 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDI: ESKF-based Disjoint Initialization for Visual-Inertial SLAM Systems
Aug 04, 2023



Visual-inertial initialization can be classified into joint and disjoint approaches. Joint approaches tackle both the visual and the inertial parameters together by aligning observations from feature-bearing points based on IMU integration then use a closed-form solution with visual and acceleration observations to find initial velocity and gravity. In contrast, disjoint approaches independently solve the Structure from Motion (SFM) problem and determine inertial parameters from up-to-scale camera poses obtained from pure monocular SLAM. However, previous disjoint methods have limitations, like assuming negligible acceleration bias impact or accurate rotation estimation by pure monocular SLAM. To address these issues, we propose EDI, a novel approach for fast, accurate, and robust visual-inertial initialization. Our method incorporates an Error-state Kalman Filter (ESKF) to estimate gyroscope bias and correct rotation estimates from monocular SLAM, overcoming dependence on pure monocular SLAM for rotation estimation. To estimate the scale factor without prior information, we offer a closed-form solution for initial velocity, scale, gravity, and acceleration bias estimation. To address gravity and acceleration bias coupling, we introduce weights in the linear least-squares equations, ensuring acceleration bias observability and handling outliers. Extensive evaluation on the EuRoC dataset shows that our method achieves an average scale error of 5.8% in less than 3 seconds, outperforming other state-of-the-art disjoint visual-inertial initialization approaches, even in challenging environments and with artificial noise corruption.
EDDA: Explanation-driven Data Augmentation to Improve Model and Explanation Alignment
Jun 19, 2021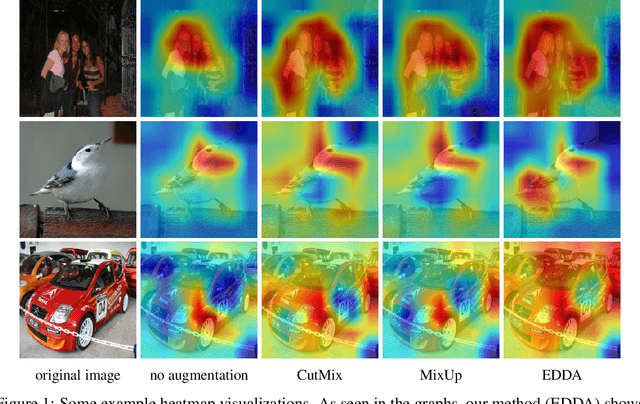
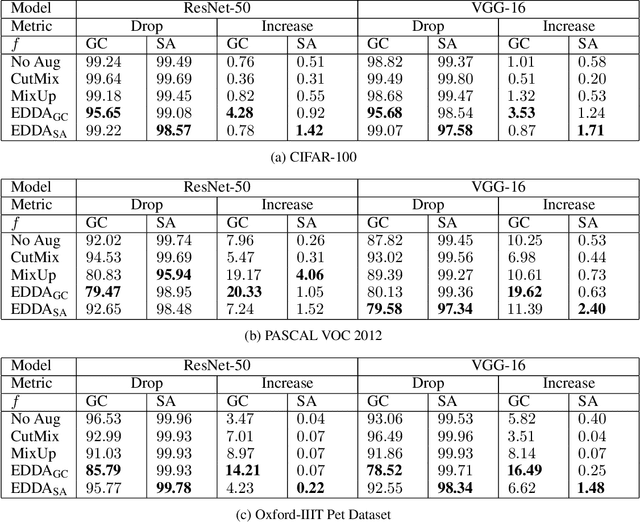
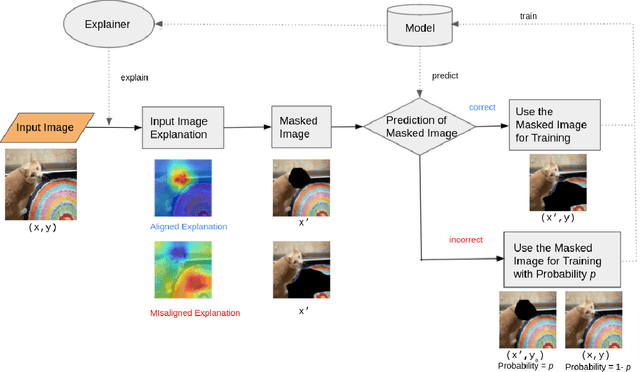
Recent years have seen the introduction of a range of methods for post-hoc explainability of image classifier predictions. However, these post-hoc explanations may not always align perfectly with classifier predictions, which poses a significant challenge when attempting to debug models based on such explanations. To this end, we seek a methodology that can improve alignment between model predictions and explanation method that is both agnostic to the model and explanation classes and which does not require ground truth explanations. We achieve this through a novel explanation-driven data augmentation (EDDA) method that augments the training data with occlusions of existing data stemming from model-explanations; this is based on the simple motivating principle that occluding salient regions for the model prediction should decrease the model confidence in the prediction, while occluding non-salient regions should not change the prediction -- if the model and explainer are aligned. To verify that this augmentation method improves model and explainer alignment, we evaluate the methodology on a variety of datasets, image classification models, and explanation methods. We verify in all cases that our explanation-driven data augmentation method improves alignment of the model and explanation in comparison to no data augmentation and non-explanation driven data augmentation methods. In conclusion, this approach provides a novel model- and explainer-agnostic methodology for improving alignment between model predictions and explanations, which we see as a critical step forward for practical deployment and debugging of image classification models.
