 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable User Simulation
May 12, 2026Using offline datasets to evaluate conversational agents often fails to cover rare scenarios or to support testing new policies. This has motivated the use of controllable user simulators for targeted, counterfactual evaluation, typically implemented by prompting or fine-tuning large language models. In this work, we formalize controllable simulation as a causal inference problem. By bridging natural language evaluation with off-policy evaluation methodology, we show that the standard practice of training simulators via supervised fine-tuning on post-hoc trajectory labels yields a structurally biased model. Specifically, these labels are inextricably coupled to the data-generating behavior policy, injecting a look-ahead bias that breaks causal consistency. Furthermore, we prove that under policy shift this failure causes the variance of evaluation metrics to explode geometrically, a phenomenon we term controllability collapse. To restore causal consistency, we establish theoretical conditions for accurate simulation and propose practical training mitigations: a priori controls, step-wise dynamic controls, and direct policy-conditioned learning. Empirical evaluation confirms that while standard global controls distort conversational distributions and collapse behavioral diversity, our causally grounded simulators eliminate look-ahead bias, preserve natural variance, and exhibit robust zero-shot generalization to unseen agent behaviors.
ConvApparel: A Benchmark Dataset and Validation Framework for User Simulators in Conversational Recommenders
Feb 18, 2026The promise of LLM-based user simulators to improve conversational AI is hindered by a critical "realism gap," leading to systems that are optimized for simulated interactions, but may fail to perform well in the real world. We introduce ConvApparel, a new dataset of human-AI conversations designed to address this gap. Its unique dual-agent data collection protocol -- using both "good" and "bad" recommenders -- enables counterfactual validation by capturing a wide spectrum of user experiences, enriched with first-person annotations of user satisfaction. We propose a comprehensive validation framework that combines statistical alignment, a human-likeness score, and counterfactual validation to test for generalization. Our experiments reveal a significant realism gap across all simulators. However, the framework also shows that data-driven simulators outperform a prompted baseline, particularly in counterfactual validation where they adapt more realistically to unseen behaviors, suggesting they embody more robust, if imperfect, user models.
Reflect-then-Plan: Offline Model-Based Planning through a Doubly Bayesian Lens
Jun 06, 2025Offline reinforcement learning (RL) is crucial when online exploration is costly or unsafe but often struggles with high epistemic uncertainty due to limited data. Existing methods rely on fixed conservative policies, restricting adaptivity and generalization. To address this, we propose Reflect-then-Plan (RefPlan), a novel doubly Bayesian offline model-based (MB) planning approach. RefPlan unifies uncertainty modeling and MB planning by recasting planning as Bayesian posterior estimation. At deployment, it updates a belief over environment dynamics using real-time observations, incorporating uncertainty into MB planning via marginalization. Empirical results on standard benchmarks show that RefPlan significantly improves the performance of conservative offline RL policies. In particular, RefPlan maintains robust performance under high epistemic uncertainty and limited data, while demonstrating resilience to changing environment dynamics, improving the flexibility, generalizability, and robustness of offline-learned policies.
Factual and Personalized Recommendations using Language Models and Reinforcement Learning
Oct 09, 2023



