 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Continual Learning in Image Classification: An Empirical Survey
Jan 25, 2021

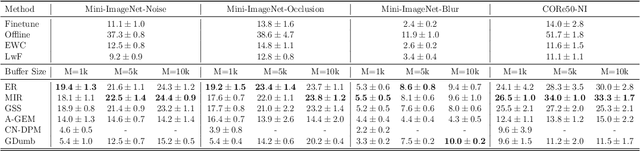
Online continual learning for image classification studies the problem of learning to classify images from an online stream of data and tasks, where tasks may include new classes (class incremental) or data nonstationarity (domain incremental). One of the key challenges of continual learning is to avoid catastrophic forgetting (CF), i.e., forgetting old tasks in the presence of more recent tasks. Over the past few years, many methods and tricks have been introduced to address this problem, but many have not been fairly and systematically compared under a variety of realistic and practical settings. To better understand the relative advantages of various approaches and the settings where they work best, this survey aims to (1) compare state-of-the-art methods such as MIR, iCARL, and GDumb and determine which works best at different experimental settings; (2) determine if the best class incremental methods are also competitive in domain incremental setting; (3) evaluate the performance of 7 simple but effective trick such as "review" trick and nearest class mean (NCM) classifier to assess their relative impact. Regarding (1), we observe earlier proposed iCaRL remains competitive when the memory buffer is small; GDumb outperforms many recently proposed methods in medium-size datasets and MIR performs the best in larger-scale datasets. For (2), we note that GDumb performs quite poorly while MIR -- already competitive for (1) -- is also strongly competitive in this very different but important setting. Overall, this allows us to conclude that MIR is overall a strong and versatile method across a wide variety of settings. For (3), we find that all 7 tricks are beneficial, and when augmented with the "review" trick and NCM classifier, MIR produces performance levels that bring online continual learning much closer to its ultimate goal of matching offline training.