Byzantine Resilient Distributed Multi-Task Learning
Oct 25, 2020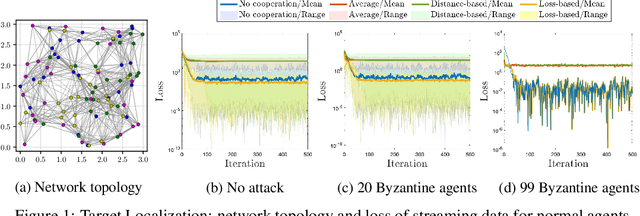
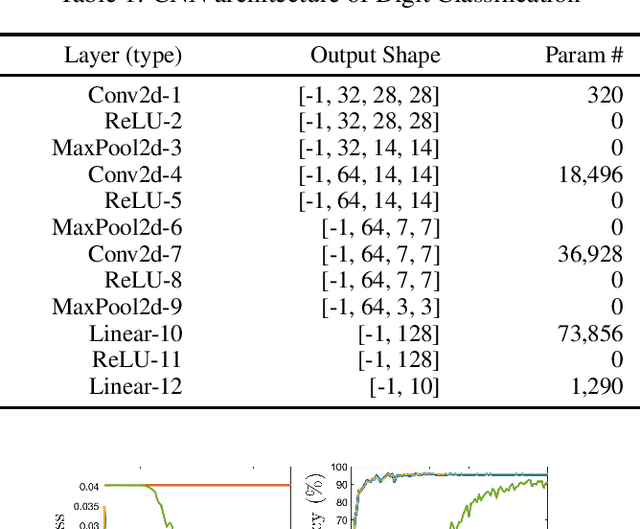
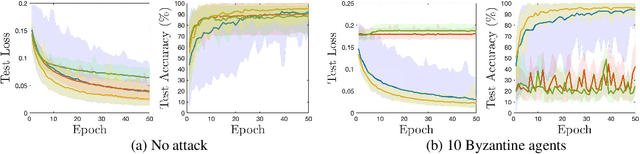
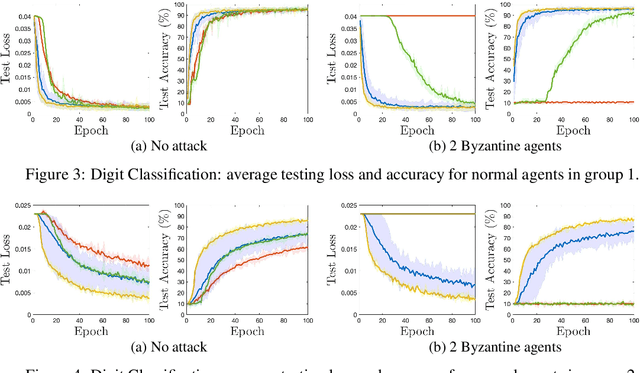
Distributed multi-task learning provides significant advantages in multi-agent networks with heterogeneous data sources where agents aim to learn distinct but correlated models simultaneously. However, distributed algorithms for learning relatedness among tasks are not resilient in the presence of Byzantine agents. In this paper, we present an approach for Byzantine resilient distributed multi-task learning. We propose an efficient online weight assignment rule by measuring the accumulated loss using an agent's data and its neighbors' models. A small accumulated loss indicates a large similarity between the two tasks. In order to ensure the Byzantine resilience of the aggregation at a normal agent, we introduce a step for filtering out larger losses. We analyze the approach for convex models and show that normal agents converge resiliently towards their true targets. Further, an agent's learning performance using the proposed weight assignment rule is guaranteed to be at least as good as in the non-cooperative case as measured by the expected regret. Finally, we demonstrate the approach using three case studies, including regression and classification problems, and show that our method exhibits good empirical performance for non-convex models, such as convolutional neural networks.