Recommender systems (RSs) play a central role in connecting users to content, products, and services, matching candidate items to users based on their preferences. While traditional RSs rely on implicit user feedback signals, conversational RSs interact with users in natural language. In this work, we develop a comPelling, Precise, Personalized, Preference-relevant language model (P4LM) that recommends items to users while putting emphasis on explaining item characteristics and their relevance. P4LM uses the embedding space representation of a user's preferences to generate compelling responses that are factually-grounded and relevant w.r.t. the user's preferences. Moreover, we develop a joint reward function that measures precision, appeal, and personalization, which we use as AI-based feedback in a reinforcement learning-based language model framework. Using the MovieLens 25M dataset, we demonstrate that P4LM delivers compelling, personalized movie narratives to users.
Demystifying Embedding Spaces using Large Language Models
Oct 06, 2023Embeddings have become a pivotal means to represent complex, multi-faceted information about entities, concepts, and relationships in a condensed and useful format. Nevertheless, they often preclude direct interpretation. While downstream tasks make use of these compressed representations, meaningful interpretation usually requires visualization using dimensionality reduction or specialized machine learning interpretability methods. This paper addresses the challenge of making such embeddings more interpretable and broadly useful, by employing Large Language Models (LLMs) to directly interact with embeddings -- transforming abstract vectors into understandable narratives. By injecting embeddings into LLMs, we enable querying and exploration of complex embedding data. We demonstrate our approach on a variety of diverse tasks, including: enhancing concept activation vectors (CAVs), communicating novel embedded entities, and decoding user preferences in recommender systems. Our work couples the immense information potential of embeddings with the interpretative power of LLMs.
Conservative Bayesian Model-Based Value Expansion for Offline Policy Optimization
Oct 07, 2022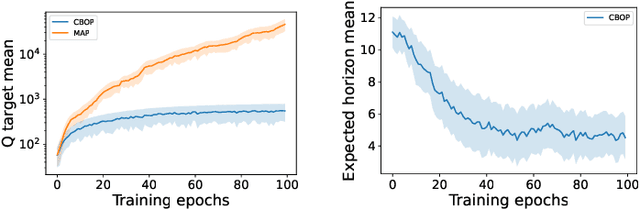
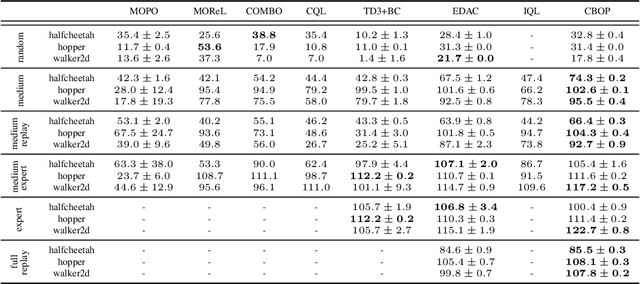
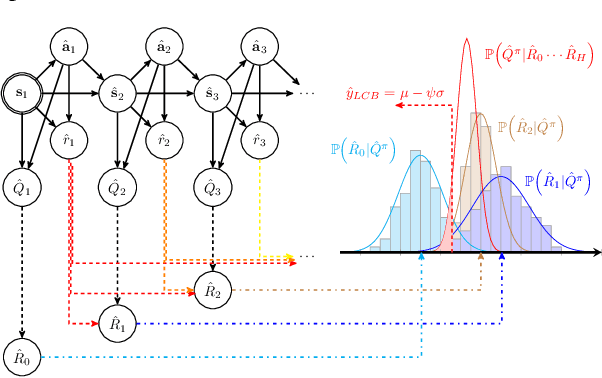
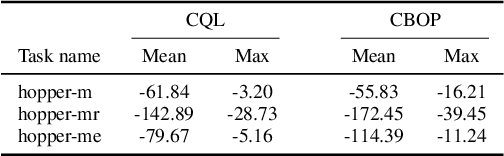
Offline reinforcement learning (RL) addresses the problem of learning a performant policy from a fixed batch of data collected by following some behavior policy. Model-based approaches are particularly appealing in the offline setting since they can extract more learning signals from the logged dataset by learning a model of the environment. However, the performance of existing model-based approaches falls short of model-free counterparts, due to the compounding of estimation errors in the learned model. Driven by this observation, we argue that it is critical for a model-based method to understand when to trust the model and when to rely on model-free estimates, and how to act conservatively w.r.t. both. To this end, we derive an elegant and simple methodology called conservative Bayesian model-based value expansion for offline policy optimization (CBOP), that trades off model-free and model-based estimates during the policy evaluation step according to their epistemic uncertainties, and facilitates conservatism by taking a lower bound on the Bayesian posterior value estimate. On the standard D4RL continuous control tasks, we find that our method significantly outperforms previous model-based approaches: e.g., MOPO by $116.4$%, MOReL by $23.2$% and COMBO by $23.7$%. Further, CBOP achieves state-of-the-art performance on $11$ out of $18$ benchmark datasets while doing on par on the remaining datasets.
RAPTOR: End-to-end Risk-Aware MDP Planning and Policy Learning by Backpropagation
Jun 14, 2021

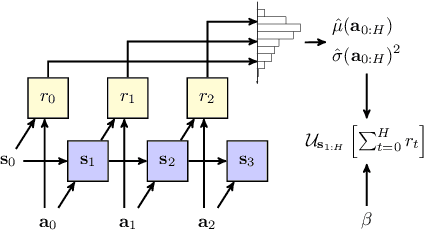

Planning provides a framework for optimizing sequential decisions in complex environments. Recent advances in efficient planning in deterministic or stochastic high-dimensional domains with continuous action spaces leverage backpropagation through a model of the environment to directly optimize actions. However, existing methods typically not take risk into account when optimizing in stochastic domains, which can be incorporated efficiently in MDPs by optimizing the entropic utility of returns. We bridge this gap by introducing Risk-Aware Planning using PyTorch (RAPTOR), a novel framework for risk-sensitive planning through end-to-end optimization of the entropic utility objective. A key technical difficulty of our approach lies in that direct optimization of the entropic utility by backpropagation is impossible due to the presence of environment stochasticity. The novelty of RAPTOR lies in the reparameterization of the state distribution, which makes it possible to apply stochastic backpropagatation through sufficient statistics of the entropic utility computed from forward-sampled trajectories. The direct optimization of this empirical objective in an end-to-end manner is called the risk-averse straight-line plan, which commits to a sequence of actions in advance and can be sub-optimal in highly stochastic domains. We address this shortcoming by optimizing for risk-aware Deep Reactive Policies (RaDRP) in our framework. We evaluate and compare these two forms of RAPTOR on three highly stochastic do-mains, including nonlinear navigation, HVAC control, and linear reservoir control, demonstrating the ability to manage risk in complex MDPs.
Online Continual Learning in Image Classification: An Empirical Survey
Jan 25, 2021
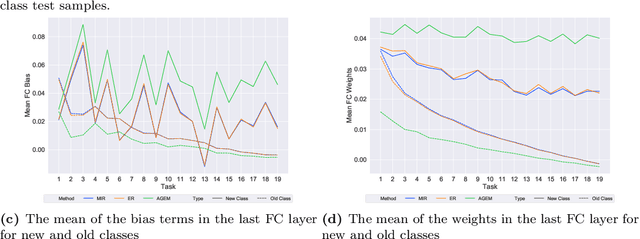

