 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransCAM: Transformer Attention-based CAM Refinement for Weakly Supervised Semantic Segmentation
Mar 14, 2022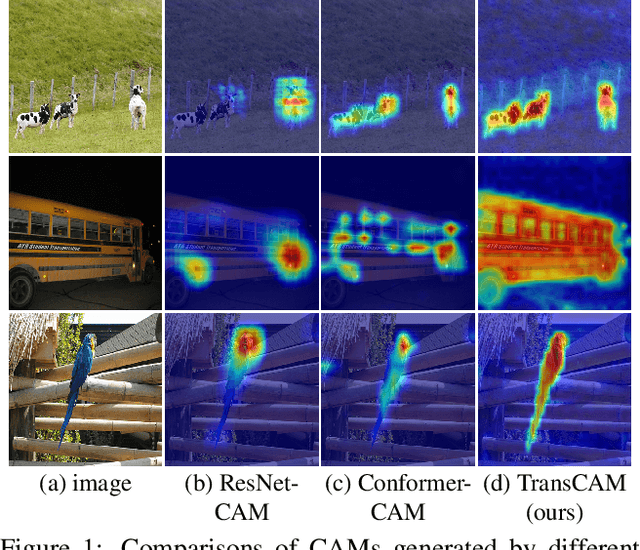

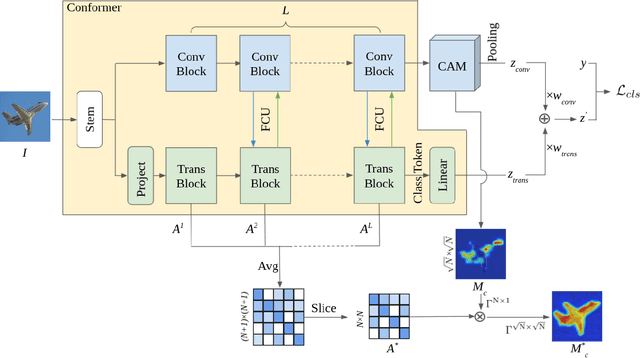

Weakly supervised semantic segmentation (WSSS) with only image-level supervision is a challenging task. Most existing methods exploit Class Activation Maps (CAM) to generate pixel-level pseudo labels for supervised training. However, due to the local receptive field of Convolution Neural Networks (CNN), CAM applied to CNNs often suffers from partial activation -- highlighting the most discriminative part instead of the entire object area. In order to capture both local features and global representations, the Conformer has been proposed to combine a visual transformer branch with a CNN branch. In this paper, we propose TransCAM, a Conformer-based solution to WSSS that explicitly leverages the attention weights from the transformer branch of the Conformer to refine the CAM generated from the CNN branch. TransCAM is motivated by our observation that attention weights from shallow transformer blocks are able to capture low-level spatial feature similarities while attention weights from deep transformer blocks capture high-level semantic context. Despite its simplicity, TransCAM achieves a new state-of-the-art performance of 69.3% and 69.6% on the respective PASCAL VOC 2012 validation and test sets, showing the effectiveness of transformer attention-based refinement of CAM for WSSS.