Detecting Adversarial Examples in Learning-Enabled Cyber-Physical Systems using Variational Autoencoder for Regression
Mar 21, 2020
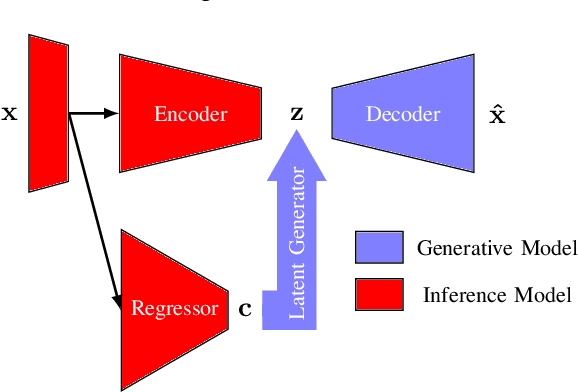
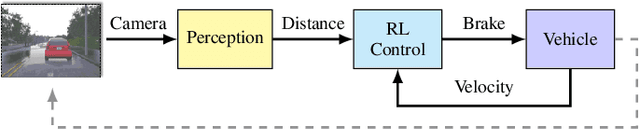
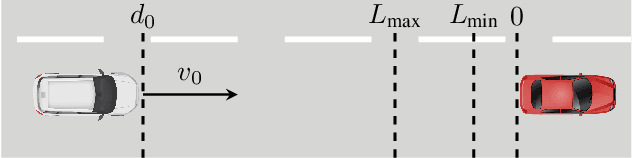
Learning-enabled components (LECs) are widely used in cyber-physical systems (CPS) since they can handle the uncertainty and variability of the environment and increase the level of autonomy. However, it has been shown that LECs such as deep neural networks (DNN) are not robust and adversarial examples can cause the model to make a false prediction. The paper considers the problem of efficiently detecting adversarial examples in LECs used for regression in CPS. The proposed approach is based on inductive conformal prediction and uses a regression model based on variational autoencoder. The architecture allows to take into consideration both the input and the neural network prediction for detecting adversarial, and more generally, out-of-distribution examples. We demonstrate the method using an advanced emergency braking system implemented in an open source simulator for self-driving cars where a DNN is used to estimate the distance to an obstacle. The simulation results show that the method can effectively detect adversarial examples with a short detection delay.
Accurate Temporal Action Proposal Generation with Relation-Aware Pyramid Network
Mar 09, 2020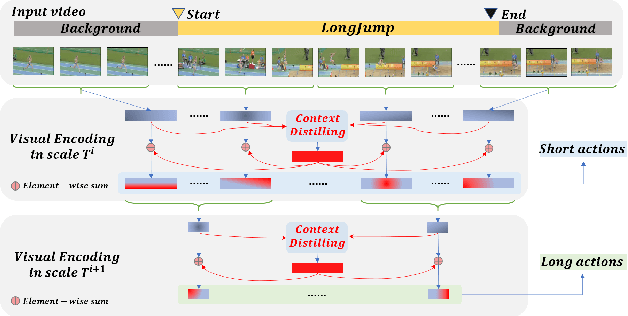
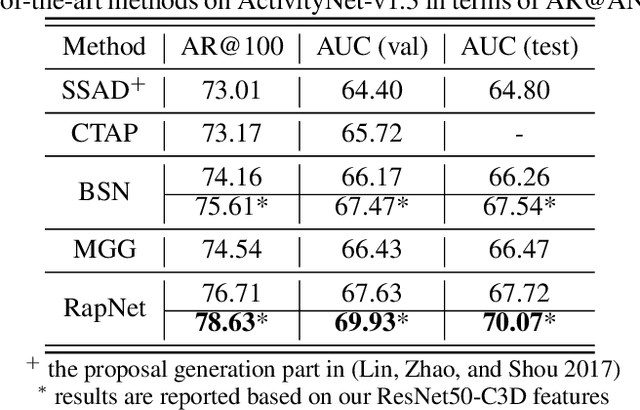
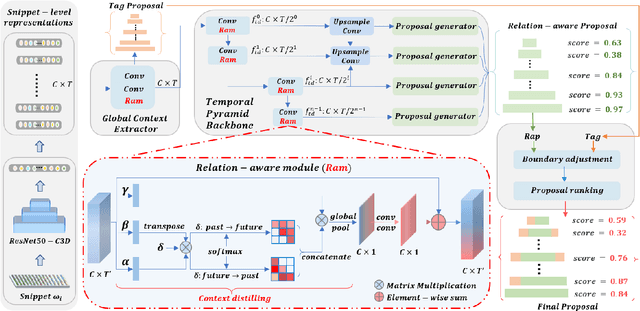
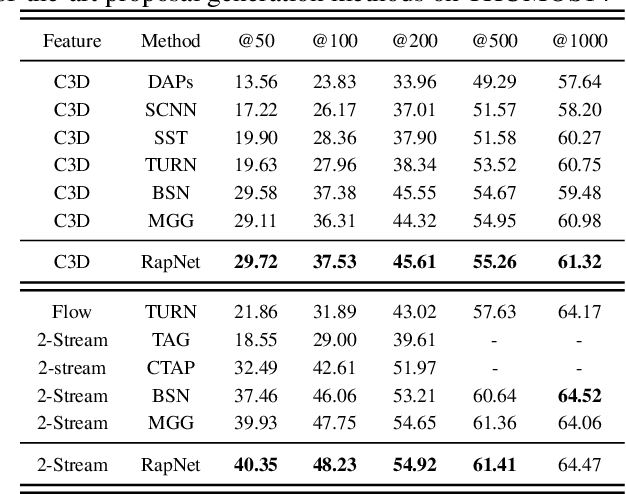
