 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance analysis of satellite-terrestrial integrated radio access networks based on stochastic geometry
Apr 15, 2024To enhance coverage and improve service continuity, satellite-terrestrial integrated radio access network (STIRAN) has been seen as an essential trend in the development of 6G. However, there is still a lack of theoretical analysis on its coverage performance. To fill this gap, we first establish a system model to characterize a typical scenario where low-earth-orbit (LEO) satellites and terrestrial base stations are both deployed. Then, stochastic geometry is utilized to analyze the downlink coverage probability under the setting of shared frequency and distinct frequencies. Specifically, we derive mathematical expressions for the distances distribution from the serving station to the typical user and the associated probability based on the maximum bias power selection strategy (Max-BPR). Taking into account real-world satellite antenna beamforming patterns in two system scenarios, we derive the downlink coverage probabilities in terms of parameters such as base station density and orbital inclination. Finally, the correctness of the theoretical derivations is verified through experimental simulations, and the influence of network design parameters on the downlink coverage probability is analyzed.
Segment Anything Model (SAM) Enhanced Pseudo Labels for Weakly Supervised Semantic Segmentation
May 09, 2023



Weakly Supervised Semantic Segmentation (WSSS) with only image-level supervision has garnered increasing attention due to its low annotation cost compared to pixel-level annotation. Most existing methods rely on Class Activation Maps (CAM) to generate pixel-level pseudo labels for supervised training. However, it is well known that CAM often suffers from partial activation -- activating the most discriminative part instead of the entire object area, and false activation -- unnecessarily activating the background around the object. In this study, we introduce a simple yet effective approach to address these limitations by harnessing the recently released Segment Anything Model (SAM) to generate higher-quality pseudo labels with CAM. SAM is a segmentation foundation model that demonstrates strong zero-shot ability in partitioning images into segments but lacks semantic labels for these regions. To circumvent