 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything Model (SAM) Enhanced Pseudo Labels for Weakly Supervised Semantic Segmentation
May 09, 2023



Weakly Supervised Semantic Segmentation (WSSS) with only image-level supervision has garnered increasing attention due to its low annotation cost compared to pixel-level annotation. Most existing methods rely on Class Activation Maps (CAM) to generate pixel-level pseudo labels for supervised training. However, it is well known that CAM often suffers from partial activation -- activating the most discriminative part instead of the entire object area, and false activation -- unnecessarily activating the background around the object. In this study, we introduce a simple yet effective approach to address these limitations by harnessing the recently released Segment Anything Model (SAM) to generate higher-quality pseudo labels with CAM. SAM is a segmentation foundation model that demonstrates strong zero-shot ability in partitioning images into segments but lacks semantic labels for these regions. To circumvent this, we employ pseudo labels for a specific class as the signal to select the most relevant masks and label them to generate the refined pseudo labels for this class. The segments generated by SAM are highly precise, leading to substantial improvements in partial and false activation. Moreover, existing post-processing modules for producing pseudo labels, such as AffinityNet, are often computationally heavy, with a significantly long training time. Surprisingly, we discovered that using the initial CAM with SAM can achieve on-par performance as the post-processed pseudo label generated from these modules with much less computational cost. Our approach is highly versatile and capable of seamless integration into existing WSSS models without modification to base networks or pipelines. Despite its simplicity, our approach improves the mean Intersection over Union (mIoU) of pseudo labels from five state-of-the-art WSSS methods by 6.2\% on average on the PASCAL VOC 2012 dataset.
Large-Margin Determinantal Point Processes
Nov 07, 2014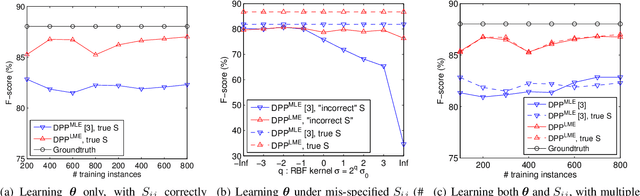


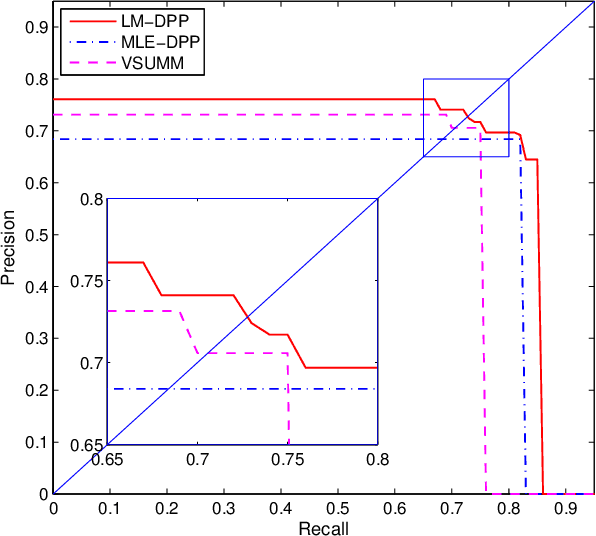
Determinantal point processes (DPPs) offer a powerful approach to modeling diversity in many applications where the goal is to select a diverse subset. We study the problem of learning the parameters (the kernel matrix) of a DPP from labeled training data. We make two contributions. First, we show how to reparameterize a DPP's kernel matrix with multiple kernel functions, thus enhancing modeling flexibility. Second, we propose a novel parameter estimation technique based on the principle of large margin separation. In contrast to the state-of-the-art method of maximum likelihood estimation, our large-margin loss function explicitly models errors in selecting the target subsets, and it can be customized to trade off different types of errors (precision vs. recall). Extensive empirical studies validate our contributions, including applications on challenging document and video summarization, where flexibility in modeling the kernel matrix and balancing different errors is indispensable.