Accurate temporal action proposals play an important role in detecting actions from untrimmed videos. The existing approaches have difficulties in capturing global contextual information and simultaneously localizing actions with different durations. To this end, we propose a Relation-aware pyramid Network (RapNet) to generate highly accurate temporal action proposals. In RapNet, a novel relation-aware module is introduced to exploit bi-directional long-range relations between local features for context distilling. This embedded module enhances the RapNet in terms of its multi-granularity temporal proposal generation ability, given predefined anchor boxes. We further introduce a two-stage adjustment scheme to refine the proposal boundaries and measure their confidence in containing an action with snippet-level actionness. Extensive experiments on the challenging ActivityNet and THUMOS14 benchmarks demonstrate our RapNet generates superior accurate proposals over the existing state-of-the-art methods.
Relation-Aware Pyramid Network (RapNet) for temporal action proposal
Aug 09, 2019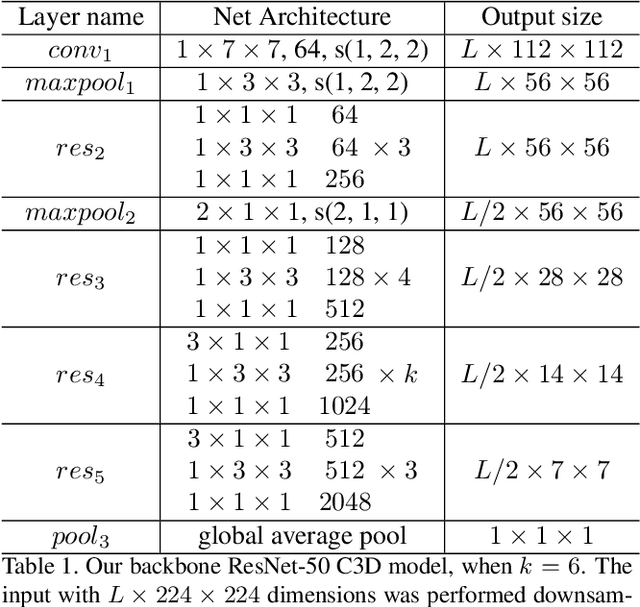
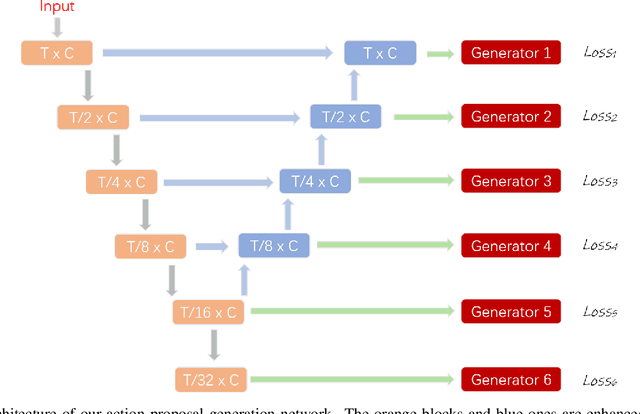
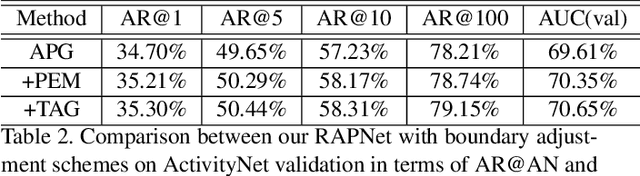
In this technical report, we describe our solution to temporal action proposal (task 1) in ActivityNet Challenge 2019. First, we fine-tune a ResNet-50-C3D CNN on ActivityNet v1.3 based on Kinetics pretrained model to extract snippet-level video representations and then we design a Relation-Aware Pyramid Network (RapNet) to generate temporal multiscale proposals with confidence score. After that, we employ a two-stage snippet-level boundary adjustment scheme to re-rank the order of generated proposals. Ensemble methods are also been used to improve the performance of our solution, which helps us achieve 2nd place.