this, we employ pseudo labels for a specific class as the signal to select the most relevant masks and label them to generate the refined pseudo labels for this class. The segments generated by SAM are highly precise, leading to substantial improvements in partial and false activation. Moreover, existing post-processing modules for producing pseudo labels, such as AffinityNet, are often computationally heavy, with a significantly long training time. Surprisingly, we discovered that using the initial CAM with SAM can achieve on-par performance as the post-processed pseudo label generated from these modules with much less computational cost. Our approach is highly versatile and capable of seamless integration into existing WSSS models without modification to base networks or pipelines. Despite its simplicity, our approach improves the mean Intersection over Union (mIoU) of pseudo labels from five state-of-the-art WSSS methods by 6.2\% on average on the PASCAL VOC 2012 dataset.
TransCAM: Transformer Attention-based CAM Refinement for Weakly Supervised Semantic Segmentation
Mar 14, 2022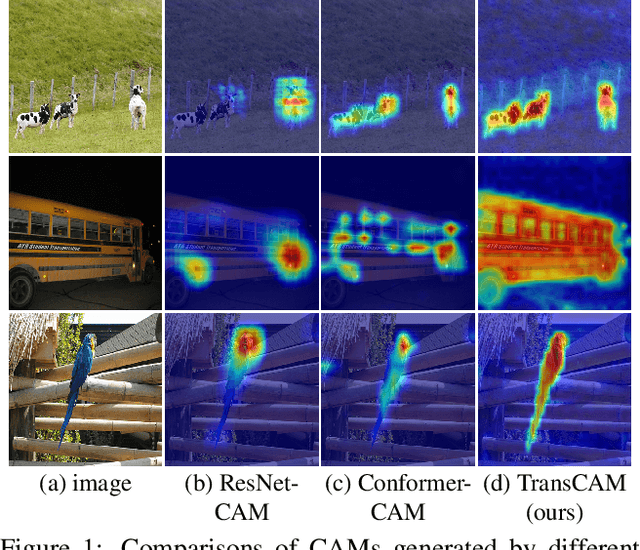

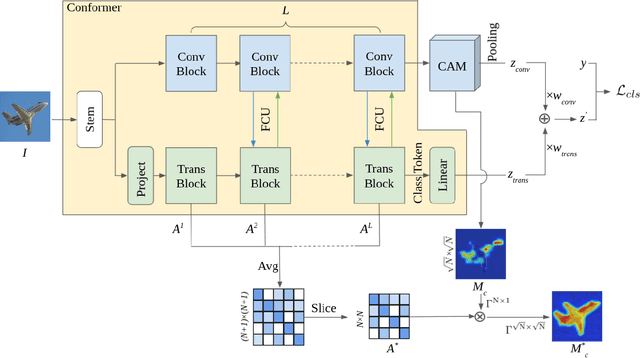

Weakly supervised semantic segmentation (WSSS) with only image-level supervision is a challenging task. Most existing methods exploit Class Activation Maps (CAM) to generate pixel-level pseudo labels for supervised training. However, due to the local receptive field of Convolution Neural Networks (CNN), CAM applied to CNNs often suffers from partial activation -- highlighting the most discriminative part instead of the entire object area. In order to capture both local features and global representations, the Conformer has been proposed to combine a visual transformer branch with a CNN branch. In this paper, we propose TransCAM, a Conformer-based solution to WSSS that explicitly leverages the attention weights from the transformer branch of the Conformer to refine the CAM generated from the CNN branch. TransCAM is motivated by our observation that attention weights from shallow transformer blocks are able to capture low-level spatial feature similarities while attention weights from deep transformer blocks capture high-level semantic context. Despite its simplicity, TransCAM achieves a new state-of-the-art performance of 69.3% and 69.6% on the respective PASCAL VOC 2012 validation and test sets, showing the effectiveness of transformer attention-based refinement of CAM for WSSS.
