 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynapse: Learning Preferential Concepts from Visual Demonstrations
Mar 25, 2024This paper addresses the problem of preference learning, which aims to learn user-specific preferences (e.g., "good parking spot", "convenient drop-off location") from visual input. Despite its similarity to learning factual concepts (e.g., "red cube"), preference learning is a fundamentally harder problem due to its subjective nature and the paucity of person-specific training data. We address this problem using a new framework called Synapse, which is a neuro-symbolic approach designed to efficiently learn preferential concepts from limited demonstrations. Synapse represents preferences as neuro-symbolic programs in a domain-specific language (DSL) that operates over images, and leverages a novel combination of visual parsing, large language models, and program synthesis to learn programs representing individual preferences. We evaluate Synapse through extensive experimentation including a user case study focusing on mobility-related concepts in mobile robotics and autonomous driving. Our evaluation demonstrates that Synapse significantly outperforms existing baselines as well as its own ablations. The code and other details can be found on the project website https://amrl.cs.utexas.edu/synapse .
Program Synthesis for Robot Learning from Demonstrations
May 04, 2023



This paper presents a new synthesis-based approach for solving the Learning from Demonstration (LfD) problem in robotics. Given a set of user demonstrations, the goal of programmatic LfD is to learn a policy in a programming language that can be used to control a robot's behavior. We address this problem through a novel program synthesis algorithm that leverages two key ideas: First, to perform fast and effective generalization from user demonstrations, our synthesis algorithm views these demonstrations as strings over a finite alphabet and abstracts programs in our DSL as regular expressions over the same alphabet. This regex abstraction facilitates synthesis by helping infer useful program sketches and pruning infeasible parts of the search space. Second, to deal with the large number of object types in the environment, our method leverages a Large Language Model (LLM) to guide search. We have implemented our approach in a tool called Prolex and present the results of a comprehensive experimental evaluation on 120 benchmarks involving 40 unique tasks in three different environments. We show that, given a 120 second time limit, Prolex can find a program consistent with the demonstrations in 80% of the cases. Furthermore, for 81% of the tasks for which a solution is returned, Prolex is able to find the ground truth program with just one demonstration. To put these results in perspective, we conduct a comparison against two baselines and show that both perform much worse.
RAPTOR: End-to-end Risk-Aware MDP Planning and Policy Learning by Backpropagation
Jun 14, 2021

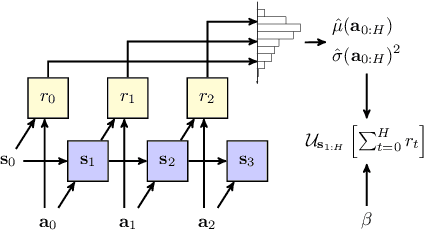

Planning provides a framework for optimizing sequential decisions in complex environments. Recent advances in efficient planning in deterministic or stochastic high-dimensional domains with continuous action spaces leverage backpropagation through a model of the environment to directly optimize actions. However, existing methods typically not take risk into account when optimizing in stochastic domains, which can be incorporated efficiently in MDPs by optimizing the entropic utility of returns. We bridge this gap by introducing Risk-Aware Planning using PyTorch (RAPTOR), a novel framework for risk-sensitive planning through end-to-end optimization of the entropic utility objective. A key technical difficulty of our approach lies in that direct optimization of the entropic utility by backpropagation is impossible due to the presence of environment stochasticity. The novelty of RAPTOR lies in the reparameterization of the state distribution, which makes it possible to apply stochastic backpropagatation through sufficient statistics of the entropic utility computed from forward-sampled trajectories. The direct optimization of this empirical objective in an end-to-end manner is called the risk-averse straight-line plan, which commits to a sequence of actions in advance and can be sub-optimal in highly stochastic domains. We address this shortcoming by optimizing for risk-aware Deep Reactive Policies (RaDRP) in our framework. We evaluate and compare these two forms of RAPTOR on three highly stochastic do-mains, including nonlinear navigation, HVAC control, and linear reservoir control, demonstrating the ability to manage risk in complex MDPs.