 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccessor Feature Sets: Generalizing Successor Representations Across Policies
Mar 15, 2021Successor-style representations have many advantages for reinforcement learning: for example, they can help an agent generalize from past experience to new goals, and they have been proposed as explanations of behavioral and neural data from human and animal learners. They also form a natural bridge between model-based and model-free RL methods: like the former they make predictions about future experiences, and like the latter they allow efficient prediction of total discounted rewards. However, successor-style representations are not optimized to generalize across policies: typically, we maintain a limited-length list of policies, and share information among them by representation learning or GPI. Successor-style representations also typically make no provision for gathering information or reasoning about latent variables. To address these limitations, we bring together ideas from predictive state representations, belief space value iteration, successor features, and convex analysis: we develop a new, general successor-style representation, together with a Bellman equation that connects multiple sources of information within this representation, including different latent states, policies, and reward functions. The new representation is highly expressive: for example, it lets us efficiently read off an optimal policy for a new reward function, or a policy that imitates a new demonstration. For this paper, we focus on exact computation of the new representation in small, known environments, since even this restricted setting offers plenty of interesting questions. Our implementation does not scale to large, unknown environments -- nor would we expect it to, since it generalizes POMDP value iteration, which is difficult to scale. However, we believe that future work will allow us to extend our ideas to approximate reasoning in large, unknown environments.
Rapid Adaptation with Conditionally Shifted Neurons
Jul 03, 2018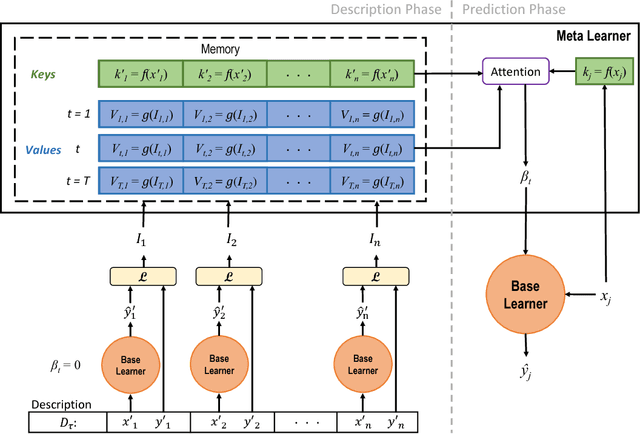

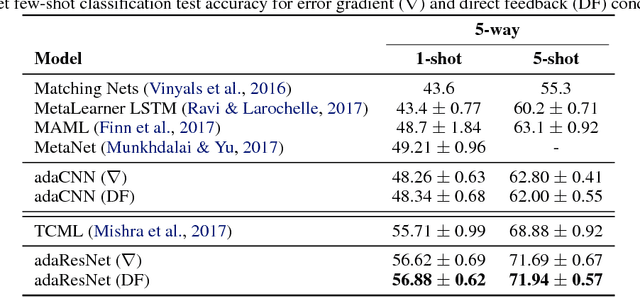
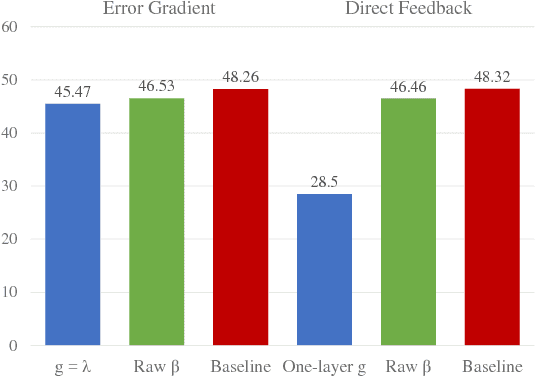
We describe a mechanism by which artificial neural networks can learn rapid adaptation - the ability to adapt on the fly, with little data, to new tasks - that we call conditionally shifted neurons. We apply this mechanism in the framework of metalearning, where the aim is to replicate some of the flexibility of human learning in machines. Conditionally shifted neurons modify their activation values with task-specific shifts retrieved from a memory module, which is populated rapidly based on limited task experience. On metalearning benchmarks from the vision and language domains, models augmented with conditionally shifted neurons achieve state-of-the-art results.