ExCon: Explanation-driven Supervised Contrastive Learning for Image Classification
Dec 10, 2021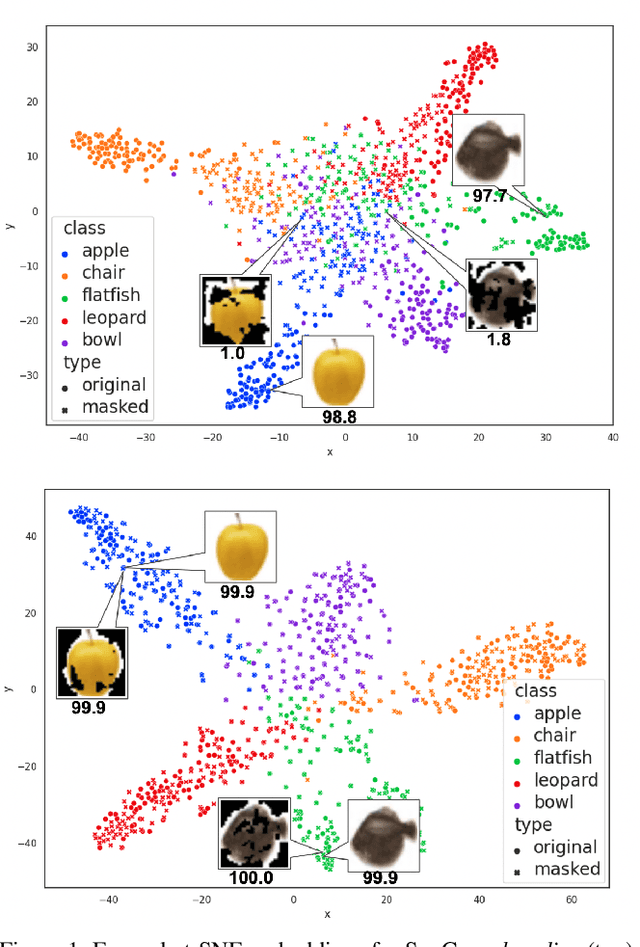
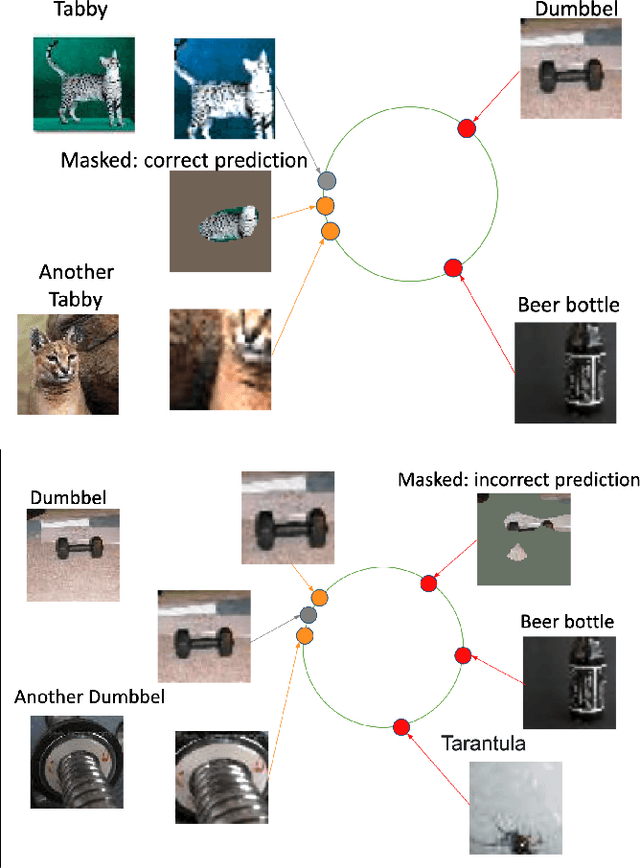
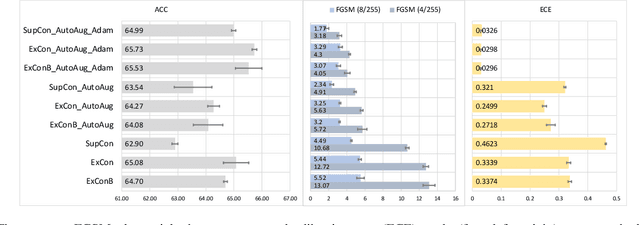
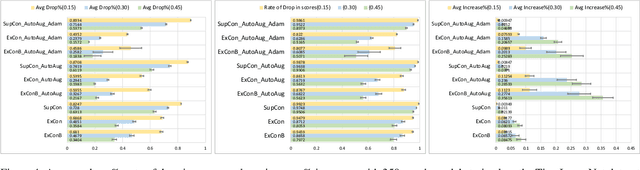
Contrastive learning has led to substantial improvements in the quality of learned embedding representations for tasks such as image classification. However, a key drawback of existing contrastive augmentation methods is that they may lead to the modification of the image content which can yield undesired alterations of its semantics. This can affect the performance of the model on downstream tasks. Hence, in this paper, we ask whether we can augment image data in contrastive learning such that the task-relevant semantic content of an image is preserved. For this purpose, we propose to leverage saliency-based explanation methods to create content-preserving masked augmentations for contrastive learning. Our novel explanation-driven supervised contrastive learning (ExCon) methodology critically serves the dual goals of encouraging nearby image embeddings to have similar content and explanation. To quantify the impact of ExCon, we conduct experiments on the CIFAR-100 and the Tiny ImageNet datasets. We demonstrate that ExCon outperforms vanilla supervised contrastive learning in terms of classification, explanation quality, adversarial robustness as well as calibration of probabilistic predictions of the model in the context of distributional shift.
EDDA: Explanation-driven Data Augmentation to Improve Model and Explanation Alignment
Jun 19, 2021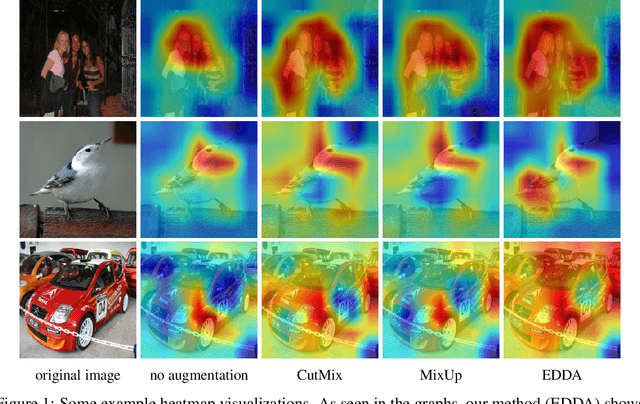
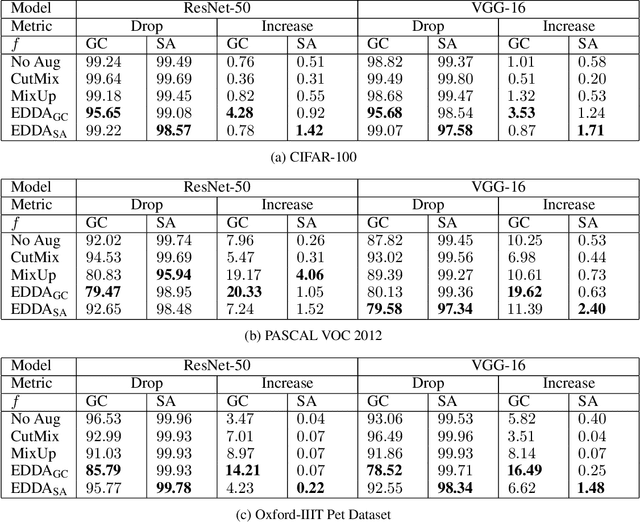
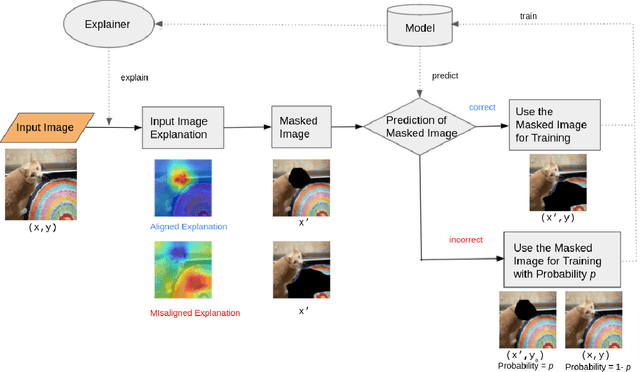
Recent years have seen the introduction of a range of methods for post-hoc explainability of image classifier predictions. However, these post-hoc explanations may not always align perfectly with classifier predictions, which poses a significant challenge when attempting to debug models based on such explanations. To this end, we seek a methodology that can improve alignment between model predictions and explanation method that is both agnostic to the model and explanation classes and which does not require ground truth explanations. We achieve this through a novel explanation-driven data