 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExCon: Explanation-driven Supervised Contrastive Learning for Image Classification
Paper and Code
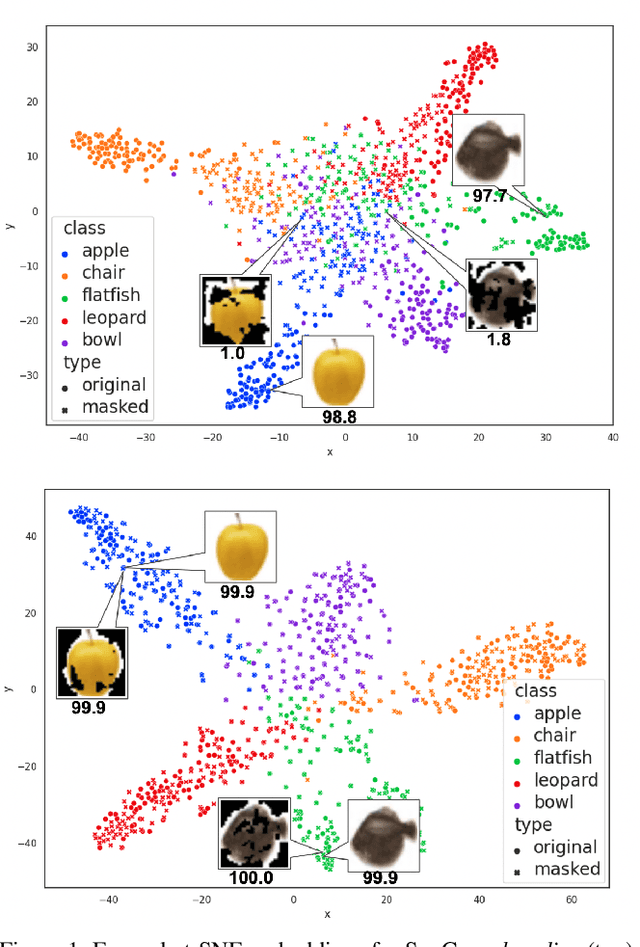
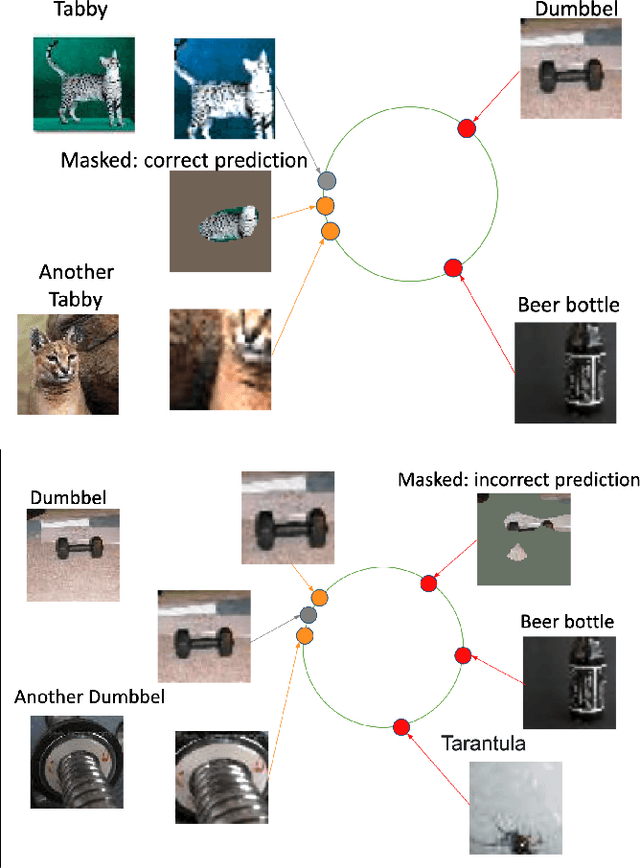
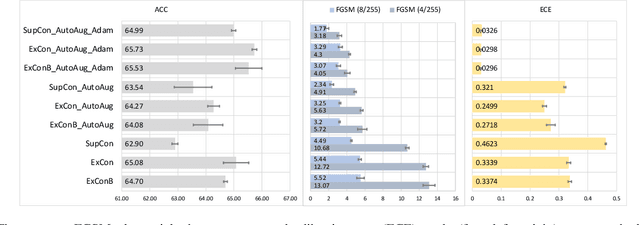
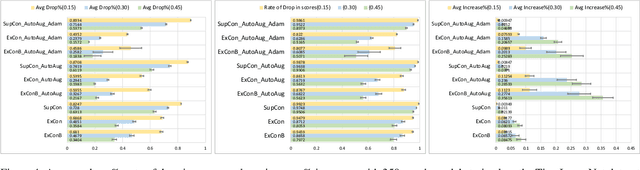
Contrastive learning has led to substantial improvements in the quality of learned embedding representations for tasks such as image classification. However, a key drawback of existing contrastive augmentation methods is that they may lead to the modification of the image content which can yield undesired alterations of its semantics. This can affect the performance of the model on downstream tasks. Hence, in this paper, we ask whether we can augment image data in contrastive learning such that the task-relevant semantic content of an image is preserved. For this purpose, we propose to leverage saliency-based explanation methods to create content-preserving masked augmentations for contrastive learning. Our novel explanation-driven supervised contrastive learning (ExCon) methodology critically serves the dual goals of encouraging nearby image embeddings to have similar content and explanation. To quantify the impact of ExCon, we conduct experiments on the CIFAR-100 and the Tiny ImageNet datasets. We demonstrate that ExCon outperforms vanilla supervised contrastive learning in terms of classification, explanation quality, adversarial robustness as well as calibration of probabilistic predictions of the model in the context of distributional shift.