ExCon: Explanation-driven Supervised Contrastive Learning for Image Classification
Dec 10, 2021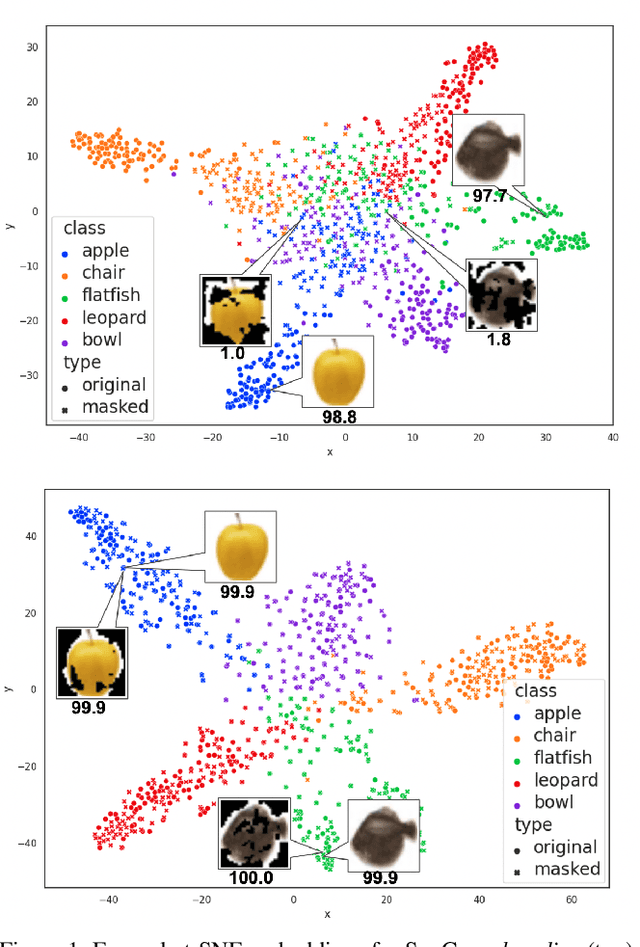
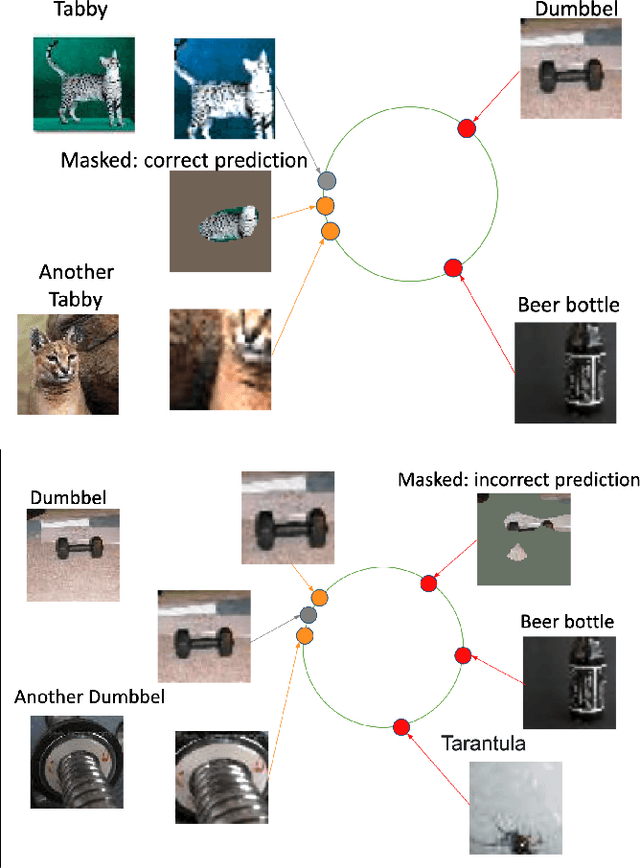
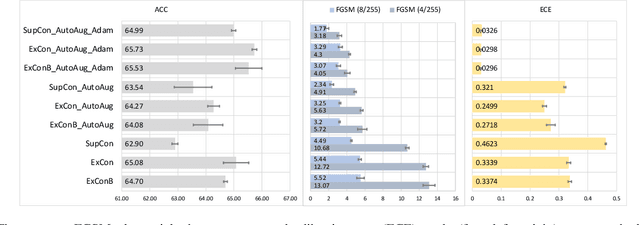
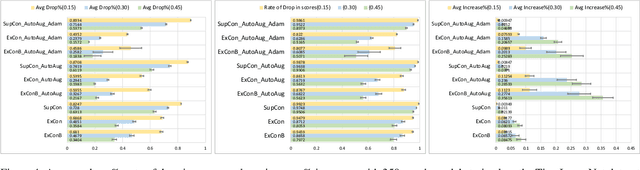
Contrastive learning has led to substantial improvements in the quality of learned embedding representations for tasks such as image classification. However, a key drawback of existing contrastive augmentation methods is that they may lead to the modification of the image content which can yield undesired alterations of its semantics. This can affect the performance of the model on downstream tasks. Hence, in this paper, we ask whether we can augment image data in contrastive learning such that the task-relevant semantic content of an image is preserved. For this purpose, we propose to leverage saliency-based explanation methods to create content-preserving masked augmentations for contrastive learning. Our novel explanation-driven supervised contrastive learning (ExCon) methodology critically serves the dual goals of encouraging nearby image embeddings to have similar content and explanation. To quantify the impact of ExCon, we conduct experiments on the CIFAR-100 and the Tiny ImageNet datasets. We demonstrate that ExCon outperforms vanilla supervised contrastive learning in terms of classification, explanation quality, adversarial robustness as well as calibration of probabilistic predictions of the model in the context of distributional shift.
