 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransCAM: Transformer Attention-based CAM Refinement for Weakly Supervised Semantic Segmentation
Paper and Code
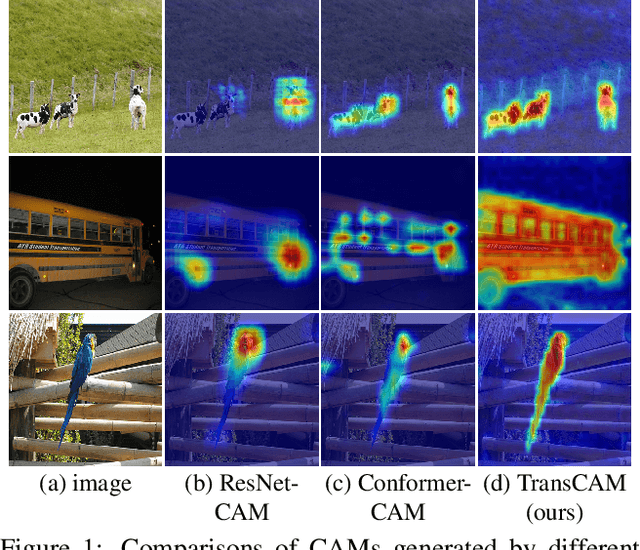

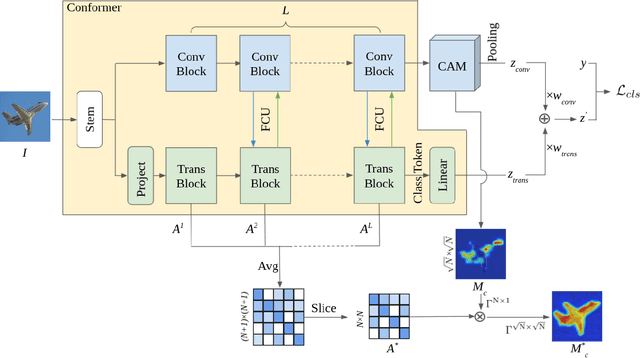

Weakly supervised semantic segmentation (WSSS) with only image-level supervision is a challenging task. Most existing methods exploit Class Activation Maps (CAM) to generate pixel-level pseudo labels for supervised training. However, due to the local receptive field of Convolution Neural Networks (CNN), CAM applied to CNNs often suffers from partial activation -- highlighting the most discriminative part instead of the entire object area. In order to capture both local features and global representations, the Conformer has been proposed to combine a visual transformer branch with a CNN branch. In this paper, we propose TransCAM, a Conformer-based solution to WSSS that explicitly leverages the attention weights from the transformer branch of the Conformer to refine the CAM generated from the CNN branch. TransCAM is motivated by our observation that attention weights from shallow transformer blocks are able to capture low-level spatial feature similarities while attention weights from deep transformer blocks capture high-level semantic context. Despite its simplicity, TransCAM achieves a new state-of-the-art performance of 69.3% and 69.6% on the respective PASCAL VOC 2012 validation and test sets, showing the effectiveness of transformer attention-based refinement of CAM for WSSS.