Deep Complex Networks
Feb 25, 2018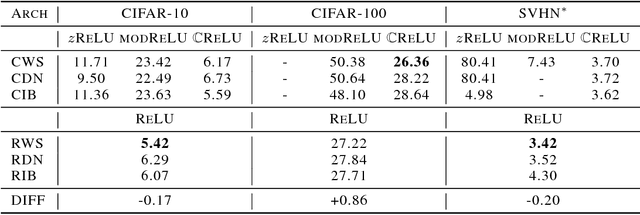
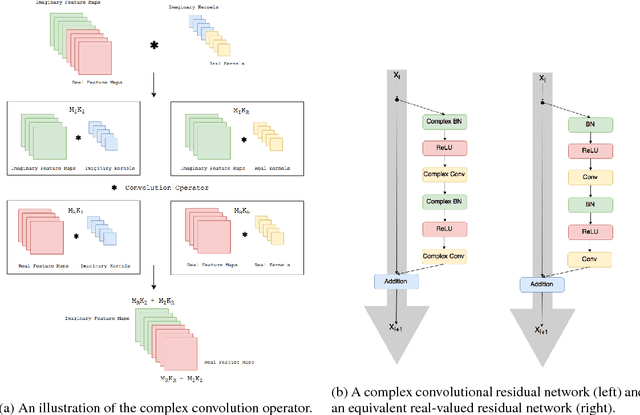

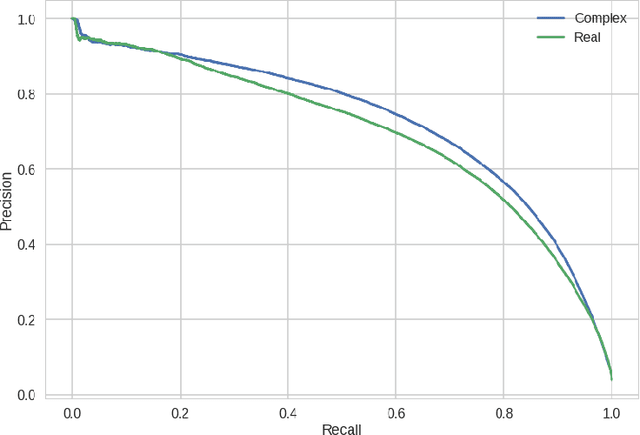
At present, the vast majority of building blocks, techniques, and architectures for deep learning are based on real-valued operations and representations. However, recent work on recurrent neural networks and older fundamental theoretical analysis suggests that complex numbers could have a richer representational capacity and could also facilitate noise-robust memory retrieval mechanisms. Despite their attractive properties and potential for opening up entirely new neural architectures, complex-valued deep neural networks have been marginalized due to the absence of the building blocks required to design such models. In this work, we provide the key atomic components for complex-valued deep neural networks and apply them to convolutional feed-forward networks and convolutional LSTMs. More precisely, we rely on complex convolutions and present algorithms for complex batch-normalization, complex weight initialization strategies for complex-valued neural nets and we use them in experiments with end-to-end training schemes. We demonstrate that such complex-valued models are competitive with their real-valued counterparts. We test deep complex models on several computer vision tasks, on music transcription using the MusicNet dataset and on Speech Spectrum Prediction using the TIMIT dataset. We achieve state-of-the-art performance on these audio-related tasks.
SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
Feb 11, 2017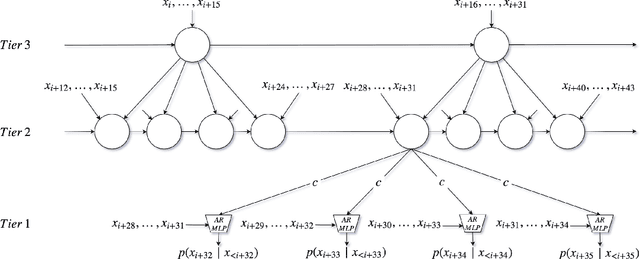

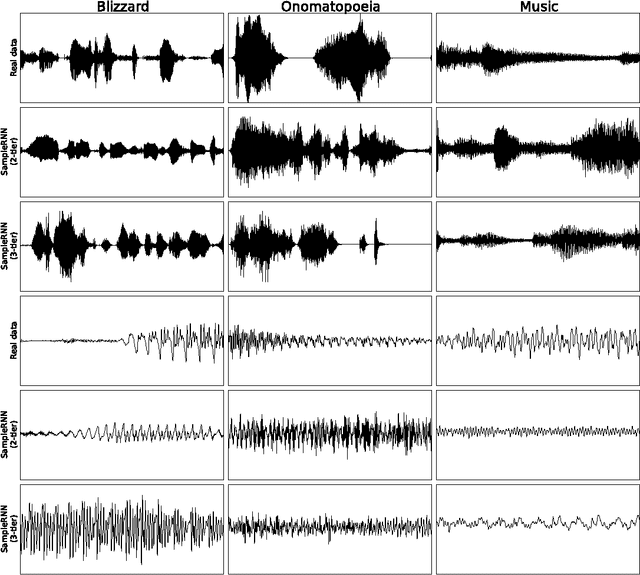
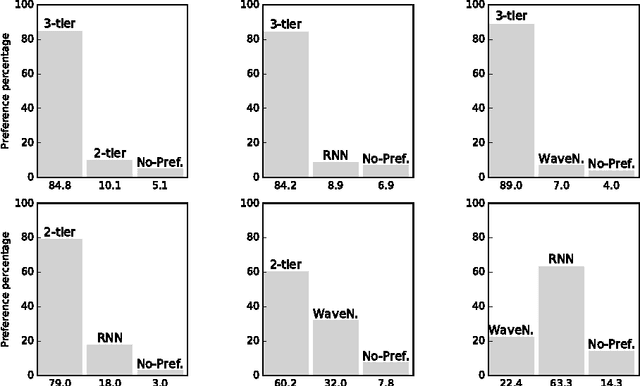
In this paper we propose a novel model for unconditional audio generation based on generating one audio sample at a time. We show that our model, which profits from combining memory-less modules, namely autoregressive multilayer perceptrons, and stateful recurrent neural networks in a hierarchical structure is able to capture underlying sources of variations in the temporal sequences over very long time spans, on three datasets of different nature. Human evaluation on the generated samples indicate that our model is preferred over competing models. We also show how each component of the model contributes to the exhibited performance.
On Binary Classification with Single-Layer Convolutional Neural Networks
Sep 13, 2015
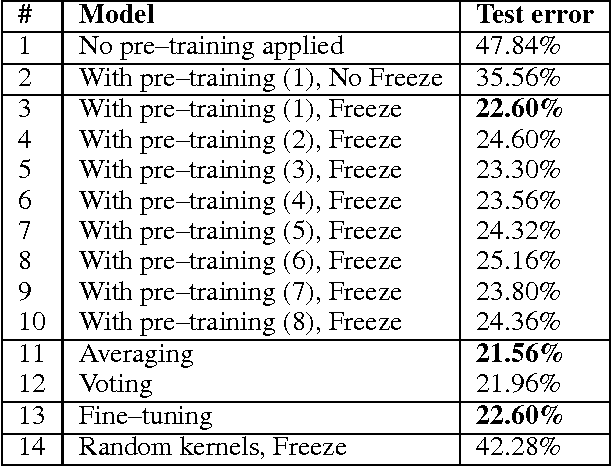


Convolutional neural networks are becoming standard tools for solving object recognition and visual tasks. However, most of the design and implementation of these complex models are based on trail-and-error. In this report, the main focus is to consider some of the important factors in designing convolutional networks to perform better. Specifically, classification with wide single-layer networks with large kernels as a general framework is considered. Particularly, we will show that pre-training using unsupervised schemes is vital, reasonable regularization is beneficial and applying of strong regularizers like dropout could be devastating. Pool size is also could be as important as learning procedure itself. In addition, it has been presented that using such a simple and relatively fast model for classifying cats and dogs, performance is close to state-of-the-art achievable by a combination of SVM models on color and texture features.