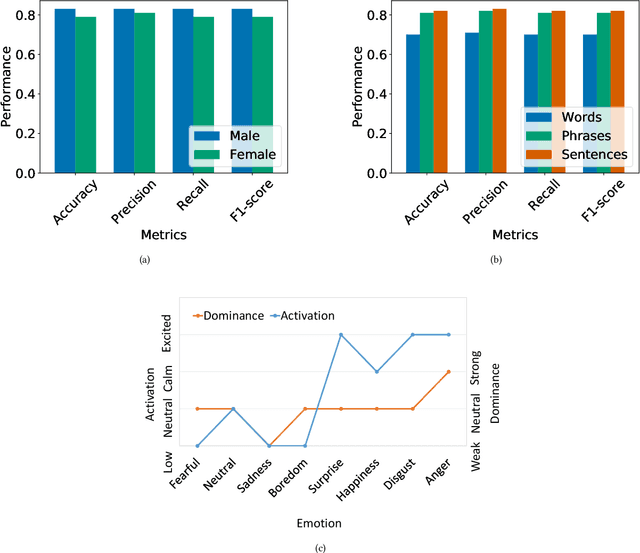
Designing reliable Speech Emotion Recognition systems is a complex task that inevitably requires sufficient data for training purposes. Such extensive datasets are currently available in only a few languages, including English, German, and Italian. In this paper, we present SEMOUR, the first scripted database of emotion-tagged speech in the Urdu language, to design an Urdu Speech Recognition System. Our gender-balanced dataset contains 15,040 unique instances recorded by eight professional actors eliciting a syntactically complex script. The dataset is phonetically balanced, and reliably exhibits a varied set of emotions as marked by the high agreement scores among human raters in experiments. We also provide various baseline speech emotion prediction scores on the database, which could be used for various applications like personalized robot assistants, diagnosis of psychological disorders, and getting feedback from a low-tech-enabled population, etc. On a random test sample, our model correctly predicts an emotion with a state-of-the-art 92% accuracy.