augmentation (EDDA) method that augments the training data with occlusions of existing data stemming from model-explanations; this is based on the simple motivating principle that occluding salient regions for the model prediction should decrease the model confidence in the prediction, while occluding non-salient regions should not change the prediction -- if the model and explainer are aligned. To verify that this augmentation method improves model and explainer alignment, we evaluate the methodology on a variety of datasets, image classification models, and explanation methods. We verify in all cases that our explanation-driven data augmentation method improves alignment of the model and explanation in comparison to no data augmentation and non-explanation driven data augmentation methods. In conclusion, this approach provides a novel model- and explainer-agnostic methodology for improving alignment between model predictions and explanations, which we see as a critical step forward for practical deployment and debugging of image classification models.
Supervised Contrastive Replay: Revisiting the Nearest Class Mean Classifier in Online Class-Incremental Continual Learning
Mar 22, 2021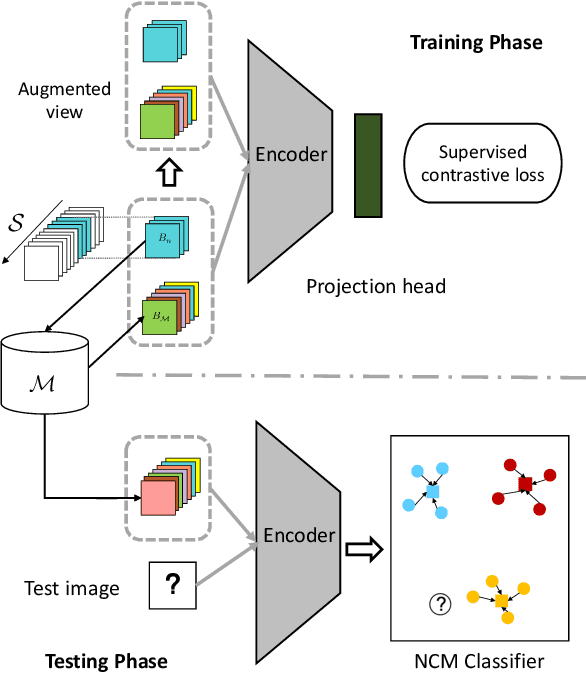
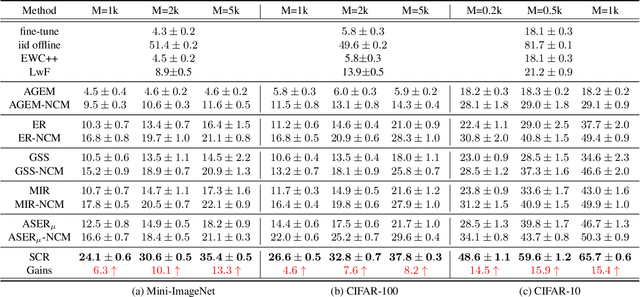

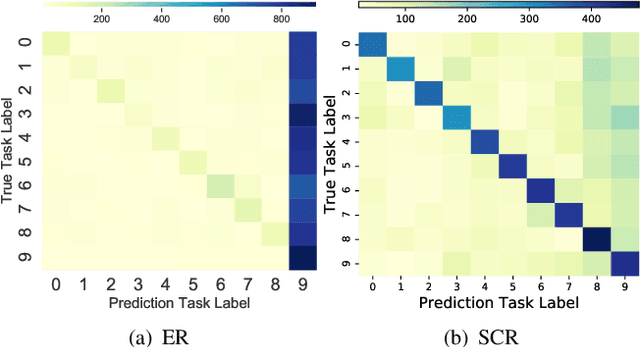
Online class-incremental continual learning (CL) studies the problem of learning new classes continually from an online non-stationary data stream, intending to adapt to new data while mitigating catastrophic forgetting. While memory replay has shown promising results, the recency bias in online learning caused by the commonly used Softmax classifier remains an unsolved challenge. Although the Nearest-Class-Mean (NCM) classifier is significantly undervalued in the CL community, we demonstrate that it is a simple yet effective substitute for the Softmax classifier. It addresses the recency bias and avoids structural changes in the fully-connected layer for new classes. Moreover, we observe considerable and consistent performance gains when replacing the Softmax classifier with the NCM classifier for several state-of-the-art replay methods. To leverage the NCM classifier more effectively, data embeddings belonging to the same class should be clustered and well-separated from those with a different class label. To this end, we contribute Supervised Contrastive Replay (SCR), which explicitly encourages samples from the same class to cluster tightly in embedding space while pushing those of different classes further apart during replay-based training. Overall, we observe that our proposed SCR substantially reduces catastrophic forgetting and outperforms state-of-the-art CL methods by a significant margin on a variety of datasets.