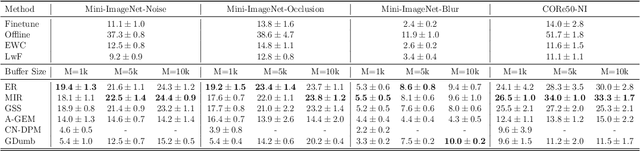
Online continual learning for image classification studies the problem of learning to classify images from an online stream of data and tasks, where tasks may include new classes (class incremental) or data nonstationarity (domain incremental). One of the key challenges of continual learning is to avoid catastrophic forgetting (CF), i.e., forgetting old tasks in the presence of more recent tasks. Over the past few years, many methods and tricks have been introduced to address this problem, but many have not been fairly and systematically compared under a variety of realistic and practical settings. To better understand the relative advantages of various approaches and the settings where they work best, this survey aims to (1) compare state-of-the-art methods such as MIR, iCARL, and GDumb and determine which works best at different experimental settings; (2) determine if the best class incremental methods are also competitive in domain incremental setting; (3) evaluate the performance of 7 simple but effective trick such as "review" trick and nearest class mean (NCM) classifier to assess their relative impact. Regarding (1), we observe earlier proposed iCaRL remains competitive when the memory buffer is small; GDumb outperforms many recently proposed methods in medium-size datasets and MIR performs the best in larger-scale datasets. For (2), we note that GDumb performs quite poorly while MIR -- already competitive for (1) -- is also strongly competitive in this very different but important setting. Overall, this allows us to conclude that MIR is overall a strong and versatile method across a wide variety of settings. For (3), we find that all 7 tricks are beneficial, and when augmented with the "review" trick and NCM classifier, MIR produces performance levels that bring online continual learning much closer to its ultimate goal of matching offline training.
Adversarial Shapley Value Experience Replay for Task-Free Continual Learning
Aug 31, 2020
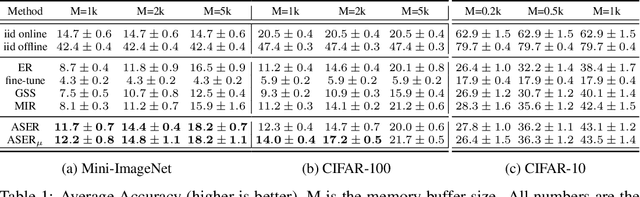
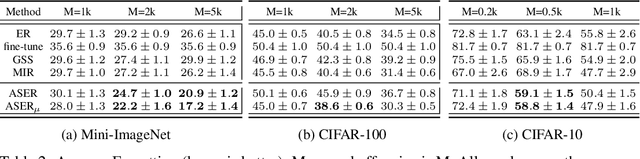
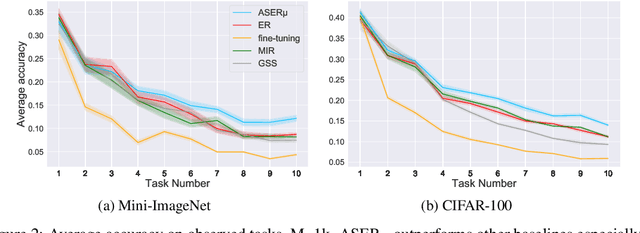
Continual learning is a branch of deep learning that seeks to strike a balance between learning stability and plasticity. In this paper, we specifically focus on the task-free setting where data are streamed online without task metadata and clear task boundaries. A simple and highly effective algorithm class for this setting is known as Experience Replay (ER) that selectively stores data samples from previous experience and leverages them to interleave memory-based and online batch learning updates. Recent advances in ER have proposed novel methods for scoring which samples to store in memory and which memory samples to interleave with online data during learning updates. In this paper, we contribute a novel Adversarial Shapley value ER (ASER) method that scores memory data samples according to their ability to preserve latent decision boundaries for previously observed classes (to maintain learning stability and avoid forgetting) while interfering with latent decision boundaries of current classes being learned (to encourage plasticity and optimal learning of new class boundaries). Overall, we observe that ASER provides competitive or improved performance on a variety of datasets compared to state-of-the-art ER-based continual learning methods.
Batch-level Experience Replay with Review for Continual Learning
Jul 11, 2020



Continual learning is a branch of deep learning that seeks to strike a balance between learning stability and plasticity. The CVPR 2020 CLVision Continual Learning for Computer Vision challenge is dedicated to evaluating and advancing the current state-of-the-art continual learning methods using the CORe50 dataset with three different continual learning scenarios. This paper presents our approach, called Batch-level Experience Replay with Review, to this challenge. Our team achieved the 1'st place in all three scenarios out of 79 participated teams. The codebase of our implementation is publicly available at https://github.com/RaptorMai/CVPR20_CLVision_challenge