Quaternion Recurrent Neural Networks
Jul 05, 2018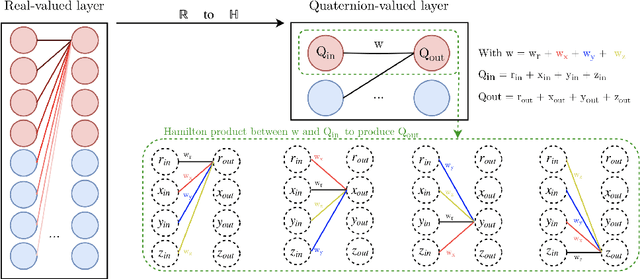
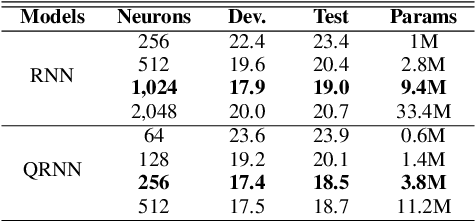
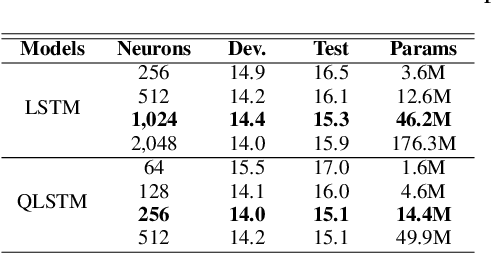

Recurrent neural networks (RNNs) are powerful architectures to model sequential data, due to their capability to learn short and long-term dependencies between the basic elements of a sequence. Nonetheless, popular tasks such as speech or images recognition, involve multi-dimensional input features that are characterized by strong internal dependencies between the dimensions of the input vector. We propose a novel quaternion recurrent neural network (QRNN) that takes into account both the external relations and these internal structural dependencies with the quaternion algebra. Similarly to capsules, quaternions allow the QRNN to code internal dependencies by composing and processing multidimensional features as single entities, while the recurrent operation reveals correlations between the elements composing the sequence. We show that the QRNN achieves better performances in both a synthetic memory copy task and in realistic applications of automatic speech recognition. Finally, we show that the QRNN reduces by a factor of 3x the number of free parameters needed, compared to RNNs to reach better results, leading to a more compact representation of the relevant information.
Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition
Jun 20, 2018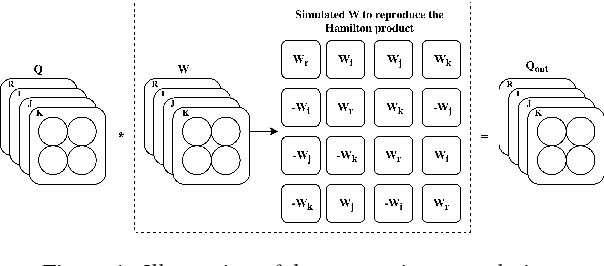
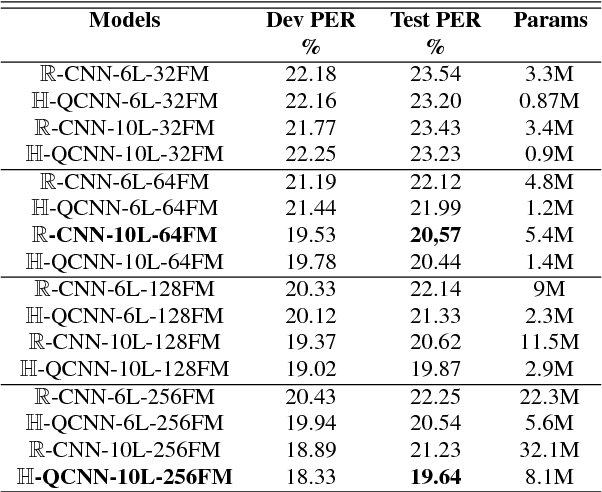
Recently, the connectionist temporal classification (CTC) model coupled with recurrent (RNN) or convolutional neural networks (CNN), made it easier to train speech recognition systems in an end-to-end fashion. However in real-valued models, time frame components such as mel-filter-bank energies and the cepstral coefficients obtained from them, together with their first and second order derivatives, are processed as individual elements, while a natural alternative is to process such components as composed entities. We propose to group such elements in the form of quaternions and to process these quaternions using the established quaternion algebra. Quaternion numbers and quaternion neural networks have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with less learning parameters than real-valued models. This paper proposes to integrate multiple feature views in quaternion-valued convolutional neural network (QCNN), to be used for sequence-to-sequence mapping with the CTC model. Promising results are reported using simple QCNNs in phoneme recognition experiments with the TIMIT corpus. More precisely, QCNNs obtain a lower phoneme error rate (PER) with less learning parameters than a competing model based on real-valued CNNs.