Online Continual Learning in Image Classification: An Empirical Survey
Jan 25, 2021
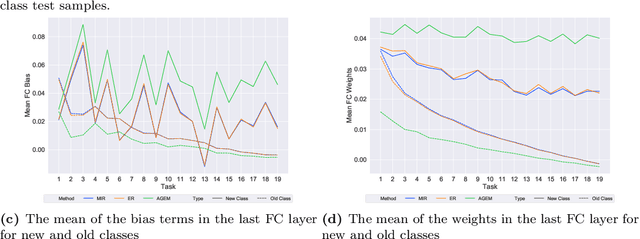

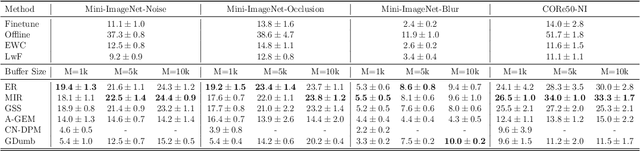
Online continual learning for image classification studies the problem of learning to classify images from an online stream of data and tasks, where tasks may include new classes (class incremental) or data nonstationarity (domain incremental). One of the key challenges of continual learning is to avoid catastrophic forgetting (CF), i.e., forgetting old tasks in the presence of more recent tasks. Over the past few years, many methods and tricks have been introduced to address this problem, but many have not been fairly and systematically compared under a variety of realistic and practical settings. To better understand the relative advantages of various approaches and the settings where they work best, this survey aims to (1) compare state-of-the-art methods such as MIR, iCARL, and GDumb and determine which works best at different experimental settings; (2) determine if the best class incremental methods are also competitive in domain incremental setting; (3) evaluate the performance of 7 simple but effective trick such as "review" trick and nearest class mean (NCM) classifier to assess their relative impact. Regarding (1), we observe earlier proposed iCaRL remains competitive when the memory buffer is small; GDumb outperforms many recently proposed methods in medium-size datasets and MIR performs the best in larger-scale datasets. For (2), we note that GDumb performs quite poorly while MIR -- already competitive for (1) -- is also strongly competitive in this very different but important setting. Overall, this allows us to conclude that MIR is overall a strong and versatile method across a wide variety of settings. For (3), we find that all 7 tricks are beneficial, and when augmented with the "review" trick and NCM classifier, MIR produces performance levels that bring online continual learning much closer to its ultimate goal of matching offline training.