Deep Complex Networks
Feb 25, 2018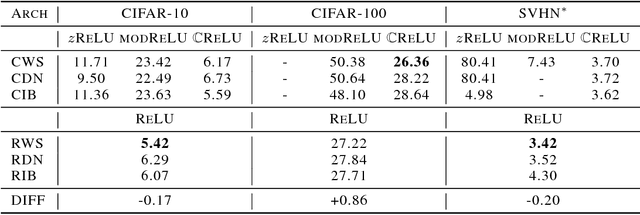
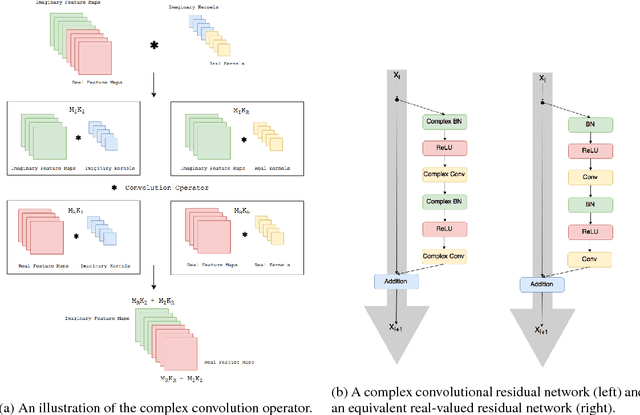

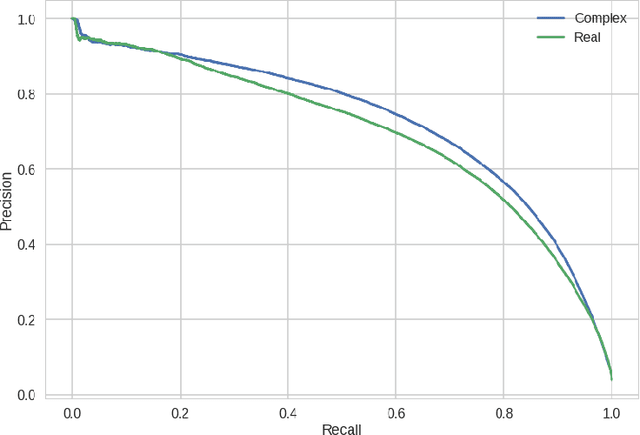
At present, the vast majority of building blocks, techniques, and architectures for deep learning are based on real-valued operations and representations. However, recent work on recurrent neural networks and older fundamental theoretical analysis suggests that complex numbers could have a richer representational capacity and could also facilitate noise-robust memory retrieval mechanisms. Despite their attractive properties and potential for opening up entirely new neural architectures, complex-valued deep neural networks have been marginalized due to the absence of the building blocks required to design such models. In this work, we provide the key atomic components for complex-valued deep neural networks and apply them to convolutional feed-forward networks and convolutional LSTMs. More precisely, we rely on complex convolutions and present algorithms for complex batch-normalization, complex weight initialization strategies for complex-valued neural nets and we use them in experiments with end-to-end training schemes. We demonstrate that such complex-valued models are competitive with their real-valued counterparts. We test deep complex models on several computer vision tasks, on music transcription using the MusicNet dataset and on Speech Spectrum Prediction using the TIMIT dataset. We achieve state-of-the-art performance on these audio-related tasks.
On orthogonality and learning recurrent networks with long term dependencies
Oct 12, 2017
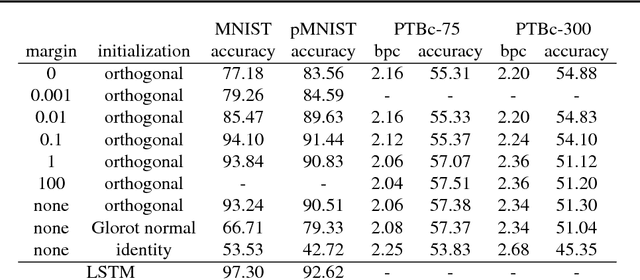
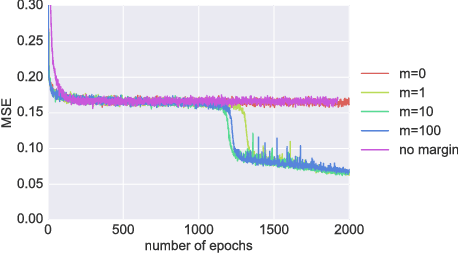

It is well known that it is challenging to train deep neural networks and recurrent neural networks for tasks that exhibit long term dependencies. The vanishing or exploding gradient problem is a well known issue associated with these challenges. One approach to addressing vanishing and exploding gradients is to use either soft or hard constraints on weight matrices so as to encourage or enforce orthogonality. Orthogonal matrices preserve gradient norm during backpropagation and may therefore be a desirable property. This paper explores issues with optimization convergence, speed and gradient stability when encouraging or enforcing orthogonality. To perform this analysis, we propose a weight matrix factorization and parameterization strategy through which we can bound matrix norms and therein control the degree of expansivity induced during backpropagation. We find that hard constraints on orthogonality can negatively affect the speed of convergence and model performance.